使用 Metricbeat 在 Elasticsearch 中收集 Windows 指标并使用 Grafana 进行可视化

在这篇文章中,我们将介绍 Elasticsearch 的另一个出色组件, 在 Beats 软件包中,我们还将找到一个实用程序,它可以帮助我们从 Windows 或 Linux 计算机处理和收集指标, 称为 Metricbeat. 我们将了解如何将这些指标导出到 Logstash 进行处理,并将其存储在 Elasticsearch 中,以便稍后使用 Kibana 或 Grafana 进行可视化!
不错, 我们必须让 Metricbeat light 代理在要从中吸收其指标的计算机中安装并运行, 是 Windows 操作系统计算机, Linux 或 Mac OS. 我们从以下网址下载 Metricbeat https://www.elastic.co/downloads/beats/metricbeat, 我们将解压缩它并 , (例如) 我们把它留在 ' C:\Program Filesmetricbeat'. 我们将拥有名为 'metricbeat.yml' 的配置文件和另一个参考文件,其中包含我们可以使用的所有选项, 称为“metricbeat.reference.yml”. 在此示例中,我们将了解如何在 Windows 计算机上收集 CPU 等基本指标, 记忆, 磁盘或网络, 但是,如果您运行一个有趣的服务,我们将启用相应的模块来收集所述数据. 我们将下载 Metricbeat, 我们将对其进行设置并将其作为服务进行安装.
配置 Metricbeat,
井, 开始播放 Metricbeat 配置文件之前; 在文件夹 'modules.d 中’ 我们将拥有所有其他模块,我们还可以从中获取指标, 是 Web 服务, 数据库, 虚拟平台, 例如 Apache, 蒙戈布斯, MySQL 的, vSphere (虚拟平台), PostgreSQL 数据库… 在每个模块中,我们可以启用或多或少的指标.
在此示例中, 在 'system.yml’ 我们将看到它将重定向每个 10 seconds CPU 指标, 记忆, 网络或流程信息等, 我们可以评论或取消注释我们需要的内容, 我们可以定义这个模块或我们感兴趣的模块,指定我们有兴趣收集的信息. 稍后我们将了解如何启用我们感兴趣的模块, 否则,它们将具有 '.disabled' 扩展名.
[源代码]- 模块: 系统
时期: 10s
度量集:
– 中央处理器
#- 负荷
– 记忆
– 网络
– 过程
– process_summary
#- 核心
#- Diskio
#- 插座
process.include_top_n:
by_cpu: 5 # 包括顶部 5 按 CPU 划分的进程数
by_memory: 5 # 包括顶部 5 按内存划分的进程
– 模块: 系统
时期: 1m
度量集:
– 文件系统
– FSSTAT
处理器:
– drop_event.when.regexp:
system.filesystem.mount_point: ‘^/(SYS (英语)|cgroup|处理|开发|等|主机|自由)($|/)’
– 模块: 系统
时期: 15m
度量集:
– 正常运行时间[/源代码]
后, 在配置文件 'metricbeat.yml’ 我们将执行其余的配置, 在 常规===== 部分=====我们可以添加标签或其他字段,以防我们有兴趣将设备的 Metricbeat 与不同的关键字相关联, 以便它们可以用于不同的搜索, 如何指示它是否为 Server, 是数据库或 Web 服务器, 或拥有 IIS, 你的 SO...
