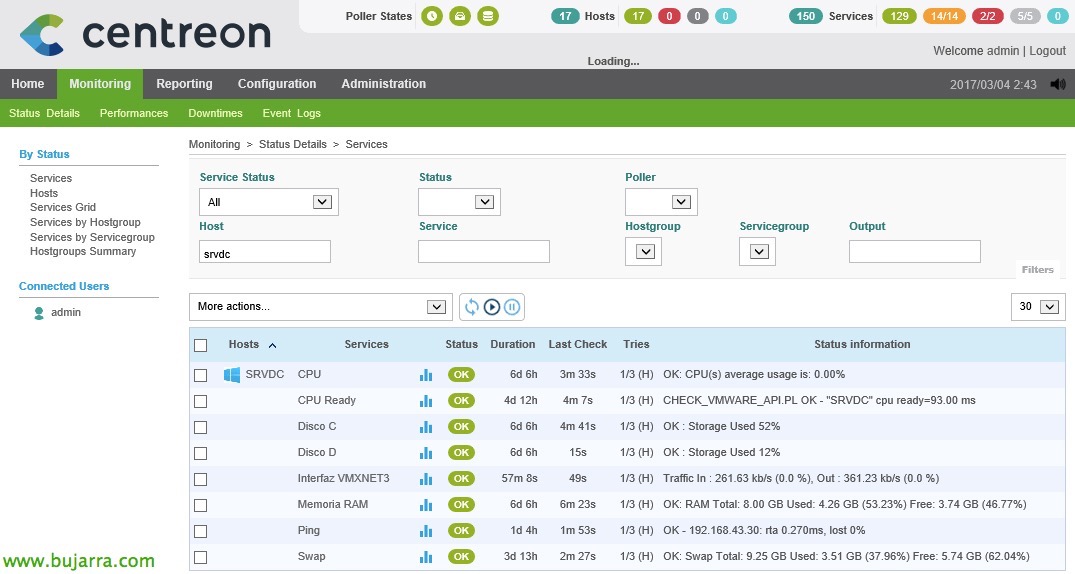
纳吉奥斯 – 监控我们的 ESXi 主机

本文档内容, 我们将了解能够监控 ESXi 主机所需的所有步骤, 我们将看到最常见的参数和值,由于 Nagios 和 Centreon 的帮助,我们可以获得受控环境! 我们能获得的所有信息都是惊人的! 在其他文档中,我们将看到可以从 vCenter 及其 VM 获取的其他信息, 今天,东道主们在比赛!

安装要求,
首先,我们将从安装所有必要的需求开始,以使用我们可以使用的最常见脚本之一. 在 Nagios 交易所 我们将能够获得几乎任何我们需要的脚本, 然后,我们将从那里下载一个我通常用于监控 ESXi 4.x 主机的主机, 5.x 或 6.x. 但首先我们必须在 nagios 机器上安装 VMware SDK 以及之前所需的一切.
在安装并测试了所有要求后,用于监控 ESXi 服务器的脚本可以正常工作, 我们现在将能够退出控制台并使用 Centreon 界面创建 ESXi 主机, 我们将监控的服务和必要的命令. 我希望大家能很好地理解, 以执行步骤!

安装要求:
[源代码]yum -y install openssl-devel perl-Archive-Zip perl-Class-MethodMaker uuid-perl perl-SOAP-Lite perl-XML-SAX perl-XML-NamespaceSupport perl-XML-LibXML perl-MIME-Lite perl-MIME-Types perl-MailTools perl-TimeDate uuid libuuid perl-Data-Dump perl-UUID make gcc perl-devel libuuid-devel cpan[/源代码]
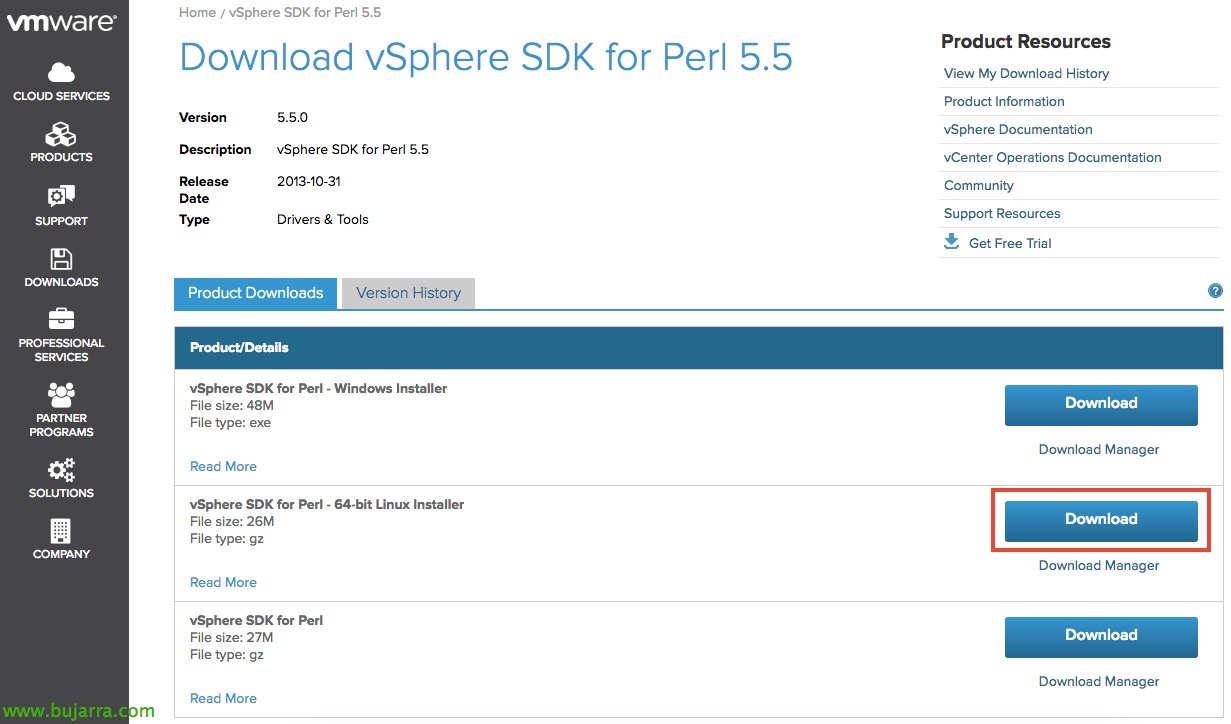
我们搜索 VMware 下载网站, 适用于 Perl 的 vSphere SDK, 我们从 GZ 软件包下载 64 位.
