

Ollama, Introduzione all'intelligenza artificiale locale

Per alcuni mesi ho armeggiato con un'intelligenza artificiale locale e open source; E volevo condividere un po' con voi in una serie di post alcune delle sue possibilità nella nostra quotidianità. Ma in questo primo documento vedremo come possiamo impostarlo e alcune nozioni di base sulle sue possibilità.
Operazioni preliminari, Se ti va, ti dirò per cosa lo uso oggi nel caso possa servire come idea; Per ora, esclusivamente per generare testo, Può essere povero, Ma è un mondo molto vasto. Che vanno dalla ricezione di qualsiasi notifica o sistema di avviso, L'avviso ti rende più umano o può suggerire da dove iniziare la sua risoluzione. Per inviare e-mail periodiche, E-mail inviate quotidianamente dalla mia organizzazione, Mensile… Beh, dà loro un altro tocco, li alimenta con determinati dati e li rende molto reali. Anche per l'impianto domotico, mi permette di avere conversazioni con la Home, Mi avvisa, Utilizzo della voce, Frasi diverse…
Per ora, Come ho detto, per generare testo; Ma le possibilità sono molte, come il collegamento a database e che ci permette di effettuare query con un linguaggio naturale. Oppure la possibilità di impegnarsi in conversazioni e domande riguardanti un documento che abbiamo inviato all'IA, o un'immagine e che descriva ciò che vede… In tutto il documento darò alcuni semplici esempi in modo che si possa fare qualcosa di piacevole.

Il secondo, Non male, Come si chiama… Come puoi immaginare, ci sono molte opzioni e possibilità, Ti parlerò di Ollama (Libreria open source per modelli e applicazioni di intelligenza artificiale). Ollama ci permetterà di utilizzare LLM (Modello linguistico di grandi dimensioni), Questo è, modelli linguistici addestrati per l'intelligenza artificiale, Possono essere open source o a pagamento, Può essere 100% offline o no, quanto basta. Ovviamente, e a seconda dell'LLM che utilizziamo, avremo bisogno di più o meno potenza, Questo è, avere una GPU in modo che le risposte siano immediate. Saremo in grado di utilizzare l'API Ollama per porre domande da remoto con altri sistemi, Molto molto potente. E ti raccomando Apri WebUI come interfaccia GUI per Ollama, quindi con il nostro browser avremo l'interfaccia che ti aspetti di poter lavorare comodamente con la tua IA.
Cosa ho detto, avremo bisogno di una GPU per avere le migliori prestazioni possibili, dipenderà dall'LLM che utilizziamo e dai GB richiesti da ciascun modello, In questo modo le risposte saranno immediate. Per quanto riguarda l'hardware compatibile, è piuttosto ampio (NVIDIA, AMD, Mela M1…), Ti lascio Ecco il suo elenco.
Ho intenzione di separare l'articolo in:
- Installazione rapida di Ollama e Open WebUI su Windows, Mac o Linux
- Installazione di Ollama e Open WebUI su un MV Linux su Proxmox con Docker
- Accesso tramite Open Web UI e guida introduttiva
- Riconoscimento delle immagini
- Interazione con i documenti
- Parecchi
Installazione rapida di Ollama e Open WebUI su Windows, Mac o Linux
Se vuoi dimostrarlo, E veloce ora, Questa è l'opzione, poiché sarai in grado di installare Ollama sul tuo Linux, Mac o Windows, Nel caso in cui si desideri eseguirlo localmente, con la tua GPU. Andremo al Sito web per scaricare Ollama, selezioneremo il nostro sistema operativo e lo scaricheremo su di noi, Prossimo, Successivo e installato.
Su Linux lo scaricheremo e lo installeremo come segue:
ricciolo -fsSL https://ollama.com/install.sh | Zitto >>> Scaricare ollama... ######################################################################## 100,0%##O#- # >>> Installazione di ollama in /usr/local/bin... >>> Creazione dell'utente ollama ... >>> Aggiunta dell'utente ollama al gruppo di rendering... >>> Aggiunta di un utente ollama al gruppo video... >>> Aggiunta dell'utente corrente al gruppo di ollama.. >>> Creazione del servizio systemd ollama ... >>> Abilitazione e avvio del servizio ollama.. Creato il collegamento simbolico /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service. >>> GPU NVIDIA installata.
E possiamo scaricare direttamente un LLM e provarlo se vogliamo dalla shell:
Ollama Run Mistral Pulling Manifest Pulling E8A35B5937A5... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 4.1 GB che tira 43070e2d4e53... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 11 KB che tira e6836092461f... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 42 B tirando ed11eda7790d... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 30 B che tira f9b1e3196ecf... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 483 B verifica del manifesto di scrittura del digest sha256 che rimuove tutti i livelli inutilizzati >>> Ciao, ciao! Ciò significa che "Ciao" in spagnolo.
Se vogliamo che risponda alle query API, dobbiamo modificare il file di servizio 'nano /etc/systemd/system/ollama.service ‘ Somma:
Ambiente="OLLAMA_HOST=0.0.0.0:11434"
E ricarichiamo il servizio:
sudo systemctl daemon-reload sudo systemctl restart ollama
E se vogliamo avere la GUI per gestire la nostra IA dal browser, dovremo configurare Open WebUI, il più veloce e conveniente in un container Docker:
git clone https://github.com/open-webui/open-webui.git CD open-webui/ sudo Docker compose up -d

