

Olhama, Introdução à IA local

Por alguns meses, eu estava mexendo com uma IA local e de código aberto; E queria compartilhar com vocês um pouco em uma série de posts algumas de suas possibilidades no nosso dia a dia. Mas neste primeiro documento veremos como podemos configurá-lo e algumas noções básicas de suas possibilidades.
Primeiras coisas, Se quiser, direi para que uso hoje, caso possa servir de ideia; Por enquanto, exclusivamente para gerar texto, Ele pode ser pobre, Mas é um mundo muito amplo. Desde o recebimento de qualquer sistema de notificação ou alerta, O alerta torna você mais humano ou pode sugerir por onde começar sua resolução. Para enviar e-mails periódicos, E-mails enviados pela minha organização diariamente, Mensal… Bem, isso lhes dá outro toque, alimenta-os com certos dados e os torna muito reais. Também para o sistema de automação residencial, me permite ter conversas com o Lar, Isso me alerta, Usando a voz, Frases diferentes…
Por enquanto, Como eu disse, para gerar texto; Mas as possibilidades são muitas, como a conexão com bancos de dados e que nos permite fazer consultas com uma linguagem natural. Ou a possibilidade de se envolver em conversas e perguntas sobre um documento que enviamos à IA, ou uma imagem e que ele descreve o que vê… Ao longo do documento darei alguns exemplos simples para que algo agradável possa ser feito.

O segundo, Nada mau, Como isso é chamado… Como você pode imaginar, existem muitas opções e possibilidades, Eu vou falar com você sobre Olhama (Biblioteca de código aberto para modelos e aplicativos de IA). Ollama nos permitirá usar o LLM (Modelo de linguagem grande), Isso é, modelos de linguagem treinados para IA, eles podem ser de código aberto ou pagos, Talvez 100% offline ou não, a gosto. Obviamente, e dependendo do LLM que usamos, precisaremos de mais ou menos energia, Isso é, ter uma GPU para que as respostas sejam imediatas. Poderemos usar a API Ollama para fazer perguntas remotamente com outros sistemas, Muito, muito poderoso. E eu recomendo você Abrir WebUI como uma interface GUI para Ollama, portanto, com nosso navegador, teremos a interface que você espera para poder trabalhar confortavelmente com sua IA.
O que eu disse, precisaremos de uma GPU para ter o melhor desempenho possível, vai depender do LLM que usamos e do GB exigido por cada modelo, desta forma, as respostas serão imediatas. Quanto ao hardware compatível, é bastante extenso (NVIDIA, AMD, Maçã M1…), Deixo-vos Aqui está sua lista.
Vou separar o artigo em:
- Instalação rápida do Ollama e Open WebUI no Windows, Mac ou Linux
- Instalando Ollama e Open WebUI em um MV Linux no Proxmox com Docker
- Acesso via Open Web UI e introdução
- Reconhecimento de imagem
- Interagindo com documentos
- Vários
Instalação rápida do Ollama e Open WebUI no Windows, Mac ou Linux
Se você quer provar isso, E rápido agora, Esta é a opção, já que você poderá instalar o Ollama no seu Linux, Mac ou Windows, Caso você queira executá-lo localmente, com sua GPU. Iremos para o Site de download de Ollama, vamos selecionar nosso sistema operacional e baixá-lo para nós, Próximo, Próximo e instalado.
No Linux, faremos o download e instalaremos da seguinte forma:
curl -fsSL https://ollama.com/install.sh | Sh >>> Baixando ollama... ######################################################################## 100,0%##O#- # >>> Instalando o ollama em /usr/local/bin... >>> Criando usuário ollama... >>> Adicionando usuário ollama ao grupo de renderização... >>> Adicionando usuário ollama ao grupo de vídeo... >>> Adicionando o usuário atual ao grupo ollama... >>> Criando o serviço ollama systemd... >>> Habilitando e iniciando o serviço de ollama... Criado link simbólico /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service. >>> GPU NVIDIA instalada.