[源代码]标签: ["Servidor", "Windows 2016 R2", "OS-DC-01"]
领域:
globo_environment: 生产[/源代码]
在 Output (输出) 部分, 我们将能够将数据直接发送到 Elasticsearch, 但就像在其他帖子中一样, 我特别喜欢将数据发送到 Logstash 进行处理. 因此,我们将讨论针对 Elasticsearch 的 Output 的整个部分,并针对 Logstash 服务器及其端口进行配置, 那个在 以前的文档 我们在 “配置 Logstash” 要创建的文件. 正如我所说,我们触及输出,留下如下内容:
[源代码]#——— Logstash 输出 ———
输出.logstash:
# Logstash 主机
#主机: ["localhost:5044"]
主机: ["DIRECCION_IP_LOGSTASH:5044"][/源代码]
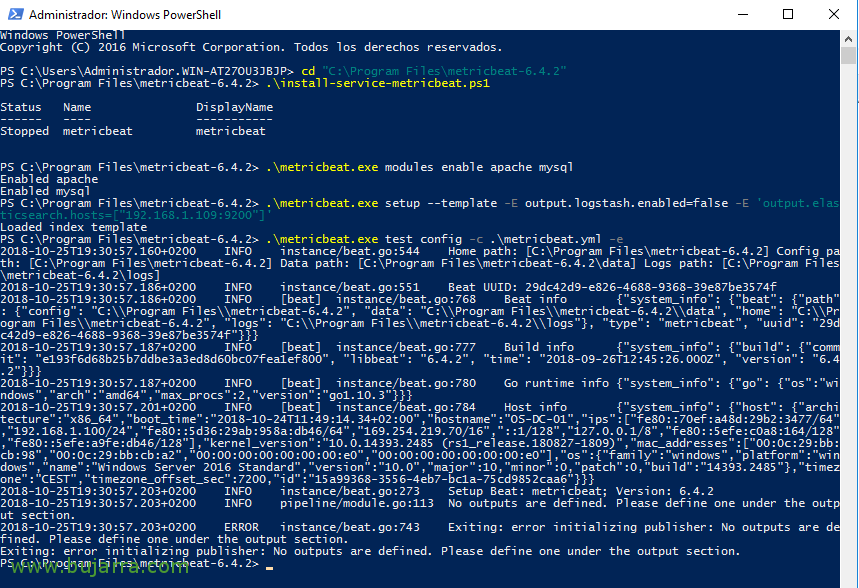
设置 Metricbeat 后, 将 Metricbeat 安装为我们运行的服务:
[源代码].\install-service-metricbeat.ps1 中[/源代码]
歌词大意: 我说的, 如果我们想对我们的机器进行额外的监控,我们可以启用特定的模块, 在这个服务器上,我有一个 MySQL 和一个 Apache, 您应该启用它们:
[源代码].\metricbeat.exe 模块支持 Apache MySQL[/源代码]
照常, 我们首次向 Elasticsearch 添加 Metricbeat 指标, 我们必须加载模板,以便它正确生成包含字段的索引:
.\metricbeat.exe设置 –模板 -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=[“SERVIDOR_ELASTICSEARCH:9200”]’
我们可以测试是否正确配置了配置文件, 从具有管理员权限的 PowerShell, 让我们来看看我们有 Metricbeats 的路径, 我们执行:
[源代码].\metricbeat.exe test config -c .metricbeat.yml -e[/源代码]
然后我们开始服务,如果我们愿意,, 我们可以看到 Metricbeats 与 Logstash 或 Elasticsearch 的连接状态 (这取决于我们选择了什么):
[源代码]Start-Service 指标节拍
获取内容 .logsmetricbeat -wait[/源代码]
就是这样! 我们应该已经让 Metricbeat 收集指标了! 现在让我们可视化它们… 魔法即将来临!
从 Kibana 出发,
如果我们想使用 Kibana 可视化指标, 首先,我们将创建索引模式, 然后我们将验证数据是否到达,然后我们可以开始绘制!