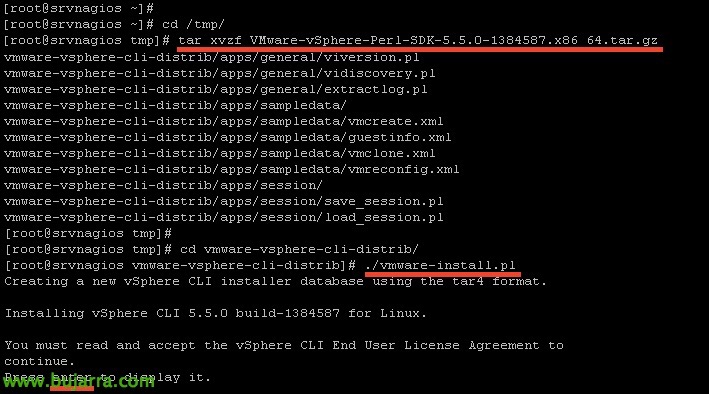
例如,我们使用 WinSCP 将其上传到 Nagios 服务器,并将其保留在临时目录 '/tmp/' 中. 我们解压并安装:
[源代码]tar xvzf VMware-vSphere-Perl-SDK-xxxxxxx.tar.gz
cd vmware-vsphere-cli-distrib/
./vmware-install.pl[/源代码]
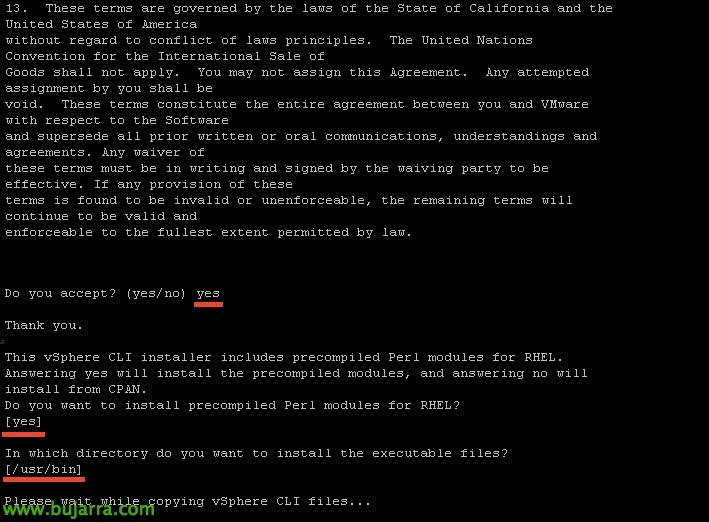
我们使用默认参数安装它,
几秒钟后,我们将安装它,

我们安装 UUID:
[源代码]cd /usr/src
WGET HTTP://search.cpan.org/CPAN/authors/id/J/JN/JNH/UUID-0.04.tar.gz
tar -xzvf UUID-0.04.tar.gz -C /opt[/源代码]
我们编译它:
[源代码]cd /opt/UUID-0.04
珍珠 Makefile.PL
做[/源代码]
我们安装了它, 以及 'perl-Nagios-Plugin'’ 这也是必要的:
[源代码]make install
yum 安装 perl-Nagios-Plugin[/源代码]
我们安装更多要求:
[源代码]CPAN GAAS/libwww-perl-5.837.tar.gz[/源代码]
我们正在结束后者!
[源代码]cpan 监控::插件[/源代码]
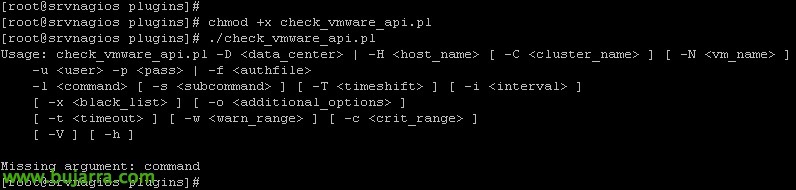
最后, 我们将能够下载脚本,该脚本将允许我们从这里的主机获取信息 https://exchange.nagios.org/directory/Plugins/Operating-Systems/*-Virtual-Environments/VMWare/check_vmware_api/details 下载后,我们将保留文件“check_vmware_api.pl’ 位于 '/usr/lib/centreon/plugins/’ 我们将使用 'chmod +x check_vmware_api.pl' 使其可执行. 我们将尝试运行它,如果一切正确,将出现此屏幕,指示我们可以使用的选项.
在 ESXi 中创建特权用户,
上述脚本, 需要针对 ESXi 主机进行验证,以获取我们感兴趣的信息, 因此,我们将在每个 ESXi 中创建一个用户并授予必要的权限.
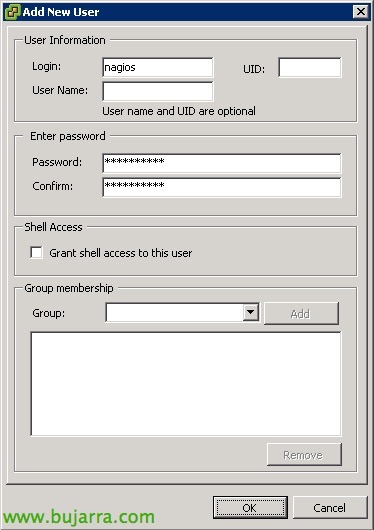
在每个 ESXi 中, 使用传统客户端或 Web 浏览器登录后, 我们将前往 “用户” 我们将创建一个, 我们还将设置您的密码.