E podemos baixar diretamente um LLM e experimentá-lo se quisermos do shell:
Ollama Run Mistral Pulling Manifest Pulling E8A35B5937A5... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 4.1 GB puxando 43070e2d4e53... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 11 KB puxando e6836092461f... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 42 B puxando ed11eda7790d... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 30 B puxando f9b1e3196ecf... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 483 B verificando o manifesto de escrita do resumo sha256 removendo todas as camadas não utilizadas com sucesso >>> Olá, olá! Isso significa "Olá" em espanhol.
Se quisermos que ele responda às consultas da API, devemos editar o arquivo de serviço 'nano /etc/systemd/system/ollama.service ‘ Adicionando:
Meio Ambiente="OLLAMA_HOST=0.0.0.0:11434"
E nós recarregamos o serviço:
sudo systemctl daemon-reload sudo systemctl restart ollama
E se quisermos ter a GUI para gerenciar nossa IA a partir do navegador, teremos que configurar o Open WebUI, o mais rápido e conveniente em um contêiner Docker:
clone do git https://github.com/open-webui/open-webui.git CD open-webui / sudo Docker compose up -d

E podemos abrir o navegador atacando o IP da máquina na porta 3000tcp (Inadimplência).
Instalando Ollama e Open WebUI em um MV Linux no Proxmox com Docker
E esta parte eu te digo por quê… Minha ideia é ter uma máquina para IA centralizada, uma máquina para a qual diferentes sistemas podem apontar para fazer consultas diferentes, por isso, Deve ser uma máquina virtual (sobre o tema das vantagens, Alta disponibilidade, Backup, Instantâneos…), uma VM para a qual passamos a placa gráfica e tem a GPU para ela. Para isso, usaremos o Proxmox, (um dia conversamos sobre o suicídio da VMware) e a VM será um servidor Ubuntu 24.04. E enquanto estamos nisso,, nessa VM, ele executará Ollama e Open WebUI em contêineres do Docker.
Aqui estão os passos que segui para passar a placa gráfica no Proxmox, Não sei se são os mais corretos, mas funciona perfeitamente.
Depois de instalar o Proxmox 8.2, Configure-o minimamente, ter executado a pós-instalação do Proxmox VE dos scripts auxiliares do Proxmox VE, vamos dizer ao Proxmox para não usar esse PCIe Graphics, começamos a editar o GRUB com 'nano /etc/default/grub’ e modificamos a seguinte linha:
#GRUB_CMDLINE_LINUX_DEFAULT="quieto" GRUB_CMDLINE_LINUX_DEFAULT="quiet intel_iommu=on iommu=pt vfio_iommu_type1 initcall_blacklist=sysfb_init" INTELIGÊNCIA--> GRUB_CMDLINE_LINUX_DEFAULT="silencioso intel_iommu=ligado" AMD--> GRUB_CMDLINE_LINUX_DEFAULT="silencioso amd_iommu=ligado"
E nós executamos
update-grub
Adicionamos os seguintes módulos com 'nano /etc/modules':
Eu moro vfio_iommu_type1 vfio_pci vfio_virqfd
Bloqueamos os drivers com 'nano /etc/modprobe.d/blacklist.conf':
Lista negra Nouveau Lista negra NVIDIA Lista negra NVIDIA * Lista negra Radeon
Anotamos os IDs com: 'spci -n -s 01:00’, Como você pode ver, Se houver algum curioso, no meu caso é uma NVIDIA RTX 3060 12GB conectado ao PCIe 1.
