
在 Windows 中启用重复数据删除 2012 R2

Windows Server 带来的一大新奇之处 2012 是删除卷内容的重复数据的能力, 到目前为止,这项非常重要的磁盘节省技术是由中/高端存储阵列提供给我们的, 从现在开始,我们还可以从操作系统本身优化磁盘空间!

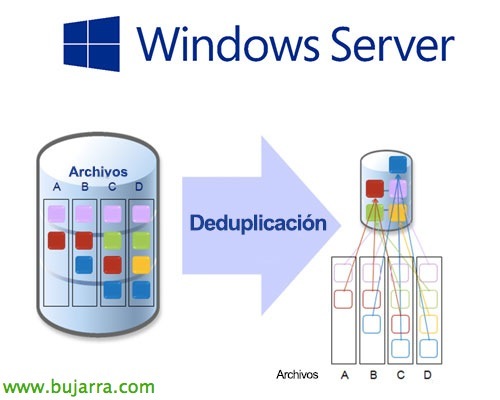
La deduplicación básicamente consiste en separar los datos del disco duro en pequeños bloques, analizar los bloques que se repiten, y crear punteros eliminando todos los bloques repetidos, con esto podremos tener un ahorro muy importante a la hora de almacenar información, dependerá del contenido almacenado, pero cuántos más bloques similares más ahorraremos 😉
No podremos habilitar la deduplicación en volúmenes de sistema, ni de arranque, ni formateados con ReFS, ni volúmenes CSV (Cluster Shared Volumes). Deberían estar particionados como MBR o GUID y en NTFS, podrán ser volumenes locales o de una red de almacenamiento como iSCSI, 燃料电池… Disponemos de la herramienta ‘DDPEval.exe’ en %WinDir%System32″ 一旦我们在服务器上安装了角色,就不必强制进行去重,这个工具将告诉我们可以释放多少空间! 不建议对 SQL Server 或 Exchange Server 类型的数据库卷进行去重,因为可能会损坏, 在这种情况下我们可以排除它们的目录. 在 Hyper-V 环境中,建议在拥有类似虚拟桌面 VHD 的卷时使用它, 不是在整个平台上使用不同的服务器… 即便如此,总是应该在去重任务的计划时间与工作负载或备份时间不冲突时进行配置.

不错, 启用去重, 我们将添加‘数据去重’角色’ dentro del rol de ‘Servicios de archivos y almacenamiento’.

随后, 在 “服务器管理员”, 在 “Servicios de archivos y de almacenamiento” > “卷”, podremos sobre cada volumen con botón derecho entrar en “Configurar desduplicación de datos…”. 如果我们看一下, en este ejemplo lo realizaré sobre el volumen F: de 300Gb y que tan sólo tiene 5Gb libres.

Podremos seleccionar el tipo de deduplicación a realizar, si sobre un volumen que almacena ficheros o uno que almacena máquinas virtuales (normalmente escritorios de VDI). Indicaremos los ficheros a deduplicar, los que tengan más de X días o podremos excluir ciertas extensiones para que sean excluidos, así como seleccionar carpetas a excluir o archivos en concreto. 选择 “Establecer programación de desduplicación…”,

Y configuramos una o dos programaciones para que analice los ficheros del volumen y realice su deduplicación!

不错, podremos ver el estado de la deduplicación desde PowerShell con ‘get-DedupStatus’, y si queremos iniciar inmediatamente el trabajo que acabamos de programar de deduplicación bastará con ejecutar ‘start-DedupJob DISCO: -type optimization’.

Podremos ir verificando el estado del trabajo con ‘get-DedupJob’ donde podremos ver el % 高级, para volver a ver el estado de la deduplicación en el volumen lo haremos con ‘get-DedupStatus’, iremos verificando cuánto vamos optimizando!!

O podremos visualmente, volver al “服务器管理员” y actualizar los volúmenes, en este en concreto teníamos antes 5Gb libres y ahora 146Gb! Si querríamos volver al origen por alguna razón y des-deduplicar el contenido recientemente optimizado ejecutaremos ‘start-DedupJob DISCO: -type Unoptimization’.










