
使用 Telegraf 监控延迟

一些非常简单且非常有用的东西可以知道不同 IP 地址的延迟, 我们可以实时可视化, 配软饮料 1 第二, IP 地址响应所需的时间, 它们可能是私有的或公共的; 例如, 了解我们是否有 Internet 问题以及它们在哪里, 例如 🙂
您将看到多么快速和简单! 我想我们都已经安装了 Influxdb 和 Grafana, 如果您有任何问题,我们有这个 初始帖子. 井, 好吧,对于任何安装了 Telegraf 的机器,我们都会在一分钟内完成. 我们将不得不决定从哪里执行 Ping 以了解其延迟, 如果我们有疑问, Influxdb 机器本身可以安装 Telegraf 代理,然后我们将从那里执行 ping。.
我们编辑 Telegraf 文件,在 Inputs 部分添加如下内容就足够了, 其中,在示例中,我们看到一个 Ping 到 Google 的 DNS,另一个 Ping 到我网络上的本地 IP, 路由器:
... [[inputs.ping]] 网址 = ["8.8.8.8"] # 必需计数 = 1 接口 = "ENS32 系列" name_override = "ping_google" 间隔 = "1s" [[inputs.ping]] 网址 = ["192.168.0.1"] # 必需计数 = 1 接口 = "ENS32 系列" name_override = "ping_router_movistar" 间隔 = "1s" ...
请记住,如果我们想使用软饮料 1 第二, 我们必须在 'interval' 和 'flush_interval' 参数中指明这一点. 照常, 点按配置文件后, 我们重新启动 Telegraf 服务并让它读取新配置:
sudo systemctl restart telegraf
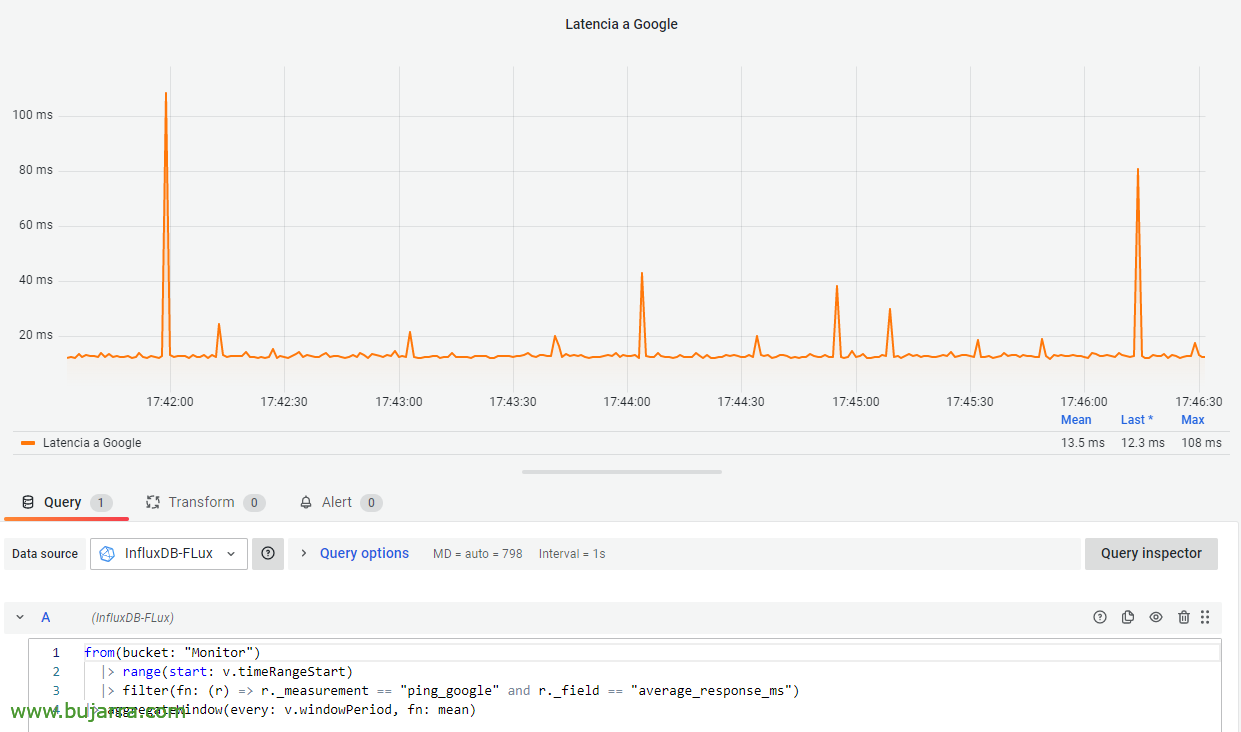
有了这个和一个蛋糕… 我们已经在 Influxdb 中拥有了数据, 所以接下来就是去 Grafana! 在那里,我们已经针对这个 Influxdb 配置了 Data Source, 接下来就是在 Dashboard 中添加一个 Dashboard, 针对 Flux 类型的 Influxdb 数据源,通过此查询,我们将得到它:
从(桶: "监控") |> 范围(开始: v.timeRangeStart) |> 滤波器(Fn: (r) => r._measurement == "ping_google" 和 r._field == "average_response_ms") |> 聚合窗口(每: v.windowPeriod, Fn: 意味 着)

砰!! 我们抓住了他! 一分钟内什么? 珍贵! 我们已经有一个示例,说明如何实时可视化不同 IP 地址的延迟. 您可以绘制包含跟踪的控制面板, 路线并了解瓶颈所在, 立即或作为历史咨询.
拥抱所有人, 这样我们就是现代的… 无论如何, 现在认真, 照顾好自己, 感谢您的阅读, 小老鼠, 当您在社交媒体上点赞或分享时… 无论如何, 谢谢!