01:00.0 0300: 10de:2504 (Rev A1) 01:00.1 0403: 10de:228e (Rev A1)
Editamos 'nano /etc/modprobe.d/vfio.conf’
Opções KVM ignore_msrs=1x Opções vfio-pci ids=10de:2504,10de:228e disable_vga = 1
Editamos 'nano /etc/modprobe.d/kvm.conf’
Opções de KVM ignore_msrs=1
E, finalmente, editamos 'nano /etc/modprobe.d/iommu_unsafe_interrupts.conf’
Opções vfio_iommu_type1 allow_unsafe_interrupts=1"
Estou lhe dizendo que tenho certeza de que terei uma etapa sobrando para a passagem da placa gráfica no Proxmox, mas depois de reiniciar o host, você verá como pode adicionar perfeitamente a GPU a uma VM.

O próximo passo, será criar a VM no Proxmox, Aqui estão algumas coisas que eu tinha em mente; na guia 'Sistema'’ Devemos indicar 'Q35’ como um tipo de máquina, e nas opções do BIOS escolha 'OVMF (UEFI)’,
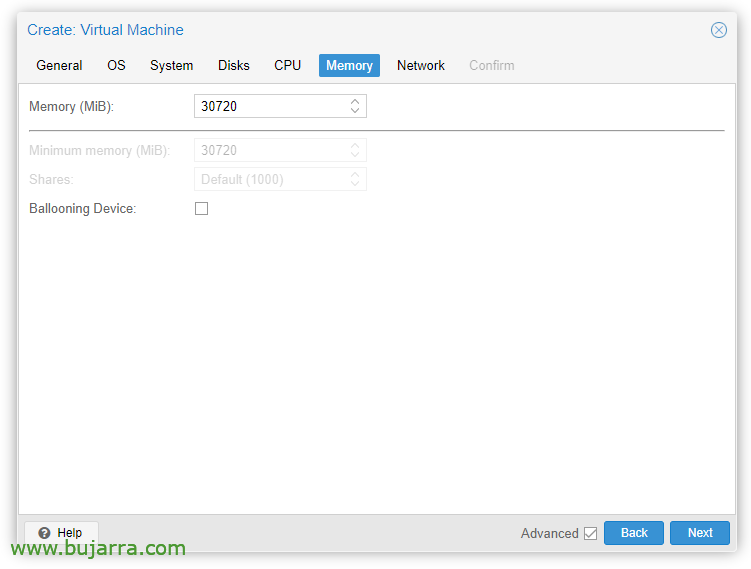
Na guia 'Memória'’ devemos desmarcar 'Dispositivo de balonismo’
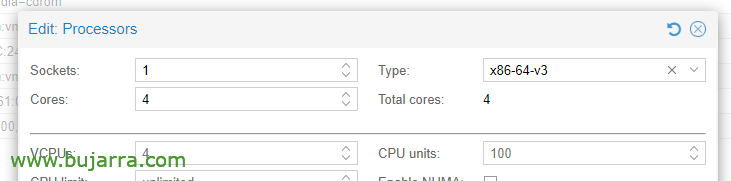
Em Opções de CPU, Editando os processadores, no tipo, Devemos escolher pelo menos x86-64-v3.
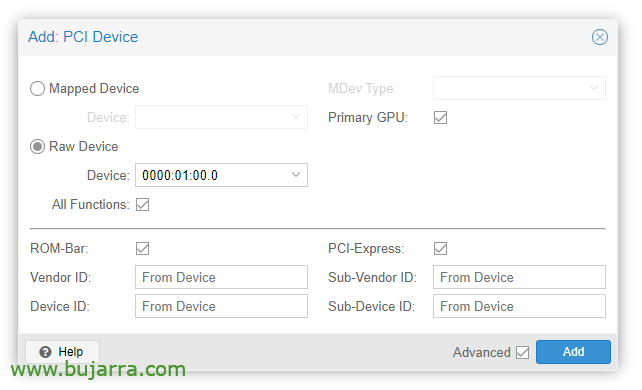
Depois que a VM é criada, podemos adicionar um dispositivo PCI a ela, editamos o hardware da VM e “Adicionar” > “Dispositivo PCI”. Verificamos todas as funções, Barra de ROM, GPU primária e PCI-Express.
