
Monitoritzant el SLA dels Hosts a Centreon

Aquest document el farem servir per conèixer el % de disponibilitat de les màquines monitoritzades a Centreon. Si disposem d'algun SLA (Acord de Nivell de Servei) complir, podrem mesurar-ho des de Centreon així com alertar-nos. Ah i si fas servir Grafana també ho veurem des d'aquí!
El que s'ha dit, Al final d'aquest post sabràs com mesurar el SLA que ofereix cada màquina que tinguis monitoritzada, hi associarem un Servei a cada Host de Centreon per conèixer la disponibilitat que ofereix aquesta màquina. Així tindràs també el seu històric i si t'interessés podries rebre alertes quan el % sigui menor del valor que t'interessi. I al final això, si utilitzeu Grafana per visualitzar la vostra monitorització de Centreon, us diré com visualitzo aquest dada, per si us aporta alguna cosa 🙂
Per cert, igual t'interessa, en aquest post vam veure alguna cosa similar, vam veure com obtenir el SLA dels Serveis de Centreon. Avui toca als Hosts.
Per poder mesurar el SLA necessitarem fer una consulta a la pròpia base de dades de Centreon, que està basada en MariaDB (o MySQL), així que si no el tens, abans necessites revisar aquest post per poder fer consultes a qualsevol BD de MySQL.
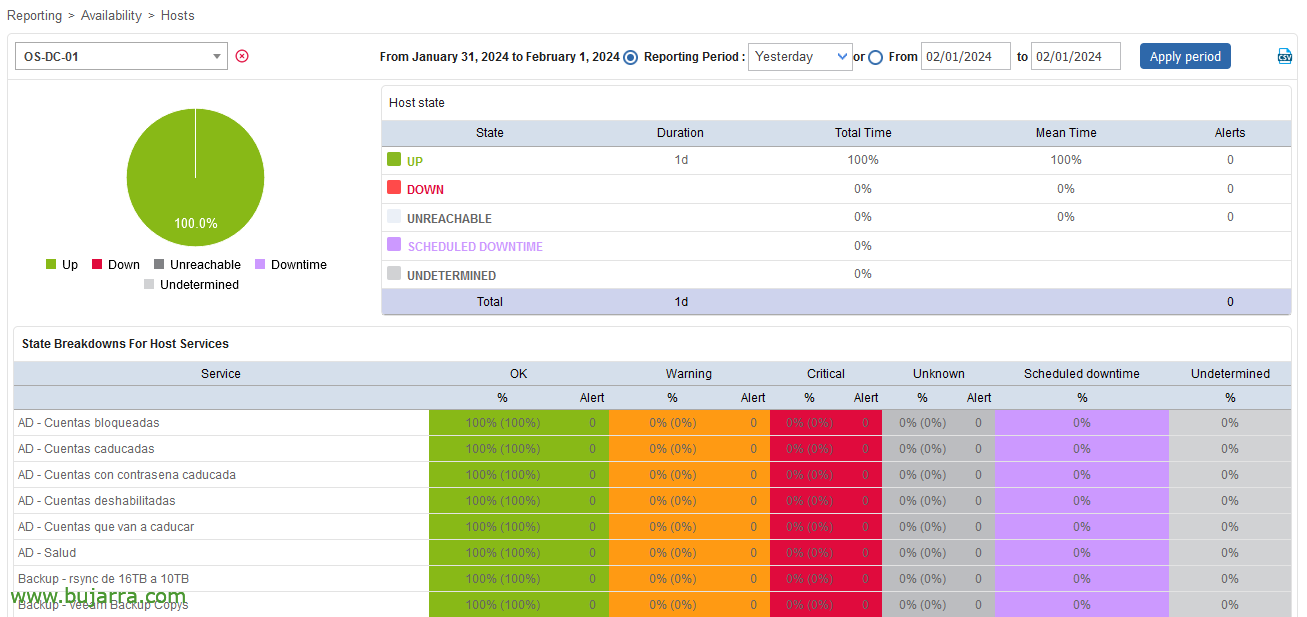
De tota manera, recorda que a Centreon el SLA es pot veure per GUI des de “Reporting” > “Disponibilitat” > “Hosts”. Nosaltres obtindrem aquests mateixos valors, però els monitoritzarem, això és l'important!