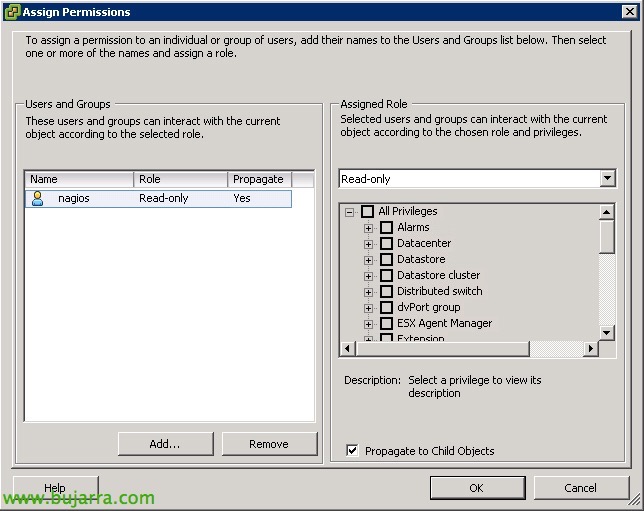
在 “权限”, 我们会将此用户添加到尽可能多的范围内, ,我们将使用 'Read-Only' 角色添加它.
现在, 我们将在我们感兴趣的目录中创建 (我把它留在相同的插件中) 一个文件, 我们将存储命令在执行检查时用于验证自身的用户名和密码. 在此示例中,我将其保存到 '/usr/lib/centreon/plugins/check_vmware_api.auth’ 格式如下:
[源代码]用户名=用户
password=密码[/源代码]

我们已经可以对 ESXi 主机运行任何检查, 尝试一些简单的方法, CPU 使用率:
[源代码]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l cpu -s usage -w 80 -c 90[/源代码]
命令附带的参数如下所述, 在前面的命令 '-w’ 将是 % Warning 和 '-c 时发出警告’ 当 Critical 时的值. 我告诉你这些,因为它在几乎所有的命令中都很常见, 以及每个使用我们想要的人, 在这些文档中,您会发现,通常当您到达 80% 将是 Warning 的内容,当它到达 90% 将是 Critical.
现在剩下的就是选择我们最感兴趣的监控元素, 在文档的末尾,我将列出这个出色的命令“check_vmware_api.pl”为我们带来的所有可能性. 但现在,我为您提供了监控 ESXi 主机中信息的最常见示例:
RAM 使用情况:
[源代码]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l mem -s 用法 -w 80 -c 90[/源代码]
交换内存使用情况
[源代码]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l mem -s 交换 -w 1 -c 10[/源代码]
使用 Balloning Memory
[源代码]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l mem -s memctl -w 1 -c 10[/源代码]
网络使用情况
[源代码]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l net -s 用法 -w 10240 -c 102400[/源代码]
检测我们的 NIC 是否出现故障,
[源代码]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l net -s nic -w 1 -c 2[/源代码]
监控 VMFS 数据存储, 在这个, 命令返回免费使用, 因此,我们将在 Warning (警告) 和 Critical (严重) 中使用以下格式指示 % 间隙,
[源代码]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l vmfs -s -s LUN04 -w 10%: -c 5%:[/源代码]
例如,使用 'runtime' 参数’ 我们将了解服务器的概述, 或者,我们可以添加其他选项,例如 'health’ 查看运行状况, '温度’ 查看温度传感器, 或 'status’ 查看摘要等.
[源代码]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l 运行时
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime -s 运行状况
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime -s 温度
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime -s status[/源代码]
如果我们使用参数 'service’ 我们将能够看到所有 ESXi 服务的状态(无论它们是否正在运行), 此外,我们可以添加我们仅对监控感兴趣的服务的名称.
[源代码]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l 服务
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l service -s DCUI vpxa[/源代码]
就目前而言,我认为这对我们来说已经足够了, 不? 由于脚本 'check_vmware_api.pl’ 它还有更多内容可供您浏览,我们将在其他帖子中看到, 监控 Host 集群也很有用, 数据中心, 虚拟机, 等… 改天再来 ;), 现在我们继续介绍主机!
创建主机,
在这里,我们最终将在 Nagios 中注册我们的第一台服务器, ESXi 主机! 我们将使用 Centreon 让所有工作更轻松.

因为 “配置” > “主机” > “加”, 我们将添加我们的第一个服务器, 我们至少会填写以下字段:
- 名字: 服务器名称.
- 别名: 服务器别名.
- IP地址 / DNS 解析: 服务器的 IP 地址或 DNS 名称.
- SNMP 社区 & 版本: 在这种情况下,没有必要.
- 监控来源: 将监视此主机的 Poller.
- 模板: 选择“generic-active-host”.