Obviamente, nessa placa gráfica, conectaremos um monitor para instalar o sistema operacional (Servidor Ubuntu 24.04) e vê-lo na tela. Também teremos que passar por um teclado/mouse USB para fazer a instalação.
Em seguida, podemos instalar o sistema operacional na VM, devemos levar em consideração para instalar os drivers, no Ubuntu Desktop acho que eles são instalados durante a instalação e no servidor também marcando um 'carrapato', caso contrário, ainda podemos instalá-los:
Sudo Ubuntu-drivers install sudo apt-get update sudo apt-get upgrade sudo reboot
Tras reiniciar la MV vemos si ha cargado correctamente con 'cat /proc/driver/nvidia/version’
Versão NVRM: Módulo de kernel NVIDIA UNIX x86_64 535.171.04 Ter Mar 19 20:30:00 UTC 2024 Versão do GCC:
Continuaríamos con la instalación de Docker (doc oficial) en la MV Ubuntu:
sudo apt-get update sudo apt-get install ca-certificates curl sudo install -m 0755 -d /etc/apt/chaveiros sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/chaveiros/docker.asc sudo chmod a+r /etc/apt/chaveiros/docker.asc echo \ "Deb [arco=$(dpkg --print-architecture) assinado-por=/etc/apt/chaveiros/docker.asc] https (em inglês)://download.docker.com/linux/ubuntu \ $(. /etc/liberação do sistema operacional && ECO "$VERSION_CODENAME") estábulo" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
Debemos instalar ahora el NVIDIA Container Toolkit (doc oficial) y lo habilitamos para Docker:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#Deb [assinado por=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https (em inglês)://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list sudo apt update sudo apt -y install nvidia-container-toolkit sudo systemctl restart docker sudo nvidia-ctk runtime configure --runtime=docker sudo systemctl restart docker
Y ya es hora de desplegar los contenedores de Ollama y Open WebUI, por isso:
clone do git https://github.com/open-webui/open-webui.git cd open-webui/
Y le añadimos estos cambios al contenedor de Ollama, para que eu possa usar o gráfico e abrir a porta para as APIs (Nano docker-compose.yaml):
Runtime: Ambiente NVIDIA: - NVIDIA_VISIBLE_DEVICES=todas as portas: - 11434:11434
E, finalmente, descarregamos e iniciamos os contêineres:
sudo docker compor -d
E então podemos abrir o navegador atacando o IP da máquina virtual, para a porta 3000tcp (Inadimplência).
Acesso via Open Web UI e introdução

A primeira vez que acessamos o Open WebUI, podemos criar uma conta clicando em “Inscrever”, Criaremos uma conta simplesmente digitando nosso nome, e-mail e uma senha, Clique em “Criar uma conta”.

E a partir daqui será de onde podemos interagir, como podemos ver, podemos criar novos Chats e consultá-los com o que precisamos,
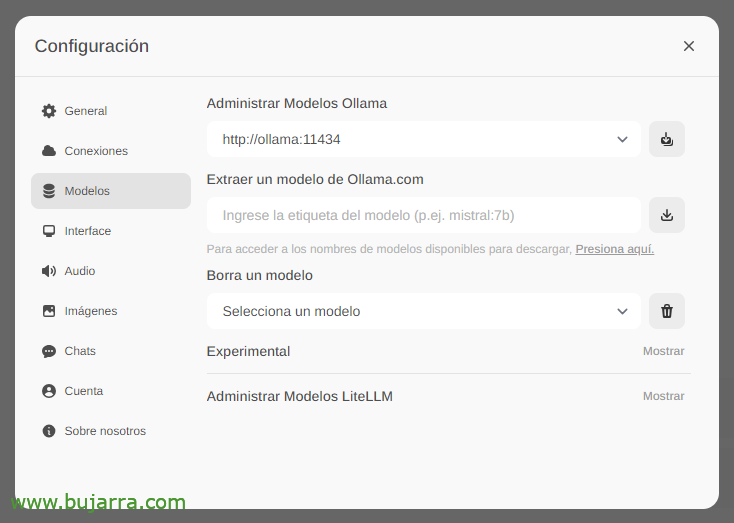
A primeira e mais importante coisa será baixar os grandes modelos de linguagem (LLM), em 'Configurações'’ > «Modelos’ Podemos extraí-los diretamente de Ollama.com digitamos, por exemplo, Mistral:7b, embora, é claro, eu recomende que você visite o top LLM mais usado, Tudo o que você precisa fazer é digitar o modelo de seu interesse e clicar no ícone de download. Eu te recomendo (até hoje) lhama3, É uma verdadeira explosão.