E possiamo aprire il browser attaccando l'IP della macchina alla porta 3000tcp (Default).
Installazione di Ollama e Open WebUI su un MV Linux su Proxmox con Docker
E questa parte ti dico perché… La mia idea è quella di avere una macchina per l'IA centralizzata, una macchina a cui diversi sistemi possono puntare per effettuare query diverse, per questo, Deve essere una macchina virtuale (A proposito di vantaggi, Alta disponibilità, Backup, Istantanee…), una VM a cui passiamo la scheda grafica e ha la GPU per essa. Per questo useremo Proxmox, (un giorno abbiamo parlato del suicidio di VMware) e la VM sarà un server Ubuntu 24.04. E già che ci siamo,, in quella VM eseguirà Ollama e Open WebUI in contenitori Docker.
Ecco i passaggi che ho seguito per passare attraverso la scheda grafica in Proxmox, Non so se sono i più corretti, ma funziona perfettamente.
Dopo l'installazione di Proxmox 8.2, Configuralo minimamente, aver eseguito il Proxmox VE Post Install degli script helper Proxmox VE, diremo a Proxmox di non utilizzare quella grafica PCIe, abbiamo iniziato a modificare GRUB con 'nano /etc/default/grub’ e modifichiamo la seguente riga:
#GRUB_CMDLINE_LINUX_DEFAULT="tranquillo" GRUB_CMDLINE_LINUX_DEFAULT="Tranquillo intel_iommu=ON IOMMU=PT vfio_iommu_type1 initcall_blacklist=sysfb_init" INTEL--> GRUB_CMDLINE_LINUX_DEFAULT="silenzioso intel_iommu=acceso" AMD--> GRUB_CMDLINE_LINUX_DEFAULT="silenzioso amd_iommu=acceso"
E noi eseguiamo
update-grub
Abbiamo aggiunto i seguenti moduli con 'nano /etc/modules':
Vivo vfio_iommu_type1 vfio_pci vfio_virqfd
Blocchiamo i driver con 'nano /etc/modprobe.d/blacklist.conf':
Blacklist Nouveau Blacklist NVIDIA Blacklist NVIDIA* Blacklist Radeon
Annotiamo gli ID con: 'spci -n -s 01:00’, Come puoi vedere, Se c'è qualche persona curiosa, nel mio caso è una NVIDIA RTX 3060 12GB collegati a PCIe 1.
01:00.0 0300: 10di:2504 (Giro A1) 01:00.1 0403: 10di:228e (Giro A1)
Modifichiamo 'nano /etc/modprobe.d/vfio.conf’
Opzioni KVM ignore_msrs=1x Opzioni vfio-pci ids=10de:2504,10di:228e disable_vga=1
Modifichiamo 'nano /etc/modprobe.d/kvm.conf’
Opzioni KVM ignore_msrs=1
E infine abbiamo modificato 'nano /etc/modprobe.d/iommu_unsafe_interrupts.conf’
Opzioni vfio_iommu_type1 allow_unsafe_interrupts=1"
Ti sto dicendo che sono sicuro che mi rimarrà un passaggio per il passthrough della scheda grafica in Proxmox, ma dopo aver riavviato l'host vedrai come puoi aggiungere perfettamente la GPU a una VM.

