监控 Veeam Backup Backup 或 Replication 作业 & 复制

继续保持集中化的思维方式, 今天我们将看到如何通过 Centreon 监控 Veeam Backup 备份的状态 & 复制, 这样我们就可以减少一个需要考虑的任务, 因为如果备份或复制任务失败,我们会立即知道. 我们不再需要时刻关注是否需要进入控制台去检查它们,
不错, 我们将依靠一个名为 ‘check_veeam_eventlogs.ps1‘, 的脚本,这个脚本将下载到负责执行备份的机器上. 这是一个 PowerShell 脚本,我们将通过 Centreon 机器使用 NRPE 远程执行它,并读取它的输出以监控复制或备份任务是否运行正常. 显然, 首先我们需要在 Centreon 机器上安装并正确配置 NRPE, 如果你还没有完成, 检讨 本文档.
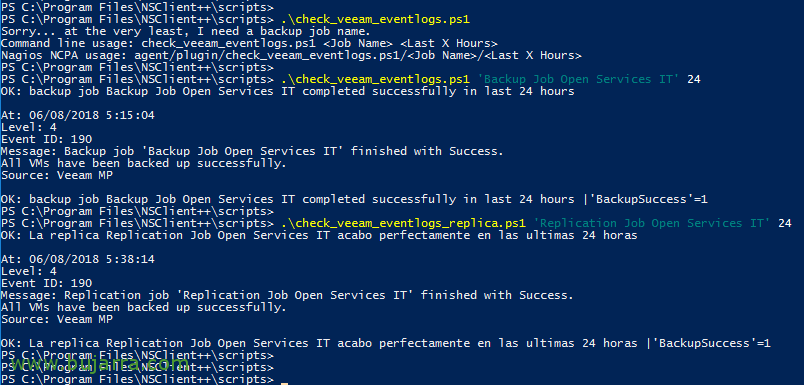
操作非常简单, 我们可以尝试从 PowerShell 执行它, 我们会将下载的文件放在 NSClient 的脚本文件夹中, 我们需要向脚本传递几个参数, 一个是作业名称,另一个是时间(以小时为单位)用于检查该时间内的任务. 例:
[源代码].\check_veeam_eventlogs.ps1 '备份作业开放服务 IT'’ 24[/源代码]
该脚本对类型为复制的作业运行得非常完美, 但对于类型为副本的作业则不适用, 无, 我们复制脚本并将其重命名为 '_replica'’ 以便拥有 2 脚本, 一个用于监控复制作业,另一个用于副本作业 (在另一篇文章中我们将看到 EndPoint 作业). 在这个新文件中我们进行了以下修改:
在线 35 将其更改为:
[源代码]$ArgEventID = 190 # 副本作业完成事件 ID[/源代码]
在线 78, 将替换为
[源代码]如果 ($LogEntry.Message.ToString() -like "*Replica*`’$ArgBackupJobName`’*")[/源代码]
然后如果我们想让它看起来更漂亮,并将输出改为更个性化的西班牙语, 我们将更改这一行 186:
[源代码]$ResultString += "CRITICAL: Se encontraron $CriticalErrorResultCount errores criticos en la replica $ArgBackupJobName en las ultimas $ArgLastHours horas"[/源代码]
还有这一行 192:
[源代码]$ResultString += "Warning: La replica $ArgBackupJobName tiene $WarningResultCount mensajes Warning en las ultimas $ArgLastHours horas"[/源代码]
La 202:
[源代码]$ResultString += "CRITICAL: La replica $ArgBackupJobName acabo con errores en las ultimas $ArgLastHours horas"[/源代码]
最后一行 208:
[源代码]$ResultString += "OK: La replica $ArgBackupJobName acabo perfectamente en las ultimas $ArgLastHours horas "[/源代码]
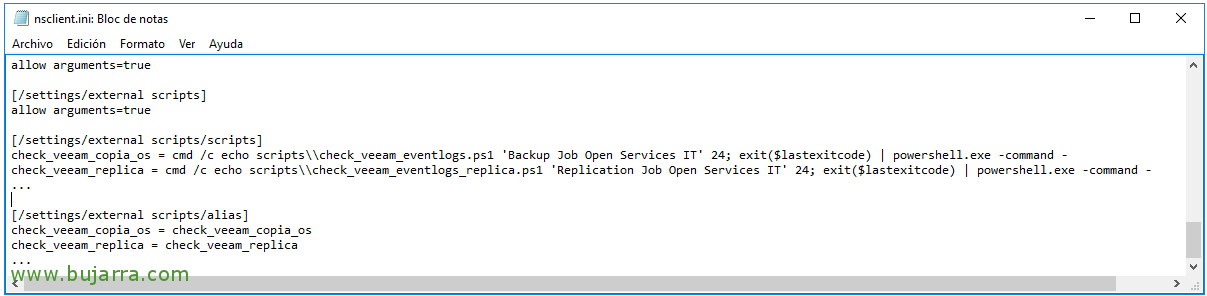
啤酒, 好了,我们准备好了, 现在只需在 nsclient.ini 文件中注册即可 (NSClient 配置) 当我们从另一台计算机调用时,它应该执行的别名和命令, como es en nuestro caso desde un Centreon. 加:
[源代码][/设置/外部脚本/脚本]
check_veeam_copia_os = cmd /c echo scripts\\check_veeam_eventlogs.ps1 ‘Backup Job Open Services IT’ 24; 退出($lastexitcode) | powershell.exe -command –
check_veeam_replica = cmd /c echo scripts\\check_veeam_eventlogs_replica.ps1 ‘Replication Job Open Services IT’ 24; 退出($lastexitcode) | powershell.exe -command –
…
[/设置/外部脚本/别名]
check_veeam_copia_os = check_veeam_copia_os
check_veeam_replica = check_veeam_replica
…
[/源代码]
我们重启计算机上的 NSClient++ 服务以便重新读取配置,然后转到 Centreon 来添加将监控复制和副本作业的服务.