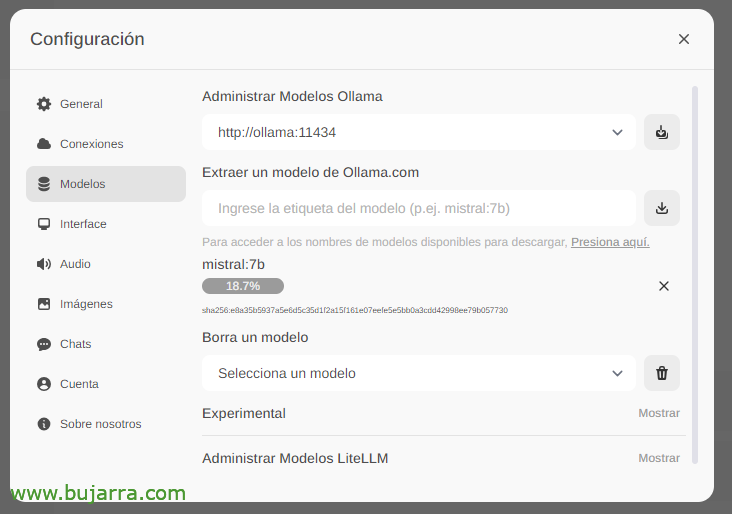
Esperamos enquanto ele baixa… E é claro que podemos descer quantos quisermos.
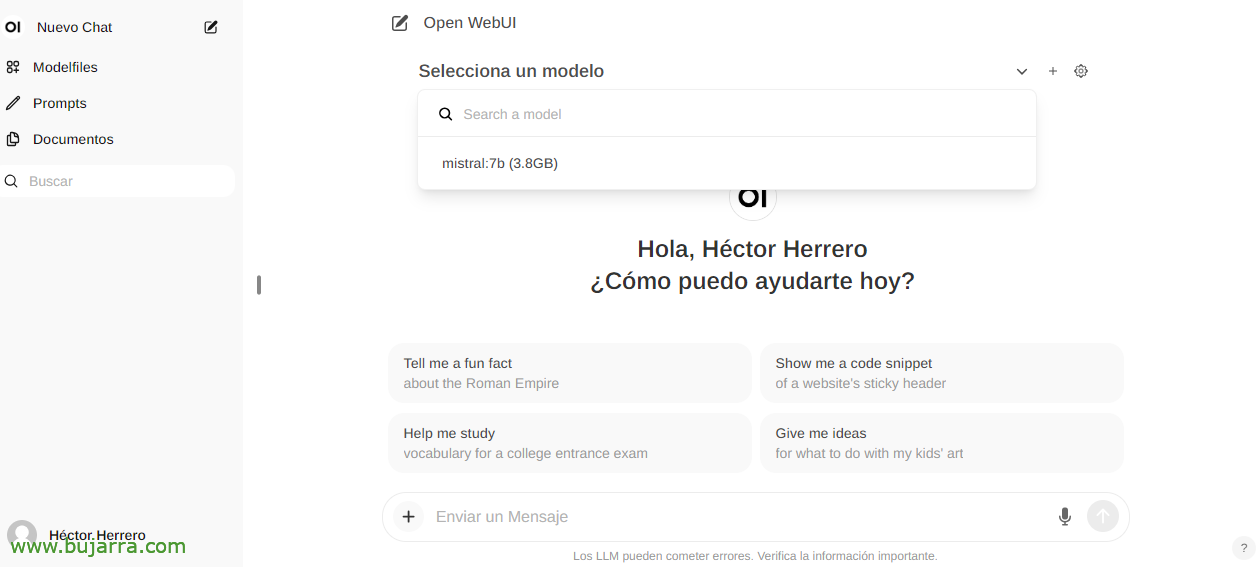
E ao criar um novo bate-papo, você pode escolher qualquer modelo baixado para começar a interagir.