Comencem! Com sempre començarem pel Comandament, un cop definim aquest primer Comandament, el podrem usar tantes vegades com necessitem. En concret aquest comandament ens donarà el % que ha estat una màquina en estat OK, el % del temps que ha estat bé. Com a arguments porta (i) els dies que vols mirar enrere per calcular el SLA, 1 dia, 7 dies, 30 dies, 365 dies… (ii) el nom de la màquina, que realment ho podria haver agafat amb una variable de Centreon i no preguntar-ho, (iii) el valor que vols de Warning i (iv) el de Critical, perquè t'alerti, menys d'aquests valors seran considerats alerta. us deixo el Comando:
$CENTREONPLUGINS$/Nagios-Plugins/check_mysql_query.pl -q "SELECT ROUND((SUM(UPTimeScheduled)/($ARG1$ * 86400))*100,2) com a percentatge FROM hosts, log_archive_host WHERE log_archive_host.host_id = hosts.host_id AND hosts.name = '$ARG2$' AND from_unixtime(date_end) > date_sub(ara(), INTERVAL $ARG1$ dia) order BY date_end DESC" -H DIRECCION_IP_CENTREON_CENTRAL -d centreon_storage -u 'USUARIO_MYSQL' -p 'CONTRASEÑA_MYSQL' -t 60 --no-querytime -g -l 'SLA' -U % -w $ARG3$: -c $ARG4$: -m 'El SLA és del' -n
Si en comptes de % voleu veure el temps que ha estat engegada, podrem canviar la consulta per alguna cosa com això:
$CENTREONPLUGINS$/Nagios-Plugins/check_mysql_query.pl -q "SELECT CONCAT(FLOOR(HORA(sec_to_time(SUM(UPTimeScheduled))) / 24), 'd_', MOD(HORA(sec_to_time(SUM(UPTimeScheduled))), 24), 'h_', MINUTE(sec_to_time(SUM(UPTimeScheduled))), 'm') COM TEMPS FROM hosts, log_archive_host WHERE log_archive_host.host_id = hosts.host_id AND hosts.name = '$ARG2$' AND from_unixtime(date_end) > date_sub(ara(), INTERVAL $ARG1$ dia) order BY date_end DESC" -H DIRECCION_IP_CENTREON_CENTRAL -d centreon_storage -u 'USUARIO_MYSQL' -p 'CONTRASEÑA_MYSQL' -t 60 --no-querytime -T -g -l 'SLA'
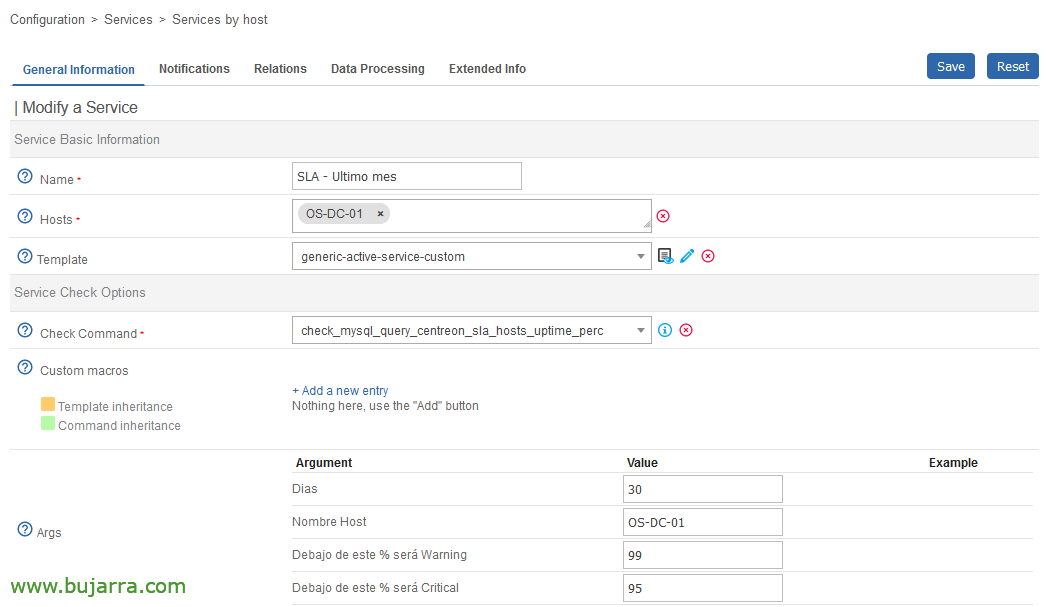
Un cop creat el Comando, ja podríem crear tants Serveis com necessitem i associar-los als nostres Hosts, aquest exemple ens mostrarà el SLA de l'últim mes d'aquesta màquina, ens donarà un Warning quan el SLA sigui menor que 99% i llençarà un missatge de Critical quan sigui menor que 95%.
