在 Grafana 或 Kibana 中查看 Meerkat 记录

观看后 我们如何安装 Meerkat 并使其正常运行, 现在是时候以更友好的方式处理数据并对其进行可视化了, 为此,我们将依靠 Grafana 作为可视化工具, 尽管使用 Kibana,您可以以相同的方式执行此操作 (或更简单). 这一切都归功于我们将 Meerkat LOG 存储在 Elasticsearch 中.
过程非常简单, 在运行 Suricata 的机器上,我们将安装 Filebeat 来收集日志文件并将其直接发送到 Elasticsearch, 之后,我们将启用 meerkat 模块并对其进行配置. 一旦我们准备好了, 我们的 Elasticsearch 是否应该开始存储这些日志, 并与 Grafana 一起能够利用它们, 或使用 Kibana, 去.
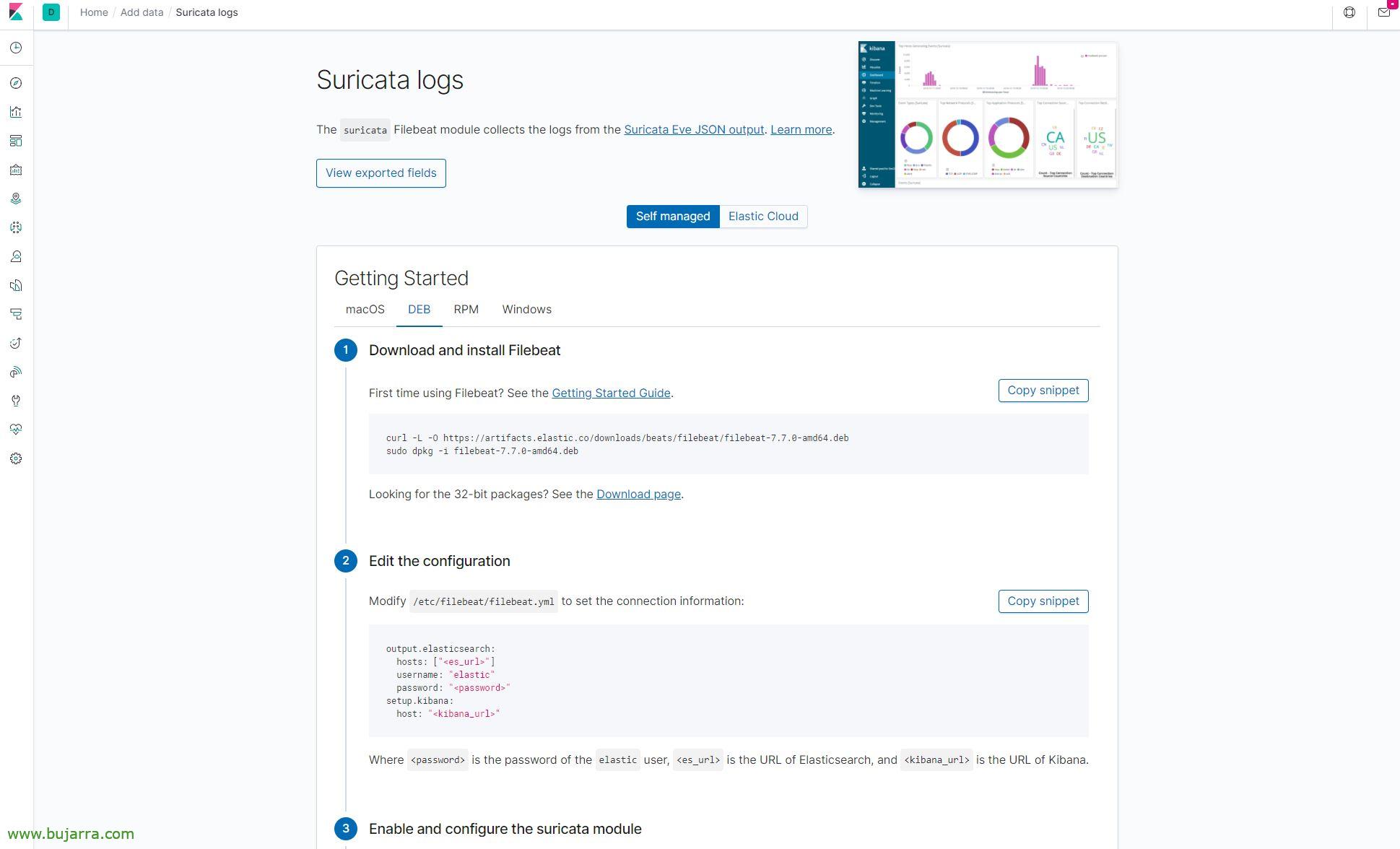
我们打开 Kibana, 在左侧菜单中,我们转到 “总是” > “使用 Beats 添加数据” > “Meerkata 原木” 它将为我们提供我们需要的所有细节. 此 URL 为: HTTP 协议://IP_ELASTIC_SEARCH:5601/app/kibana#/home/tutorial/smericaLogs
我们将自己定位在 “DEB” (就我而言, 因为 Meerkata 在 Debian Buster 下运行) 正如我们所看到的,它得到了完美的解释.
安装 Filebeats:
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.7.0-amd64.deb dpkg -i filebeat-7.7.0-amd64.deb
编辑 Filebeat 配置文件 (/etc/filebeat/filebeat.yml), 我们将指示要在 Elasticsearch 中使用的索引的名称, 以及如果我们有 Kibana 并且我们想要导入默认仪表板:
#================ Elasticsearch 模板设置 ====================
...
setup.template.name: "猫 鼬"
setup.template.pattern: "猫 鼬-*"
setup.dashboards.index: "猫 鼬-*"
setup.ilm.enabled: 假
...
setup.kibana:
主机: "FQDN_O_DIRECCION_IP_KIBANA:5601"
...
#---------------------- Elasticsearch 输出 ------------------------
输出.elasticsearch:
# 要连接到的主机数组.
主机: ["FQDN_O_DIRECCION_IP_ELASTICSEARCH:9200"]
指数: "猫鼬-%{+yyyy.MM.dd}"
...
我们启用 Meerkat 模块, 我们在 Kibana de Meerkata 中创建了一些 preDeternubadis 仪表板, 我们启动 Filebeat 守护程序并使其与系统一起自动启动.
filebeat modules enable meerkat filebeat setup systemctl start filebeat systemctl enable filebeat.service systemctl status filebeat

无需执行任何其他操作,我们就可以转到 Kibana 的仪表板或其可视化,并查看它从我们这里收集的数据.

如果我们想在 Grafana 中可视化它, 与往常一样,我们必须创建一个指向 Elasticsearch 的 Meerkat 索引的数据源,我们将能够制作我们认为合适的图表, 使用简单的查询,就像我们从 Kibana 的 Discover 中所做的那样, 想象力带来力量!

什么都没有, 到 5 在几分钟之内,您将能够制作出如此简单的仪表板,让您能够快速可视化正在发生的事情, 哪些计算机访问哪些, View 连接, 等…