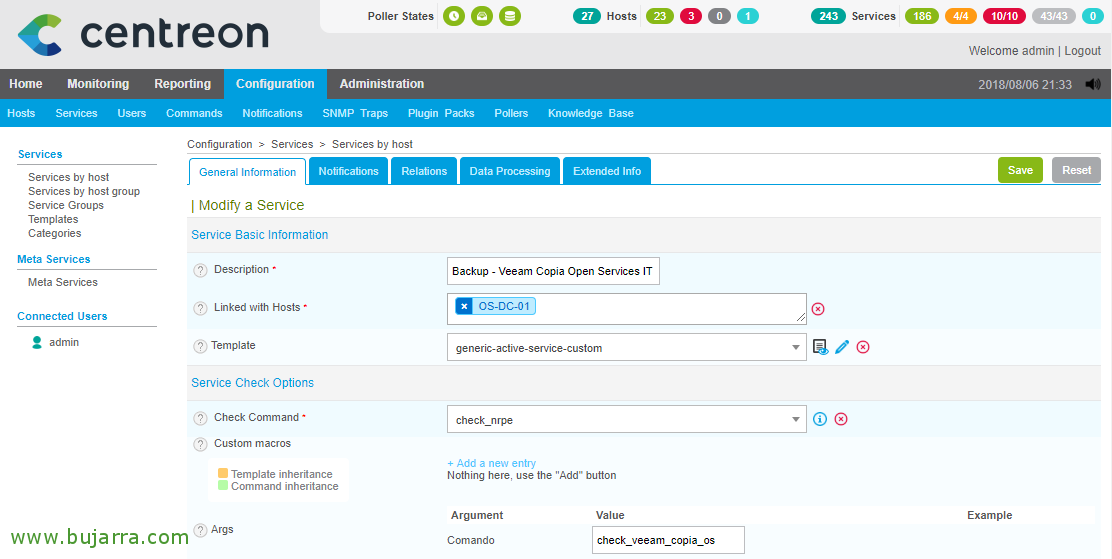
因为 “配置” > “服务业”, 我们复制任何已经用 NRPE 监控的服务,这样会更简单, 我们对其进行编辑和修改:
- 描述: 服务名称, 例如监控作业的名称.
- 与主机关联: 将其链接到已安装 Veeam 并配置了 NRPE 的服务器.
- Check 命令: 选择命令, si has seguido los documentos de este blog, se llamará ‘check_nrpe’.
- Argument: En el argumento debemos poner el Alias que hemos definido en el archivo nsclient.ini para que ejecute el script que nos interese.
Y estaría bien indicar en el ‘Normal Check Interval’ que se ejecute cada las X horas que nos interese, obviamente no nos interesa que se ejecute el checkeo cada 5 minutos si el job se ejecuta cada 24h por ejemplo. Grabamos el nuevo servicio con “救” y podremos crear tantos servicios como necesitemos para otros Jobs de Copia o los de Réplica…
Grabamos la configuración & exportamos ficheros como es habitual…
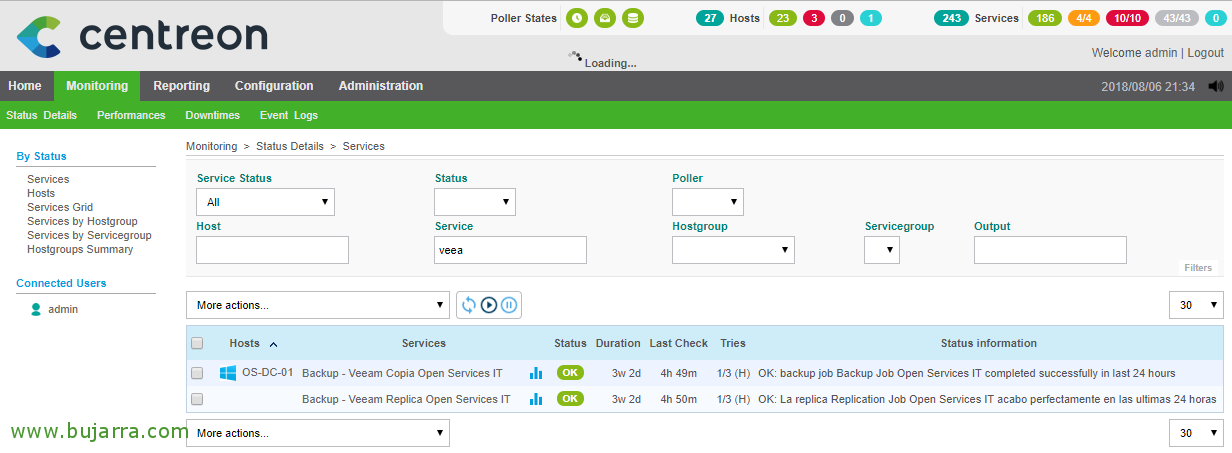
Y podremos ver tras un rato que ya tenemos monitorizado nuestras tareas de copia de seguridad o de replicación! 有了这个, otra cosa más centralizada y que podremos controlar y saber en todo momento su estado, además de disrutar de todas las ventajas de un sistema monitorizado, podremos medir SLAs…