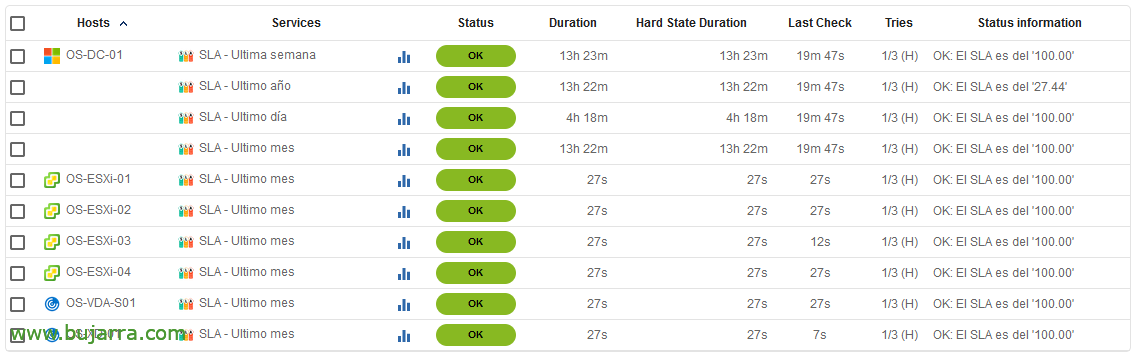
Després de gravar i exportar la configuració de Centreon, ja podrem veure els resultats. En un momentet podem arribar a controlar el SLA de cada equip, mesurar-ho i millorar-ho, o utilitzar-ho quan ens ho sol·licitin. Tingueu en compte que aquest script no s'ha d'executar abans de les 6 del matí ja que Centreon internament a la