创建命令,
我们将在 Centreon 中使用变量定义一个命令,以便能够执行我们之前看到的命令, 然后,将从我们创建的每个 Service 中调用此命令,以监控 CPU, 公羊… 有什么比理解它🙂更好的方式来看待它
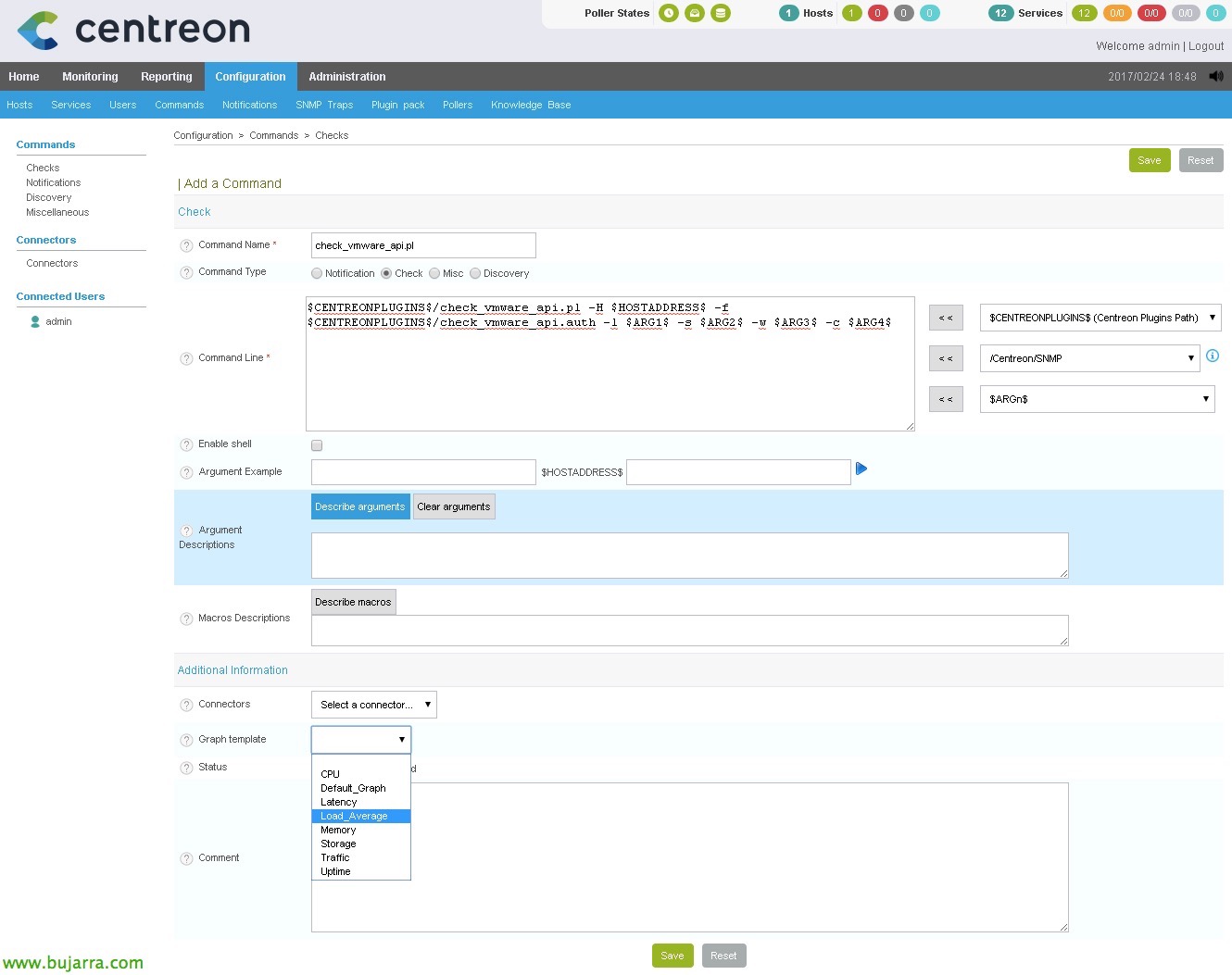
我通常喜欢将 Command 称为与脚本相同的名称, 因此, 在本例中,我将创建命令 'check_vmware_api.pl'. 为此,, 因为 “配置” > “命令” > “检查” > “加”. 我们指示它是 'Check’ 在“我们指示的命令行”中:
[源代码]$CENTREONPLUGINS$/check_vmware_api.pl -H $HOSTADDRESS$ -f $CENTREONPLUGINS$/check_vmware_api.auth -l $ARG 1$ -s $ARG 2$ -w $ARG 3$ -c $ARG 4$[/源代码]
- 变量 $CENTREONPLUGINS$ 是 '/usr/lib/centreon/plugins/’
- 变量 $HOSTADDRESS$ 将是要监控的服务器的 IP 地址或 FQDN 名称.
- ARG1 将是我们将传递给您的第一个参数, 如果我们记得的话,它是 '命令’ 在 '-l' 之后表示.
- ARG2 将是我们将传递给它的第一个参数,如果我们记得它是 'SubCommand’ 在 '-s' 之后表示.
- ARG3 将是 Warning 的值.
- ARG4 将是 Critical 的值.
点击 “描述参数” 所以我不必记住和知道这个.
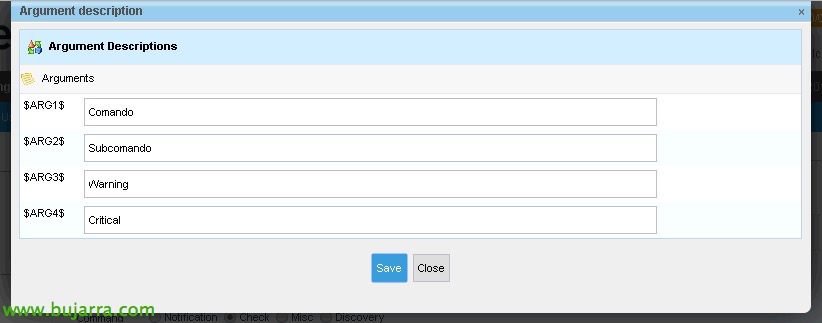
因此,我们以一种简单的方式关联每个 Argument 是什么, 稍后当我们创建服务, 我们将不胜感激. “救”.