Il passo successivo, sarà quello di creare la VM in Proxmox, Ecco alcune cose che avevo in mente; nella scheda "Sistema"’ Dobbiamo indicare 'Q35’ come tipo di macchina, e nelle opzioni del BIOS scegli 'OVMF (UEFI)’,
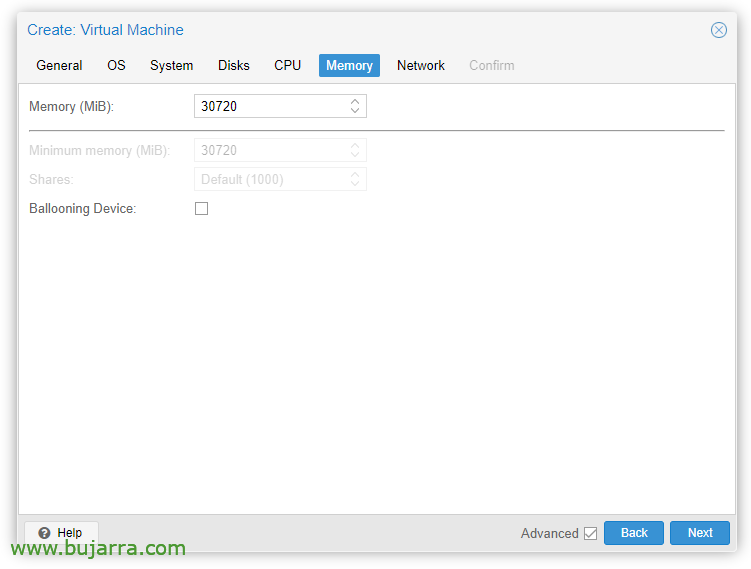
Nella scheda "Memoria"’ dobbiamo deselezionare 'Dispositivo di palloncino’
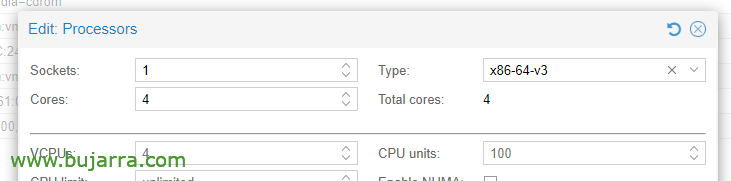
In Opzioni CPU, Modifica dei processori, nel tipo, Dobbiamo scegliere almeno x86-64-v3.
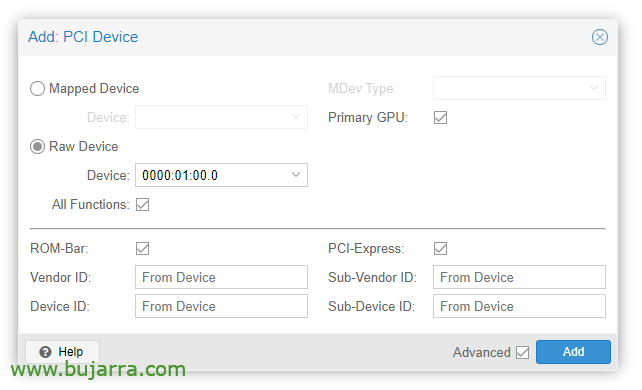
Una volta creata la VM, possiamo aggiungervi un dispositivo PCI, modifichiamo l'hardware della VM e “Aggiungere” > “Periferica PCI”. Controlliamo tutte le funzioni, Barra ROM, GPU primaria e PCI-Express.
Ovviamente in quella scheda grafica collegheremo un monitor per installare il sistema operativo (Ubuntu Server 24.04) e guardalo sullo schermo. Dovremo anche passare attraverso una tastiera/mouse USB per eseguire l'installazione.
Quindi possiamo installare il sistema operativo nella VM, Dobbiamo prendere in considerazione l'installazione dei driver, in Ubuntu Desktop penso che siano installati durante l'installazione e nel server segnando anche un 'segno di spunta', altrimenti, possiamo ancora installarli:
sudo ubuntu-drivers install sudo apt-get update sudo apt-get upgrade sudo reboot
Tras reiniciar la MV vemos si ha cargado correctamente con 'cat /proc/driver/nvidia/version’
Versione NVRM: Modulo kernel NVIDIA UNIX x86_64 535.171.04 Tue Mar 19 20:30:00 UTC 2024 Versione GCC:
Continuaríamos con la instalación de Docker (Doc Oficial) en la MV Ubuntu:
sudo apt-get update sudo apt-get install ca-certificates curl sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc sudo chmod a+r /etc/apt/keyrings/docker.asc echo \ "deb [arco=$(dpkg --architettura-stampa) firmato=/etc/apt/portachiavi/docker.asc] https://download.docker.com/linux/ubuntu \ $(. /rilascio etc/os && ECO "$VERSION_CODENAME") stalla" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
Debemos instalar ahora el NVIDIA Container Toolkit (Doc Oficial) y lo habilitamos para Docker:
ricciolo -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [firmato=/usr/condividi/portachiavi/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list sudo apt update sudo apt -y install nvidia-container-toolkit sudo systemctl restart docker sudo nvidia-ctk runtime configure --runtime=docker sudo systemctl restart docker
Y ya es hora de desplegar los contenedores de Ollama y Open WebUI, per questo:
git clone https://github.com/open-webui/open-webui.git cd open-webui/
Y le añadimos estos cambios al contenedor de Ollama, in modo da poter utilizzare il grafico e aprire la porta per le API (Nano docker-compose.yaml):
Runtime: Ambiente NVIDIA: - NVIDIA_VISIBLE_DEVICES=tutte le porte: - 11434:11434
E finalmente scarichiamo e avviamo i container:
sudo docker compose up -d
E poi possiamo aprire il browser attaccando l'IP della macchina virtuale, alla porta 3000tcp (Default).
Accesso tramite Open Web UI e guida introduttiva