E nada, Começamos a mexer, Podemos fazer qualquer pergunta para você….
Reconhecimento de imagem

Se, por exemplo, usarmos o Llama2 LLM, podemos enviar uma imagem em uma conversa ou por API e pedir que você a descreva para nós, um exemplo impressionante com um recorte de Grafana… Eu não te dou mais pistas…
Interagindo com documentos

Para ver outro exemplo rápido de suas possibilidades… De 'Documentos’ Podemos fazer upload de qualquer documento e depois conversar sobre seu conteúdo. Você pode fazer upload de um livro e pedir coisas ou conselhos, ir, Depende do que é o livro… Ou este mero exemplo de que eu carrego um whitepaper de uma migração do Active Directory, e…
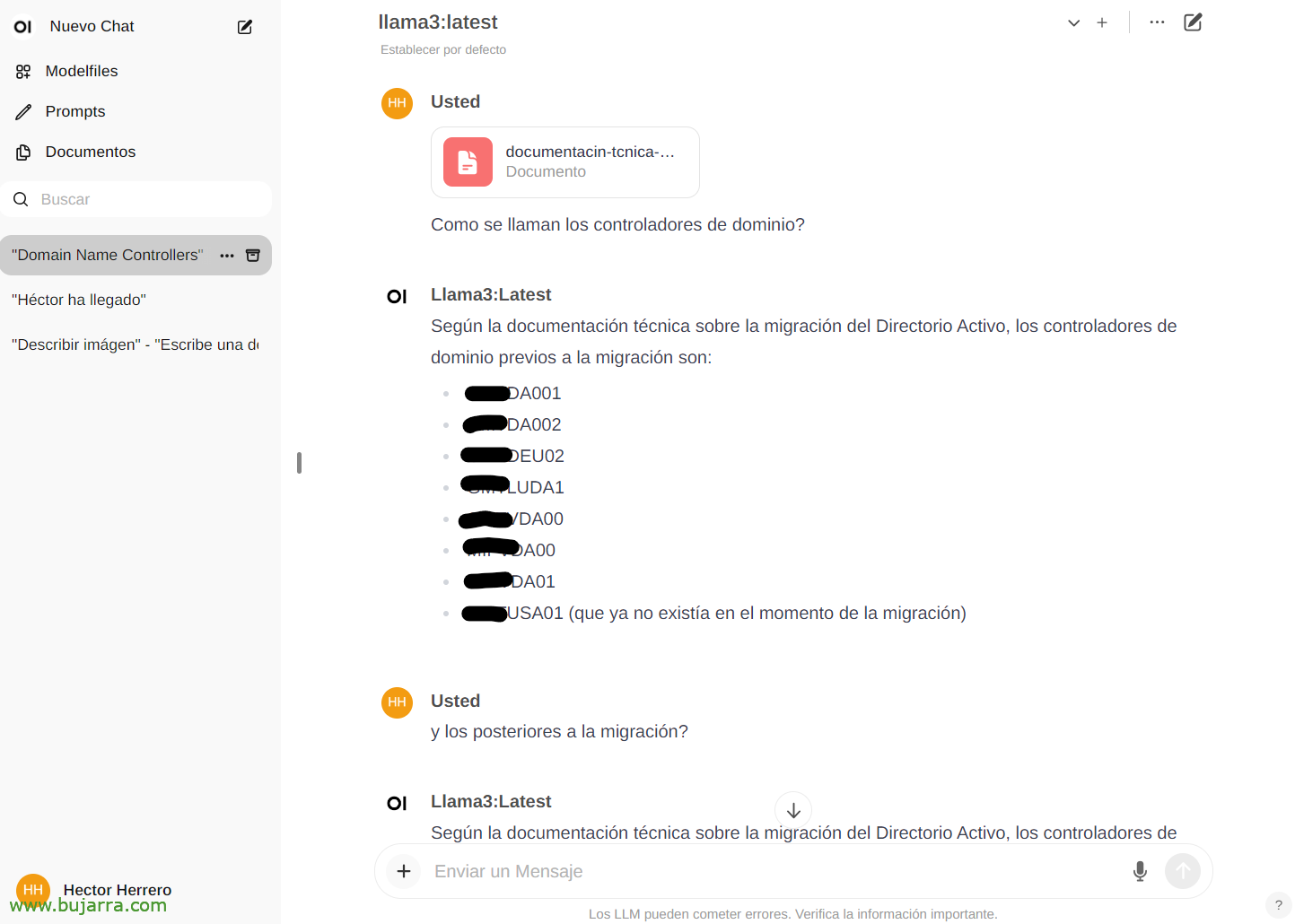
E então, no chat, podemos consultá-lo sobre um documento específico digitando o botão # e selecionando a tag que colocamos no documento. Impressionante…
Vários
E bem para finalizar o documento, Veremos as coisas no futuro, Parece muito, muito bom, Não só isso que vimos, se não todas as suas possibilidades com a API, por exemplo, e poder integrar qualquer sistema com nossa IA. Uma IA segura, local, livre, Ollama está aqui para ficar!
Em postagens futuras, graças a esta API, poderemos integrar as notificações do Centreon, por Elasticsearch, da nossa casa inteligente com Home Assistant, e eu ligo para ela e faço perguntas, Controle qualquer dispositivo da casa de forma intuitiva, receber alertas muito curiosos e um longo etc.…

