Elasticsearch instalatzen

Gaur lehenik eta behin hasiko gara, Dokumentu bat non beharrezko pauso guztiak ikusiko ditugun Elasticsearch guztiz martxan jartzeko, Gure datu biltegia izango dena, ekipamenduen log edo metriken gordetzeko, eta ondoren Kibana edo Grafana erabiliko ditugu horiek ikusgarri egiteko!
Doan da, Open Source da eta Java-n oinarritzen da. Bidaliko dizkigun datuak gordetzeaz arduratzen da eta bilaketak egiteko (oso azkarrak) gordeta ditugun informazioaren. Uler dezakegun bezala, Elastic Stack-en bihotza da!

Elasticsearch azkenaldian erabiltzen den tresnetako bat da mota guztietako arkitekturetako, eta batez ere DevOps aldetik, helburu handietan datuen bilaketak egiteko erabiltzen da, BigData bezalakoetan 😛 Lucene-n oinarritutako bilaketa zerbitzari bat da, testu osoko bilaketa motorea eskaintzen du, banatua eta anitza da web RESTful interfaz baten bidez eta JSON dokumentuekin.
Baldintzei dagokienez, makina bat izango da, kasu bakoitzaren araberakoa, zalantzarik gabe, pensad que requerirá bastante disco para almacenar todo lo que le mandemos, necesitará mínimisimo 1-2vCPU con 4Gb de RAM, siendo commendable meterle 4vCPUs y 8GB de RAM, pero lo iréis viendo; al igual que el disco, que 40Gb puede que los llenemos fácilmente.
Instalar Elasticsearch,
Empezamos! basamos la instalación en una máquina con Ubuntu 18.10 que tenemos actualizada y configurada con un direccionamiento IP estático. El proceso de instalación es bastante rápido. Comenzamos primero instalando los requisitos OpenJDK:
[sourcecode]apt-get install openjdk-8-jre-headless java -version[/sourcecode]
Y descargamos el paquete más reciente de Elasticsearch que querramos instalar, en el caso de este post usamos una 6.4.2, procedemos a instalarlo:
[sourcecode]wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.6.1.deb dpkg -i elasticsearch-6.6.1.deb[/sourcecode]
Editamos el fichero de configuración principal de Elasticsearch '/etc/elasticsearch/elasticsearch.yml’ y editamos al menos las siguientes entradas, que definirán el nombre del clúster, el nombre de este nodo y su dirección IP con la que dará servicio.
[sourcecode]cluster.name: Nombre_Cluster node.name: Nombre_Servidor network.host: Dirección_IP_servidor[/sourcecode]
Deberemos modificar la variable del sistema 'vm.max_map_count’ para darle más memoria virtual:
[sourcecode]sysctl -w vm.max_map_count=262144[/sourcecode]
Iniciamos el servicio de Elasticsearch y lo configuramos para que inicie correctamente:
[sourcecode]service elasticsearch start systemctl enable elasticsearch[/sourcecode]
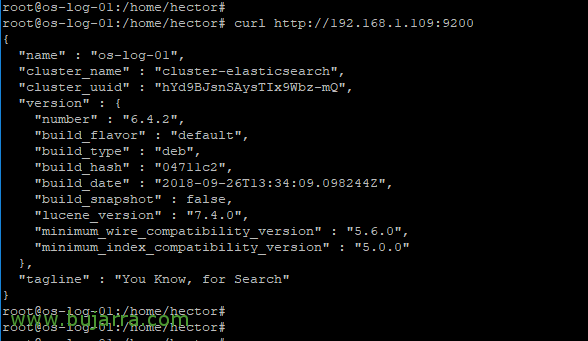
Si todo ha ido bien, podremos probarlo y verify si el servicio está corriendo:
[sourcecode]curl http://Dirección_IP:9200[/sourcecode]