创建服务,
在这里,我们终于可以创建我们想要监控的服务了, 是 CPU, 公羊, 丢弃的 NIC, 数据存储状态… 为此, 正如我们在刚刚创建的命令中所说的那样,我们将相互支持! 看看这有多容易:
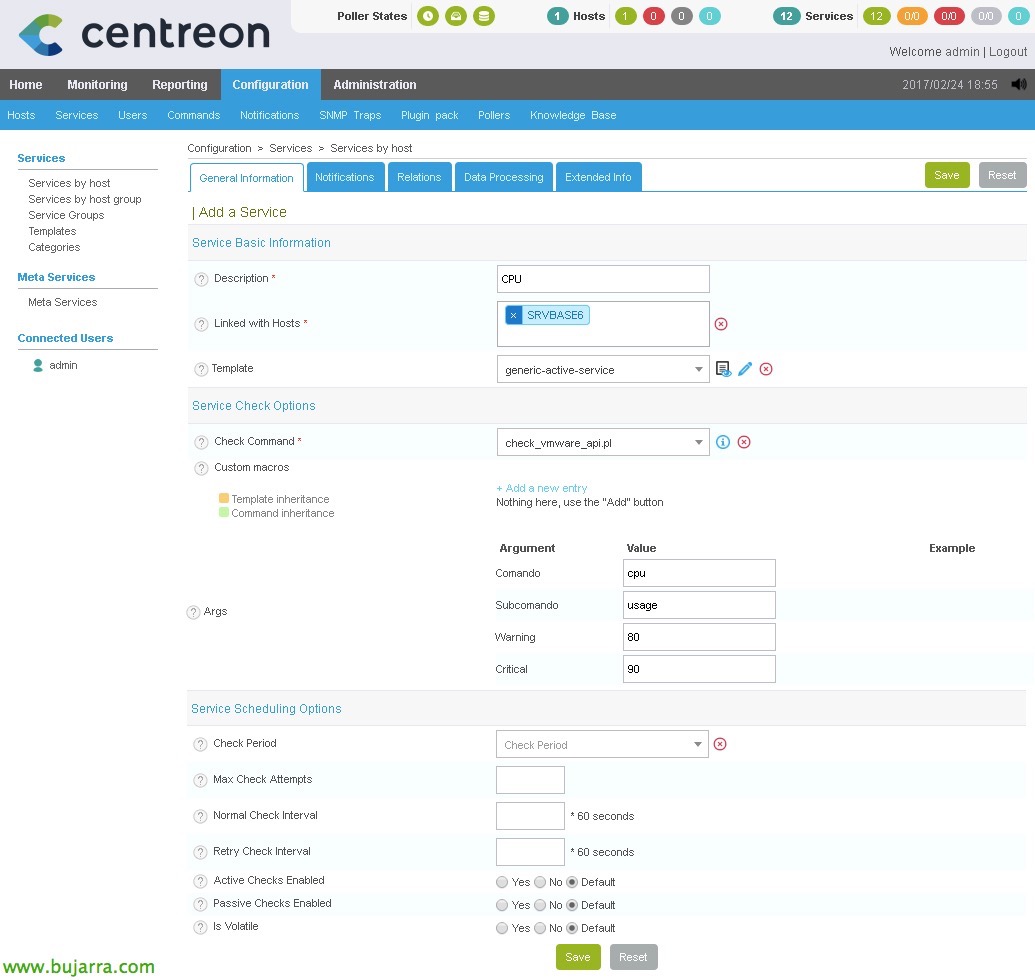
在 “配置” > “服务业” > “加”, 我们将创建我们的第一个服务! 我们至少会填写以下信息:
- 描述: 服务名称, 在我的情况下是 CPU, 公羊, 交换内存…
- 与主机关联: 在这里,我们将添加之前创建的主机, 我们的 ESXi 服务器.
- 模板: 选择“generic-active-service”.
- Check 命令: 我们还选择之前创建的命令, 就我而言,我将其称为脚本“check_vmware_api.pl’
- 参数: 我们必须填写命令要求我们填写的所有参数.
- CPU 使用率: 中央处理器 / 用法 / 80 / 90
- 公羊: 内存 / 用法 / 80 / 90
- 交换内存: 内存 / 交换 / 1 / 10
- Balloning 内存: 内存 / memctl / 1/ 10
- NIC 状态: 网 / 网卡 / 1 / 2
- …
我们用 “救”,
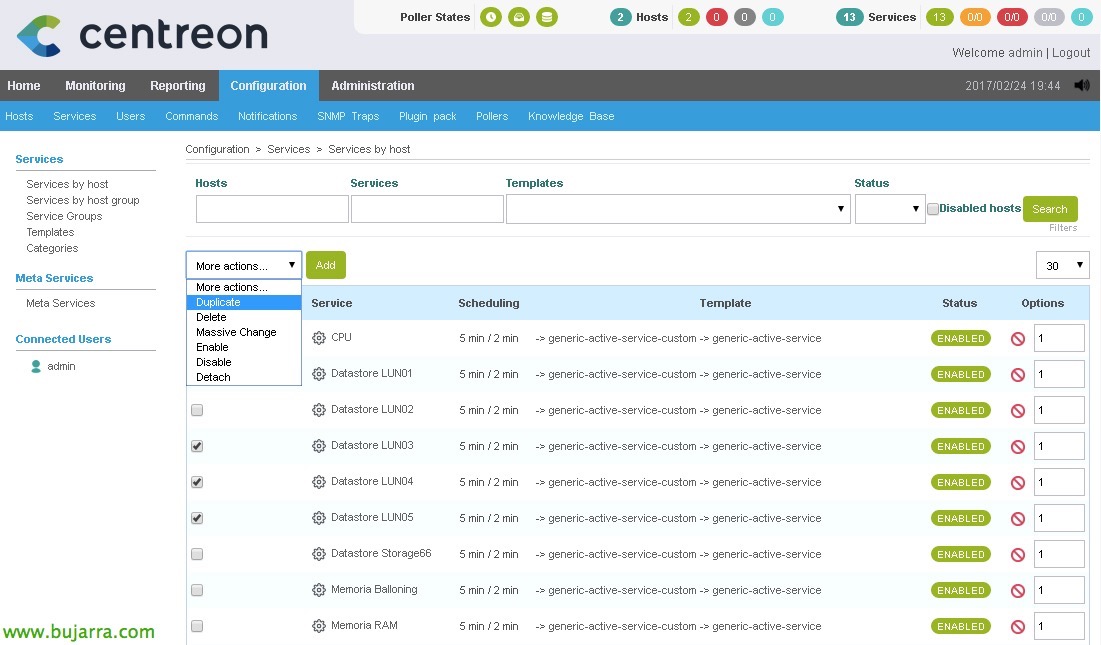
创建其余服务, 而不是从头开始创建它们, 最舒服的办法是复制它们, 这样我们只需要编辑参数,创建服务就会容易得多.