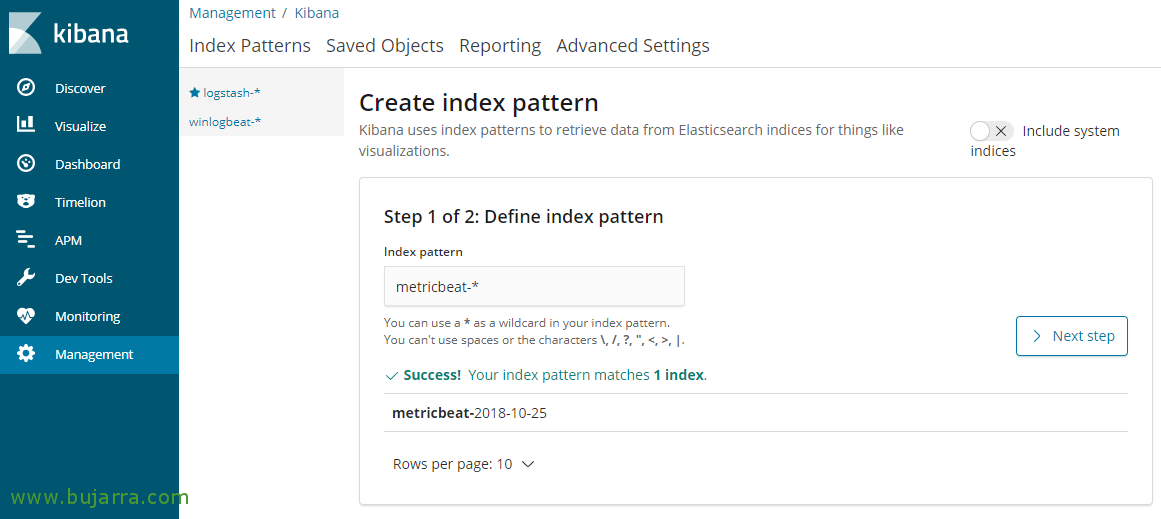
我们打开 Kibana, 我们将 “管理” > “索引模式” > “创建索引模式” 并指示 'metricbeat-*’ 作为模式, 点击 “下一步”,
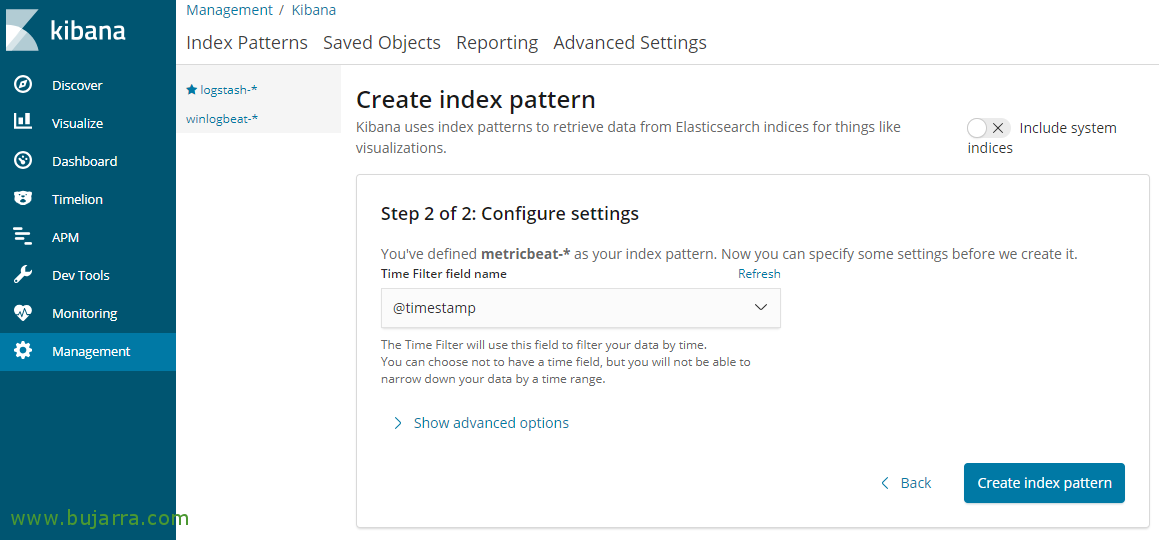
选择 ‘@timestamp‘ 作为时间列,并从中创建模式 “创建索引模式”.
