Installazione di Elasticsearch

Oggi iniziamo con il primo di tutti, un documento dove vedremo i passaggi necessari per implementare completamente Elasticsearch, che sarà il nostro data warehouse per archiviare i log o le metriche dell'attrezzatura, e poi attacca con Kibana o Grafana per visualizzarlo!
È gratuito, è Open Source e basato su Java. È responsabile della memorizzazione dei dati che gli inviamo e dell'esecuzione delle ricerche (molto veloce) delle informazioni che abbiamo memorizzato. Come possiamo capire, è il cuore dell'Elastic Stack!

Elasticsearch è uno degli strumenti più utilizzati ultimamente in tutti i tipi di architetture, e soprattutto lato DevOps, Viene utilizzato allo scopo di cercare grandi quantità di dati, come è BigData 😛 È un server di ricerca basato su Lucene, fornisce un motore di ricerca full-text, distribuito e multi-tenant utilizzando un'interfaccia web RESTful e documenti JSON.
Per quanto riguarda i requisiti, Sarà una macchina che dipenderà da ogni scenario come è ovvio, Pensa che richiederà molto disco per archiviare tutto ciò che gli inviamo, avrai bisogno di un minimo 1-2vCPU con 4Gb di RAM, si consiglia di mettere 4vCPU e 8GB di RAM, Ma vedrai; proprio come l'album, che 40Gb possiamo riempirli facilmente.
Installare Elasticsearch,
Avviato! basiamo l'installazione su una macchina con Ubuntu 18.10 che abbiamo aggiornato e configurato con un indirizzo IP statico. Il processo di installazione è piuttosto rapido. Iniziamo installando prima i requisiti di OpenJDK:
[Codice sorgente]apt-get install openjdk-8-jre-headless java -version[/Codice sorgente]
E scarica l'ultimo pacchetto Elasticsearch che vogliamo installare, Nel caso di questo post utilizziamo un 6.4.2, Procediamo all'installazione:
[Codice sorgente]wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.6.1.deb dpkg -i elasticsearch-6.6.1.deb[/Codice sorgente]
Modifichiamo il file di configurazione principale di Elasticsearch '/etc/elasticsearch/elasticsearch.yml’ e abbiamo modificato almeno i seguenti post, che definirà il nome del cluster, il nome di questo nodo e il suo indirizzo IP con cui fornirà il servizio.
[Codice sorgente]cluster.name: Nombre_Cluster node.name: Nombre_Servidor network.host: Dirección_IP_servidor[/Codice sorgente]
Dovremo modificare la variabile di sistema 'vm.max_map_count’ per darti più memoria virtuale:
[Codice sorgente]sysctl -w vm.max_map_count=262144[/Codice sorgente]
Lanciamo il servizio Elasticsearch e lo configuriamo per avviarlo correttamente:
[Codice sorgente]Servizio ElasticSearch Start SystemCTL Abilita ElasticSearch[/Codice sorgente]
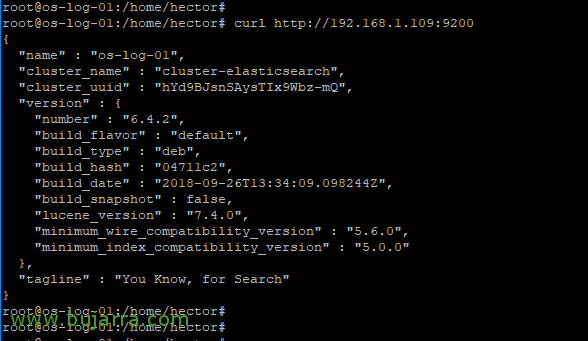
Se tutto è andato bene, Saremo in grado di testarlo e verificare se il servizio è in esecuzione:
[Codice sorgente]Curl HTTP://Dirección_IP:9200[/Codice sorgente]