安装 Elasticsearch

今天我们从第一个开始, 该文档,我们将在其中看到完全部署 Elasticsearch 所需的步骤, 这将是我们的数据仓库,用于存储设备的日志或指标, 然后使用 Kibana 或 Grafana 进行攻击以可视化它!
注册完全免费, 是开源的,基于 Java. 它负责存储我们发送给它的数据并执行搜索 (非常快) 我们存储的信息. 正如我们所理解的, 是 Elastic Stack 的核心!

Elasticsearch 是最近在所有类型的架构中使用最广泛的工具之一, 尤其是在 DevOps 方面, 它用于搜索大量数据, BigData 😛 是如何的:它是一个基于 Lucene 的搜索服务器, 提供全文搜索引擎, 使用 RESTful Web 界面和 JSON 文档的分布式和多租户.
关于要求, 很明显,这将是一台取决于每种情况的机器, 认为它需要大量的磁盘来存储我们发送给它的所有内容, 您将需要一个非常至少 1-2 个 vCPU 和 4Gb 的 RAM, 建议放置 4 个 vCPU 和 8GB 的 RAM, 但你会看到; 就像专辑一样, 那 40Gb 我们可以轻松填满它们.
安装 Elasticsearch,
开始! 我们在一台装有 Ubuntu 的机器上安装 18.10 我们已经更新并配置了静态 IP 地址. 安装过程非常快. 我们首先安装 OpenJDK 要求:
[源代码]apt-get install openjdk-8-jre-headless java -version[/源代码]
并下载我们要安装的最新 Elasticsearch 软件包, 在这篇文章中,我们使用 6.4.2, 我们继续安装它:
[源代码]wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.6.1.deb dpkg -i elasticsearch-6.6.1.deb[/源代码]
我们编辑主 Elasticsearch 配置文件 '/etc/elasticsearch/elasticsearch.yml’ 我们至少编辑了以下帖子, ,这将定义集群名称, 此节点的名称及其将用于提供服务的 IP 地址.
[源代码]cluster.name: Nombre_Cluster node.name: Nombre_Servidor network.host: Dirección_IP_servidor[/源代码]
我们需要修改系统变量 'vm.max_map_count’ 为您提供更多虚拟内存:
[源代码]sysctl -w vm.max_map_count=262144[/源代码]
我们启动 Elasticsearch 服务并将其配置为正确启动:
[源代码]服务 ElasticSearch Start SystemCTL 启用 ElasticSearch[/源代码]
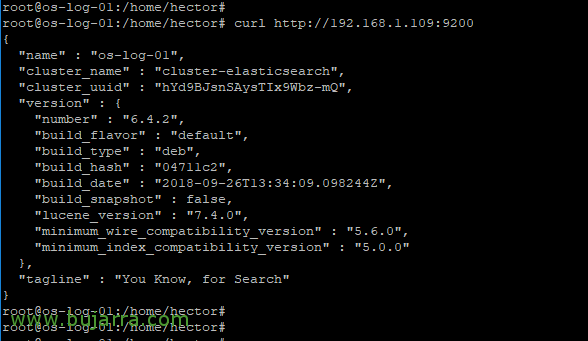
如果一切顺利, 我们将能够对其进行测试并检查服务是否正在运行:
[源代码]Curl HTTP://Dirección_IP:9200[/源代码]