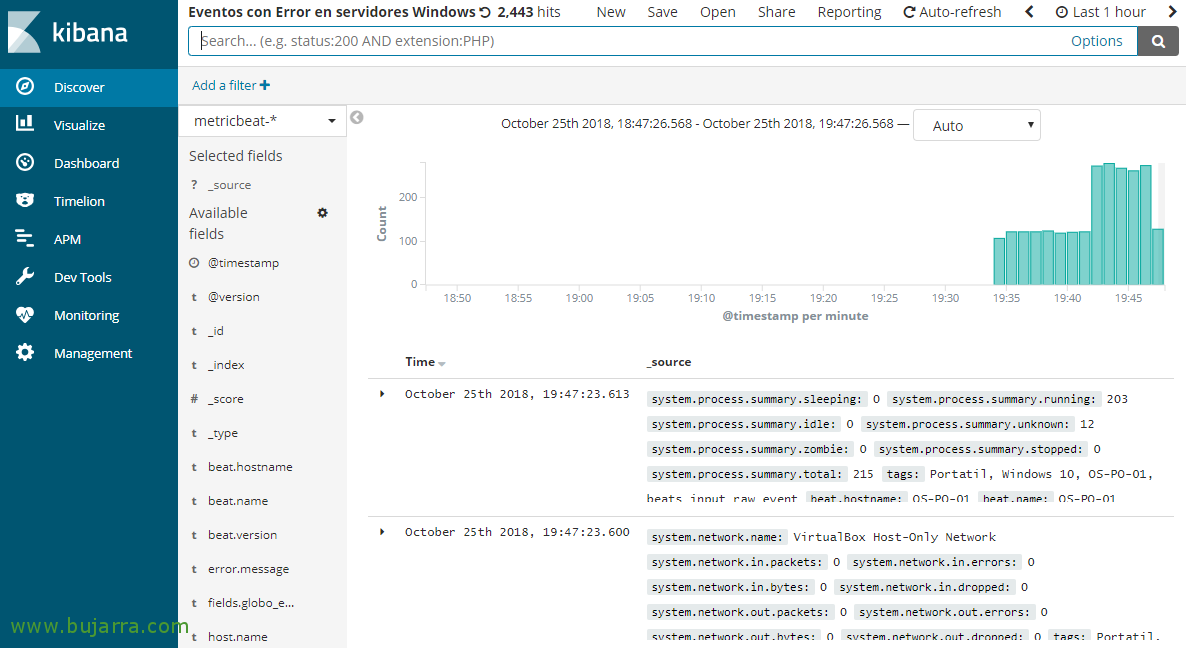
和 从 “发现”, 通过选择我们刚刚创建的模式,我们将能够看到我们正在接收数据, 照常, 我们可以看到从这里到我们会发生什么, 播放以添加列并创建筛选器,然后从中创建可视化 “可视 化” 并查看我们正在实时监控的指标,但采用图表格式, 僵局, 列, 奶酪…
从 Grafana 出发,
在可视化数据之前, 请记住,我们必须注册数据源并将 Grafana 与 Elasticsearch 中的 Metricbeat 索引连接起来!