Se quisermos, por exemplo, com curl para lançar uma consulta de exemplo:
Curl HTTP://Anfitrião local:11434/api/gerar -d '{ "modelo": "mistral:7b", "rápido": "Você conhece o Athletic Bilbao?", "Riacho": Falso }'
{"modelo":"mistral:7b","created_at":"2024-03-29S12:38:07.663941281Z","resposta":" Sim, Eu conheço o Athletic Club de Bilbao, é um clube de futebol espanhol da cidade de Bilbao, País Basco. Foi fundada em 14 Outubro 1894 e atualmente joga na LaLiga, Primeira Divisão Espanhola de Futebol. Ele é conhecido por seu estilo de jogo baseado em sua filosofia, que prioriza o desenvolvimento de jogadores de promoção das categorias de base do clube. Seu estádio é o San Mamés."
Ou poder colocar parâmetros para escolher o modelo, a temperatura para fazer você mais ou menos alucinar, Comprimentos… Veremos mais exemplos:
Curl HTTP://XXX.XXX.XXX.XXX:11434/api/gerar -d '{ "modelo": "mistral:7b", "rápido": "Você conhece o Athletic Bilbao?", "Riacho": Falso, "temperatura": 0.3, "max_length": 80}'
Poço, Eu não me envolvo mais, para ter uma ideia das possibilidades acho que vale a pena 🙂 Vamos ver mais coisas e curioso. E a verdade é que tenho que omitir algumas coisas porque as utilizo no meu negócio e são valores diferenciais que muitas vezes você já sabe o que acontece com fornecedores rivais…
Um abraço e desejo-lhe uma boa semana!