创建与 ESXi 主机关联的所有服务后, 如果我们现在要复制已完成的工作以监控我们拥有的另一台 ESXi 主机, 或者我们有多少, 因为 “配置” > “主机”, 我们将选择我们拥有的 ESXi 并复制它, 这样,我们生成了一个新的主机, 我们将不得不将名称更改为, 别名和 IP 地址,我们将为另一台主机准备好相同的服务!
什么都没有, 通常的, 工作完成后, 我们保存更改, Cenreon 将生成必要的 nagios 文件, “配置” > “轮询器” > “导出配置”,

我们选择我们的轮询器, 我们标记检查并重新启动 & “出口”,

生成所有内容后, 我们现在可以转到监控部分并检查我们所做的一切是否正常工作! 我们将看看我们创建的所有新服务,这些服务可以监控不同的事物. 如果我们想强制检查, 我们已经知道了, 我们选择我们感兴趣的服务,并在组合中选择“服务 – 安排立即检查 (强迫)’.
在这里,我把命令的所有可能性都留给你:
[源代码]用法: check_vmware_api.pl -D <data_center> | -H <host_name> [ -C <cluster_name> ] [ -N <vm_name> ]
-或 <用户> -p <通过> | -f <auth文件>
-l <命令> [ -s <子命令> ] [ -T <时移> ] [ -我 <间隔> ]
[ -x <black_list> ] [ -或 <additional_options> ]
[ -t <超时> ] [ -w <warn_range> ] [ -c <crit_range> ]
[ -V ] [ -h ]
-?, –用法
打印使用信息
-h, –帮助
打印详细的帮助屏幕
-V, –版本
打印版本信息
–额外 opts=[部分][@file]
从 ini 文件中读取选项.
有关用法和示例.
-H, –主机=<主机名>
ESX 或 ESXi 主机名.
-C, –集群=<clustername (集群名称)>
ESX 或 ESXi 集群名称.
-D, –数据中心=<DCname>
数据中心主机名.
-N, –名称=<VM名称>
虚拟机名称.
-或, –用户名=<用户名>
要连接的用户名.
-p, –密码=<密码>
用于用户名的密码.
-f, –authfile=<路径>
包含登录名和密码的身份验证文件. 文件语法 :
用户名=<登录>
密码=<密码>
-w, –warning=阈值
警告阈值. 看
对于阈值格式. 默认情况下, 未设置阈值.
-c, –critical=阈值
临界阈值. 看
对于阈值格式. 默认情况下, 未设置阈值.
-l, –command=命令
指定命令类型 (中央处理器, 微机电, 网, IO, VMFS, 运行, …)
-s, –subcommand=SUBCOMMAND
specify 子命令
-S, –会话文件=会话文件
指定文件名以存储会话以加快身份验证速度
-x, –exclude=<black_list>
指定黑名单
-或, –选项=<additional_options>
指定其他命令选项 (快速统计, …)
-T, –时间戳=<时移>
Timeshift in seconds that could fix issues with "Unknown error". 使用像 5, 10, 20, 等
-我, –间隔=<采样周期>
采样周期(秒). 基本历史间隔: 300, 1800, 7200 或 86400. 查看配置以了解任何更改.
支持 literval 值到自动协商区间值: r – 实时间隔, h<数> – 位置指定的历史间隔.
默认值为 20 (实时). 由于集群没有除 20(默认实时) 是强制性的.
-M, –最大样本=<最大样本计数>
要检索的最大样本数. 对于历史间隔,将忽略最大样本数.
默认值为 1 (最新可用示例).
–trace=<水平>
设置 vSphere API 请求/响应跟踪的详细级别
–generate_test=<文件>
从执行的命令/子命令生成测试用例脚本,并将其写入 <文件>. 如果 <文件> is "stdout", 测试用例脚本被写入 stdout.