BBDD no ha generat les dades d'aquell dia i ens pot donar la informació una mica falsejada, així que el millor és establir-li una programació particular.
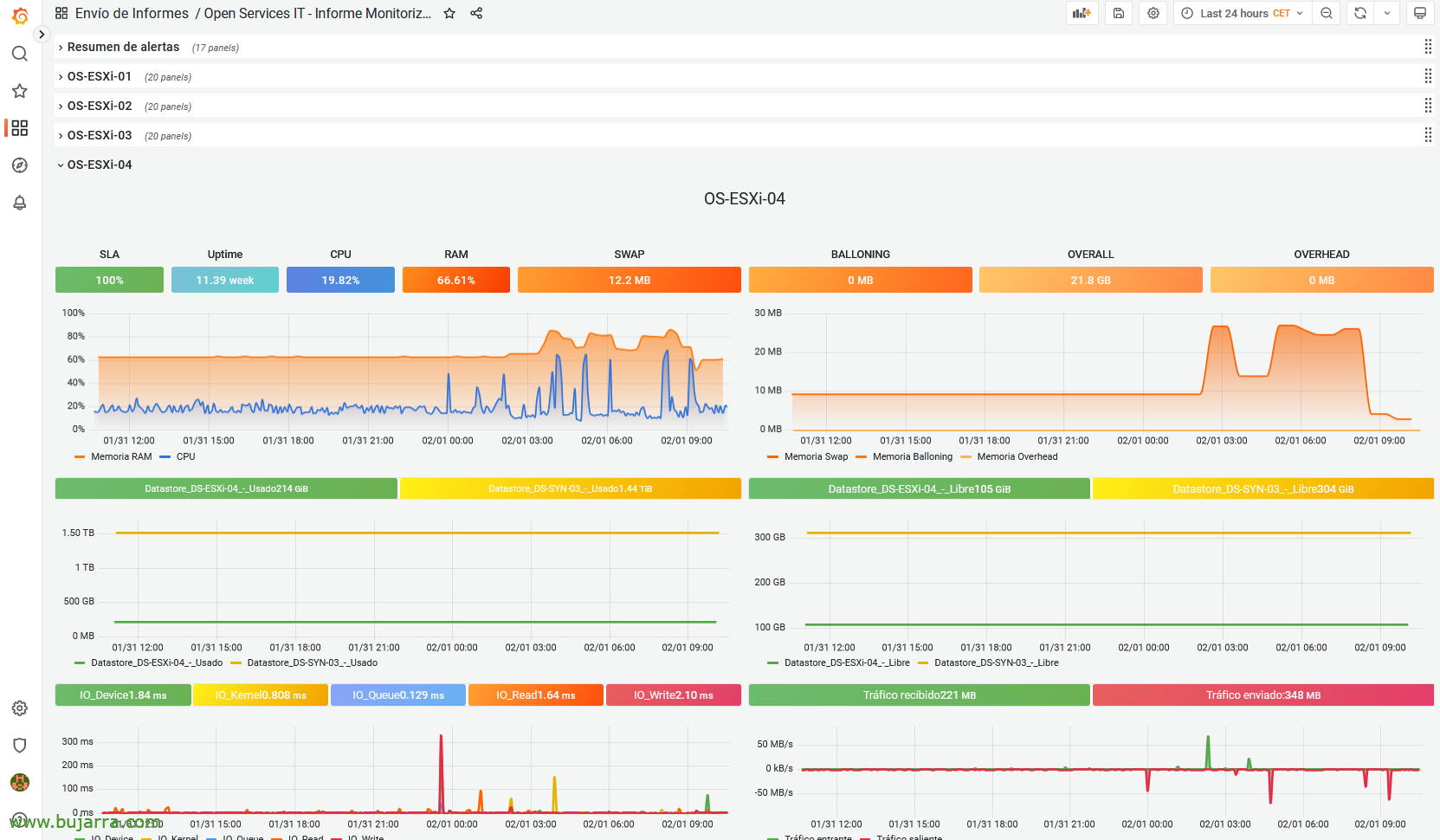
I si teniu Grafana i veieu dades de monitorització, podem calcular el SLA en funció del període de temps del gràfic, per a això, si us fixeu, hi ha un panell on es veu el SLA.