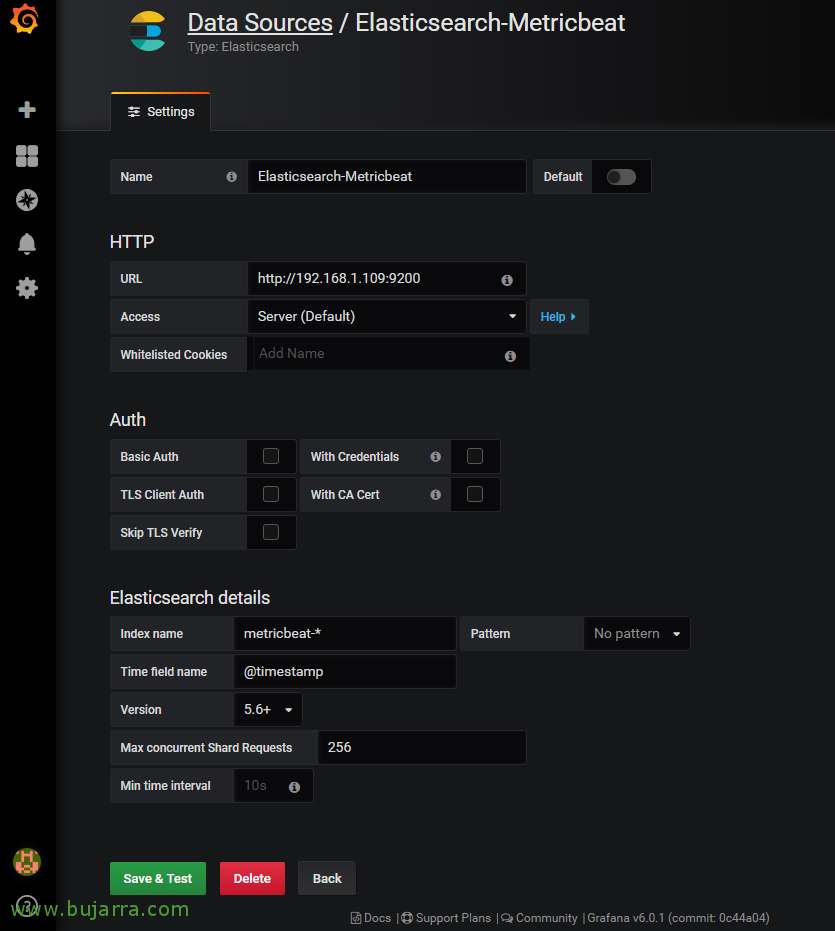
我们开设了 Grafana, 让我们转到“设置” > “数据源”, 我们将为连接命名, 在 URL 中,我们必须指示 Elasticsearch 的 URL“http://DIRECCION_IP_ELASTIC:9200’. 选择 'metricbeat-*' 用作索引的名称, 我们将 Time 字段的 @timestamp 字段指定,并选择 Elasticsearch 版本, 点击“保存” & 测试”,
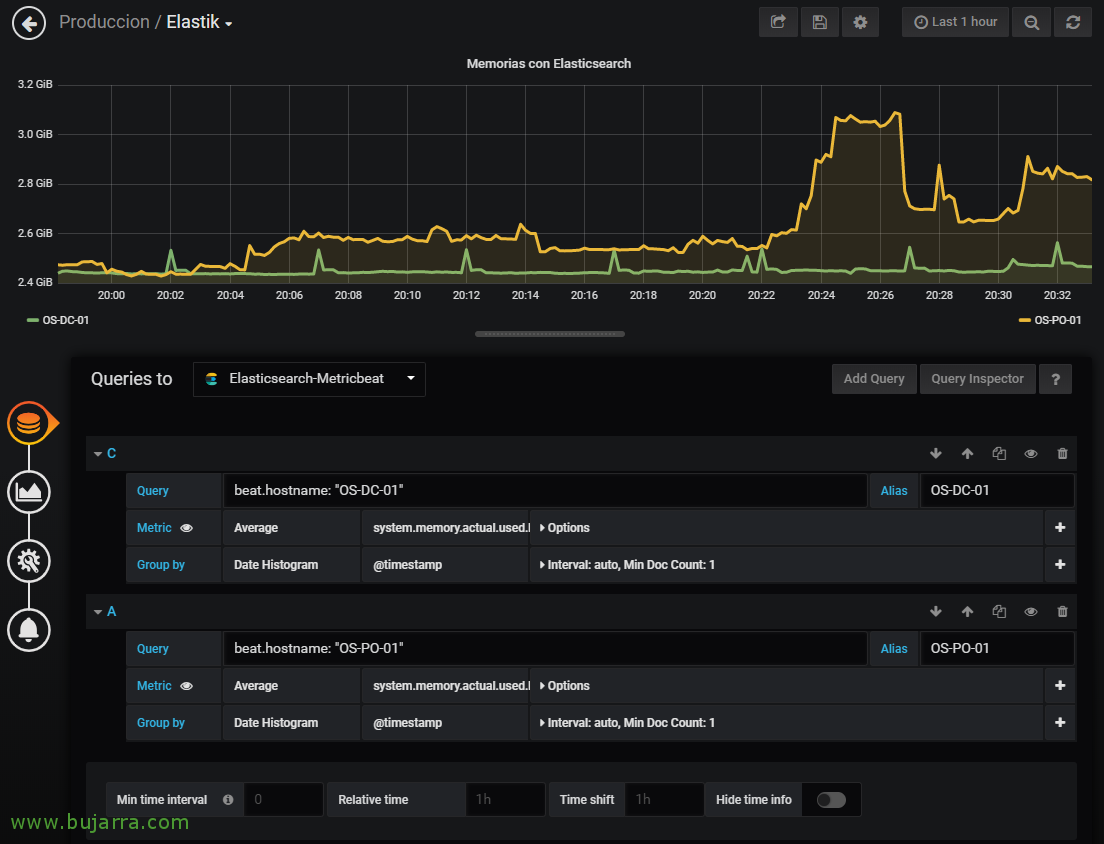