-t, –timeout=整数
插件超时前的秒数 (违约: 30)
-v, –详细
显示命令行调试的详细信息 (最多可以重复 3 次)
支持的命令(^ – 空白或未指定参数, 或 – 选项, T – Timeshift 值, b – 黑名单) :
特定于 VM :
* 中央处理器 – 显示 CPU 信息
+ 用法 – CPU 使用率百分比
+ 用法MHZ – CPU 使用率 (MHz)
+ 等 – CPU 等待时间(毫秒)
+ 准备 – CPU 就绪时间(毫秒)
^ 所有 CPU 信息(无阈值)
* 内存 – 显示 MEM 信息
+ 用法 – MEM 使用百分比
+ usagemb – mem 使用量 (MB)
+ 交换 – 交换内存使用量 (MB)
+ swapin (换货) – swapin mem 使用量 (MB)
+ 换售 – swapout mem 使用情况 (MB)
+ 开销 – VM Server 使用的其他内存 (MB)
+ 整体 – VM Server 使用的总内存 (MB)
+ 积极 – 活动内存使用量 (MB)
+ memctl – VM 内存控制驱动程序使用的 mem(vmmemctl) 控制气球
^ 所有 MEM 信息(除了 overall 和 no thresholds)
* 网 – 显示网络信息
+ 用法 – 总体网络使用情况 (KBps)(千字节/秒)
+ 收到 – 以 KBps 接收(千字节/秒)
+ 发送 – 以 KBps 格式发送(千字节/秒)
^ 所有网络信息(except usage 和 no thresholds)
* io – 显示磁盘 I/O 信息
+ 用法 – 总体磁盘使用率 (MB/s)
+ 读 – 读取磁盘使用率 (MB/s)
+ 写 – 写入磁盘使用率 (MB/s)
^ 所有磁盘 IO 信息(无阈值)
* 运行 – 显示运行时信息
+ 跟 – 连接状态
+ 中央处理器 – 分配的 CPU (MHz)
+ 内存 – 分配的 mem (MB)
+ 州 – 虚拟机状态 (向上, 下, 暂停)
+ 地位 – 总体对象状态 (灰/绿/红/黄)
+ 控制台连接 – 与 VM 的控制台连接
+ 客人 – 来宾 OS 状态, 需要 VMware Tools
+ 工具 – VMware Tools 状态
+ 问题 – 主机的所有问题
^ 所有运行时信息(除了 con 和 no thresholds)
主机特定 :
* 中央处理器 – 显示 CPU 信息
+ 用法 – CPU 使用率百分比
o 快速统计 – switch 用于查询 PerfCounter 值或 Runtime info
+ 用法MHZ – CPU 使用率 (MHz)
o 快速统计 – switch 用于查询 PerfCounter 值或 Runtime info
^ 所有 CPU 信息
o 快速统计 – switch 用于查询 PerfCounter 值或 Runtime info
* 内存 – 显示 MEM 信息
+ 用法 – MEM 使用百分比
o 快速统计 – switch 用于查询 PerfCounter 值或 Runtime info
+ usagemb – mem 使用量 (MB)
o 快速统计 – switch 用于查询 PerfCounter 值或 Runtime info
+ 交换 – 交换内存使用量 (MB)
o listvm – 打开/关闭交换 VM 的输出列表
+ 开销 – VM Server 使用的其他内存 (MB)
+ 整体 – VM Server 使用的总内存 (MB)
+ memctl – VM 内存控制驱动程序使用的 mem(vmmemctl) 控制气球
o listvm – 打开/关闭膨胀 VM 的输出列表
^ 所有 MEM 信息(除了 overall 和 no thresholds)
* 网 – 显示网络信息
+ 用法 – 总体网络使用情况 (KBps)(千字节/秒)
+ 收到 – 以 KBps 接收(千字节/秒)
+ 发送 – 以 KBps 格式发送(千字节/秒)
+ 网卡 – 确保所有活动的 NIC 都已插入
^ 所有网络信息(except usage 和 no thresholds)
* io – 显示磁盘 IO 信息
+ 中止 – Aborted Commands Count (中止的命令计数)
+ 重 置 – 总线重置计数
+ 读 – 读取延迟(毫秒) (totalReadLatency.average)
+ 写 – 写入延迟(毫秒) (totalWriteLatency.average)
+ 内核 – 内核延迟(毫秒)
+ 装置 – 设备延迟(毫秒)
+ 队列 – 队列延迟(毫秒)
^ 所有磁盘 IO 信息
* VMFS – 显示数据存储信息
+ (名字) – 名称为 的 Datastore 的可用空间信息 (名字)
o 已使用 – 输出已用空间而不是可用空间
o 简介 – 仅列出警报卷
o 正则表达式 – 是否将 name 视为 regexp
o 黑名单正则表达式 – 是否将黑名单视为 regexp
b – 将 VMFS 列入黑名单
T (价值) – timeshift 更改为 detemine(如果我们需要刷新)
^ 所有数据存储信息
o 已使用 – 输出已用空间而不是可用空间
o 简介 – 仅列出警报卷
o 黑名单正则表达式 – 是否将黑名单视为 regexp
b – 将 VMFS 列入黑名单
T (价值) – timeshift 更改为 detemine(如果我们需要刷新)
* 运行 – 显示运行时信息
+ 跟 – 连接状态
+ 健康 – 检查 CPU/存储/内存/传感器状态并传播最差状态
o 列表项 – 列出所有可用的传感器(仅用于列表目的)
o blackregexp标志 – 是否将黑名单视为 regexp
b – 黑名单状态对象
+ 存储运行状况 – 存储状态检查
o blackregexp标志 – 是否将黑名单视为 regexp
b – 黑名单状态对象
+ 温度 – 温度传感器
o blackregexp标志 – 是否将黑名单视为 regexp
b – 黑名单状态对象
+ 传感器 – 阈值指定传感器
+ 保养 – 显示主机是否处于维护模式
O maintwarn – 设置 Host 处于维护模式时的警告状态
O 维护 – 设置 Host 处于维护模式时的 Critical 状态
+ 列表(虚拟机) – VMware 计算机及其状态的列表
+ 地位 – 总体对象状态 (灰/绿/红/黄)
+ 问题 – 主机的所有问题
b – 黑名单问题
^ 所有运行时信息(健康, 存储运行状况, Temperature 和 Sensor 表示为一个值,没有阈值)
* 服务 – 显示房东服务信息