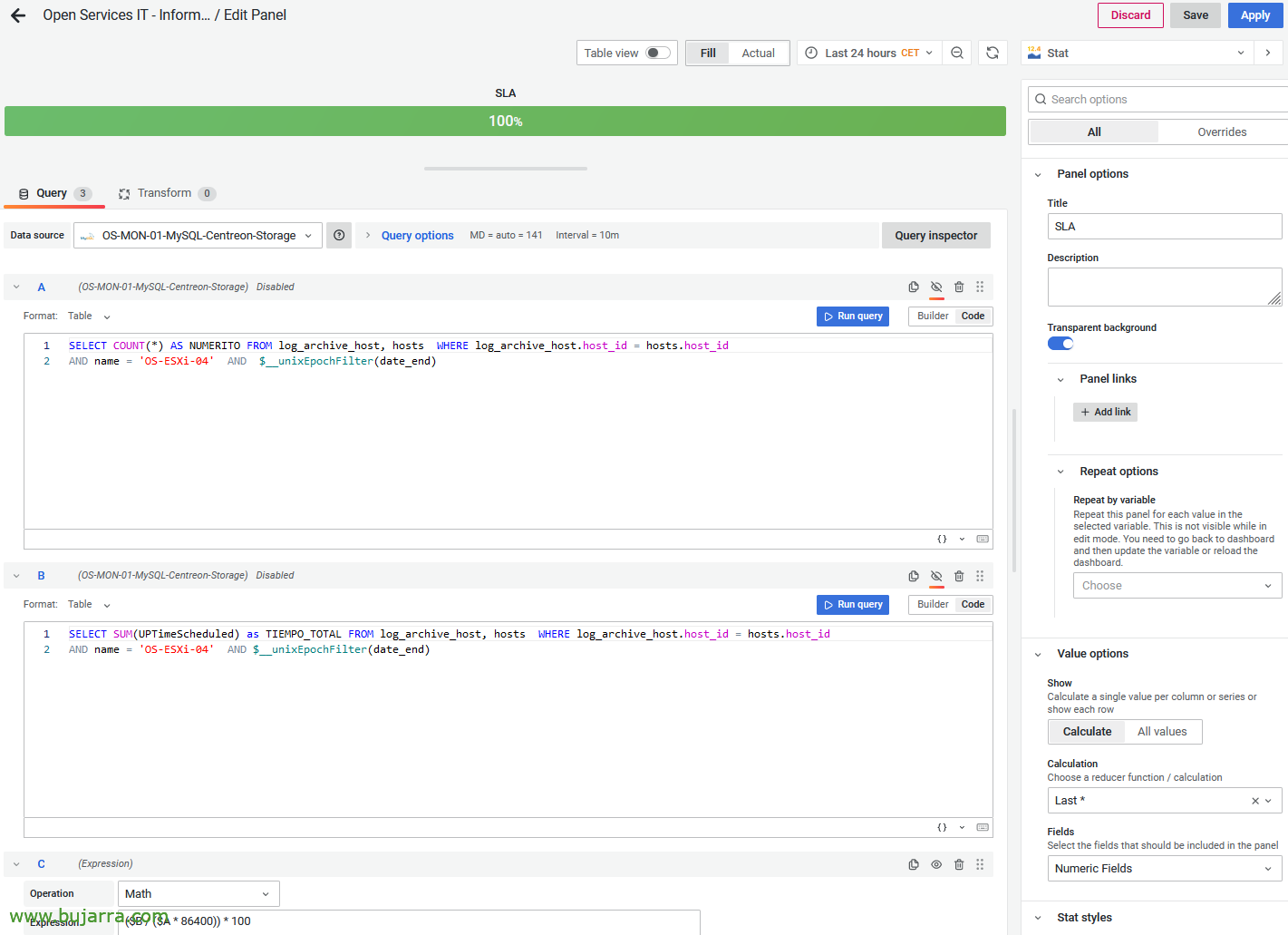
Si editem el panell de tipus 'estadística',, calculo el SLA obtenint-ho de 2 consultes, la primera obtindrà els dies de la query (en funció del que es seleccioni a Grafana, 24h, 1 mes…); i la segona obté en segons quant temps ha estat l'equip en estat OK. Si us fixeu ambdues consultes estan ocultes, i hi ha una tercera consulta que és de tipus matemàtic i obté el % en funció d'aquests dos valors. us deixo les 2 consultes utilitzades:
SELECT COUNT(*) AS NUMERITO DE log_archive_host, hosts ON log_archive_host.host_id = hosts.host_id I nom = 'NOM_DE_HOST' I $__unixEpochFilter(date_end)
SELECT SUM(UPTimeScheduled) com TIEMPO_TOTAL DE log_archive_host, hosts ON log_archive_host.host_id = hosts.host_id I nom = 'NOM_DE_HOST' I $__unixEpochFilter(date_end)
($B / ($A * 86400)) * 100
Així podrem veure i demostrar el SLA que complim per a cada màquina que ofereix serveis a la nostra organització, us recordo que abans vaig posar un enllaç per mesurar el SLA dels serveis, que depenent del que necessitem seria l'altra opció.
Espero com sempre que vagi molt bé, que us cuideu i us envio una abraçada!