我们可以在 Dashboard 中添加仪表板,以可视化安装了 Metricbeat 的计算机生成的指标! 在示例仪表板中, 在这种情况下,它将是一个折线图, 我们将在其中可视化几台机器生成的所有指标. 我们根据 Elasticsearch 中的 Metricbeat 索引选择连接器, 我们可以从这里使用 Lucene 查询来可视化我们感兴趣的内容.
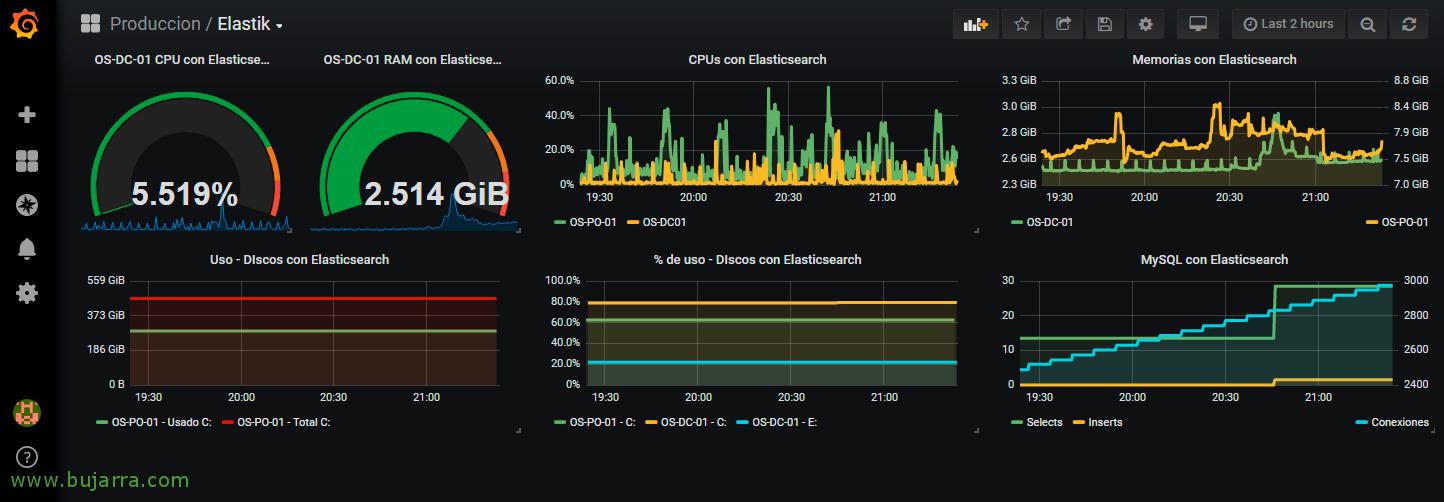
什么都没有, 稍后,我们将能够分析哪些数据到达我们手中,以及如何使用 Grafana 呈现和绘制数据, 您将看到它并不那么复杂,我们可以以非常愉快的方式可视化我们收集的任何信息, 我希望你觉得它很有趣!