+ (名字) – 检查由 (名字), 的语法 (名字):<服务1>,<服务 2>,…,<服务 N>
^ 显示所有服务
* 存储 – 显示主机存储信息
+ 适配器 – 列出总线适配器
b – 将适配器列入黑名单
+ 伦 – 列出 SCSI 逻辑单元
b – 将 LUN 列入黑名单
+ 路径 – 列出逻辑单元路径
b – 黑名单路径
^ 显示所有存储信息
* 正常运行时间 – 显示主机正常运行时间
o 快速统计 – switch 用于查询 PerfCounter 值或 Runtime info
* 装置 – 显示特定于主机的设备信息
+ CD/DVD 光盘 – 列出已连接 CD/DVD 驱动器的 VM
o listall – 列出所有可用设备(仅用于列表目的)
DC 专用 :
* 中央处理器 – 显示 CPU 信息
+ 用法 – CPU 使用率百分比
o 快速统计 – switch 用于查询 PerfCounter 值或 Runtime info
+ 用法MHZ – CPU 使用率 (MHz)
o 快速统计 – switch 用于查询 PerfCounter 值或 Runtime info
^ 所有 CPU 信息
o 快速统计 – switch 用于查询 PerfCounter 值或 Runtime info
* 内存 – 显示 MEM 信息
+ 用法 – MEM 使用百分比
o 快速统计 – switch 用于查询 PerfCounter 值或 Runtime info
+ usagemb – mem 使用量 (MB)
o 快速统计 – switch 用于查询 PerfCounter 值或 Runtime info
+ 交换 – 交换内存使用量 (MB)
+ 开销 – VM Server 使用的其他内存 (MB)
+ 整体 – VM Server 使用的总内存 (MB)
+ memctl – VM 内存控制驱动程序使用的 mem(vmmemctl) 控制气球
^ 所有 MEM 信息(除了 overall 和 no thresholds)
* 网 – 显示网络信息
+ 用法 – 总体网络使用情况 (KBps)(千字节/秒)
+ 收到 – 以 KBps 接收(千字节/秒)
+ 发送 – 以 KBps 格式发送(千字节/秒)
^ 所有网络信息(except usage 和 no thresholds)
* io – 显示磁盘 IO 信息
+ 中止 – Aborted Commands Count (中止的命令计数)
+ 重 置 – 总线重置计数
+ 读 – 读取延迟(毫秒) (totalReadLatency.average)
+ 写 – 写入延迟(毫秒) (totalWriteLatency.average)
+ 内核 – 内核延迟(毫秒)
+ 装置 – 设备延迟(毫秒)
+ 队列 – 队列延迟(毫秒)
^ 所有磁盘 IO 信息
* VMFS – 显示数据存储信息
+ (名字) – 名称为 的 Datastore 的可用空间信息 (名字)
o 已使用 – 输出已用空间而不是可用空间
o 简介 – 仅列出警报卷
o 正则表达式 – 是否将 name 视为 regexp
o 黑名单正则表达式 – 是否将黑名单视为 regexp
b – 将 VMFS 列入黑名单
T (价值) – timeshift 更改为 detemine(如果我们需要刷新)
^ 所有数据存储信息
o 已使用 – 输出已用空间而不是可用空间
o 简介 – 仅列出警报卷
o 黑名单正则表达式 – 是否将黑名单视为 regexp
b – 将 VMFS 列入黑名单
T (价值) – timeshift 更改为 detemine(如果我们需要刷新)
* 运行 – 显示运行时信息
+ 列表(虚拟机) – VMware 计算机及其状态的列表
+ listhost (列表主机) – VMware ESX 主机服务器列表及其状态
+ listcluster – VMware 集群及其状态列表
+ 工具 – VMware Tools 状态
b – 将 VM 列入黑名单
+ 地位 – 总体对象状态 (灰/绿/红/黄)
+ 问题 – 主机的所有问题
b – 黑名单问题
^ 所有运行时信息(除了 cluster 和 tools 并且没有阈值)
* 建议 – 显示对群集的建议
+ (名字) – 对名称为 的集群 (名字)
^ 所有群集建议
集群特定 :
* 中央处理器 – 显示 CPU 信息
+ 用法 – CPU 使用率百分比
+ 用法MHZ – CPU 使用率 (MHz)
^ 所有 CPU 信息
* 内存 – 显示 MEM 信息
+ 用法 – MEM 使用百分比
+ usagemb – mem 使用量 (MB)
+ 交换 – 交换内存使用量 (MB)
o listvm – 打开/关闭交换 VM 的输出列表
+ memctl – VM 内存控制驱动程序使用的 mem(vmmemctl) 控制气球
o listvm – 打开/关闭膨胀 VM 的输出列表
^ 所有 MEM 信息(加上开销,无阈值)
* 簇 – 显示 Cluster Services 信息
+ effectiveCPU 的 – 集群内所有主机的总可用 CPU 资源
+ 有效 MEM – 集群中所有主机的机器内存总量
+ 故障转移 – 可以容忍的 VMware HA 故障数
+ 中央处理器公平性 – 分布式 CPU 资源分配的公平性
+ memfairness (内存公平性) – 分布式 MEM 资源分配的公平性
^ 群集服务仅 effectiveCPU 和 effectivemem 值
* 运行 – 显示运行时信息
+ 列表(虚拟机) – 群集中的 VMware 计算机列表及其状态
+ listhost (列表主机) – 群集中的 VMware ESX 主机服务器列表及其状态
+ 地位 – 总体集群状态 (灰/绿/红/黄)
+ 问题 – 集群的所有问题
b – 黑名单问题
^ 所有集群运行时信息
* VMFS – 显示数据存储信息
+ (名字) – 名称为 的 Datastore 的可用空间信息 (名字)
o 已使用 – 输出已用空间而不是可用空间
o 简介 – 仅列出警报卷
o 正则表达式 – 是否将 name 视为 regexp
o 黑名单正则表达式 – 是否将黑名单视为 regexp
b – 将 VMFS 列入黑名单
T (价值) – timeshift 更改为 detemine(如果我们需要刷新)
^ 所有数据存储信息
o 已使用 – 输出已用空间而不是可用空间
o 简介 – 仅列出警报卷
o 黑名单正则表达式 – 是否将黑名单视为 regexp
b – 将 VMFS 列入黑名单
T (价值) – timeshift 更改为 detemine(如果我们需要刷新)[/源代码]