La prima volta che accediamo a Open WebUI possiamo creare un account cliccando su “Iscriversi”, Creeremo un account semplicemente inserendo il nostro nome, e-mail e password, Clicca su “Crea un account”.

E da qui sarà da dove potremo interagire, come possiamo vedere possiamo creare nuove Chat e consultarle con ciò di cui abbiamo bisogno,
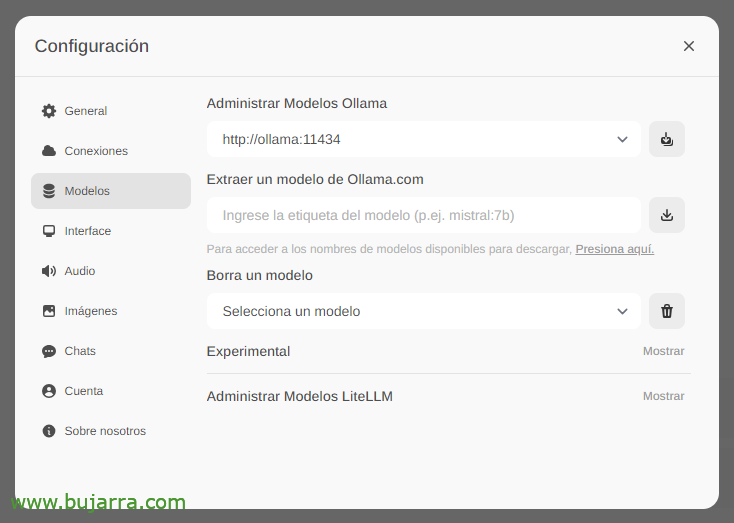
La prima e più importante cosa sarà scaricare i modelli linguistici di grandi dimensioni (LLM), da 'Impostazioni'’ > «Modelli’ Possiamo estrarli direttamente da Ollama.com digitiamo, ad esempio, Mistral:7b, anche se ovviamente vi consiglio di visitare il top LLM più utilizzato, Tutto quello che devi fare è digitare il modello che ti interessa e cliccare sull'icona di download. Ti consiglio (fino ad oggi) lama3, È un vero spasso.
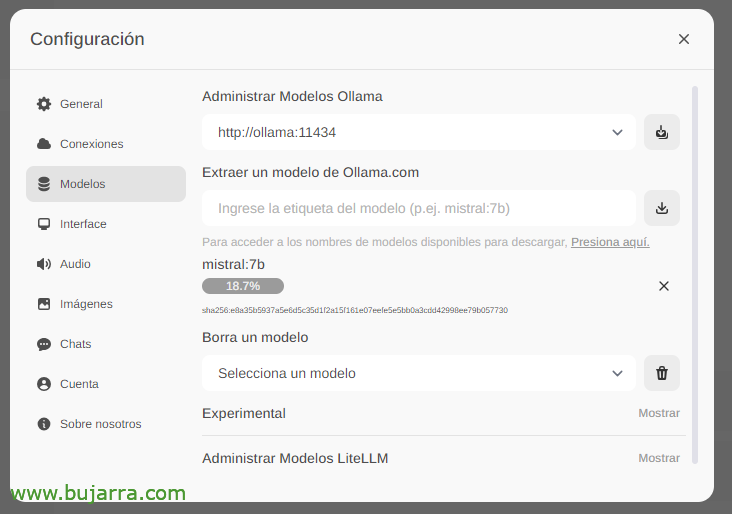
Aspettiamo che venga scaricato… E naturalmente possiamo scendere quanti ne vogliamo.
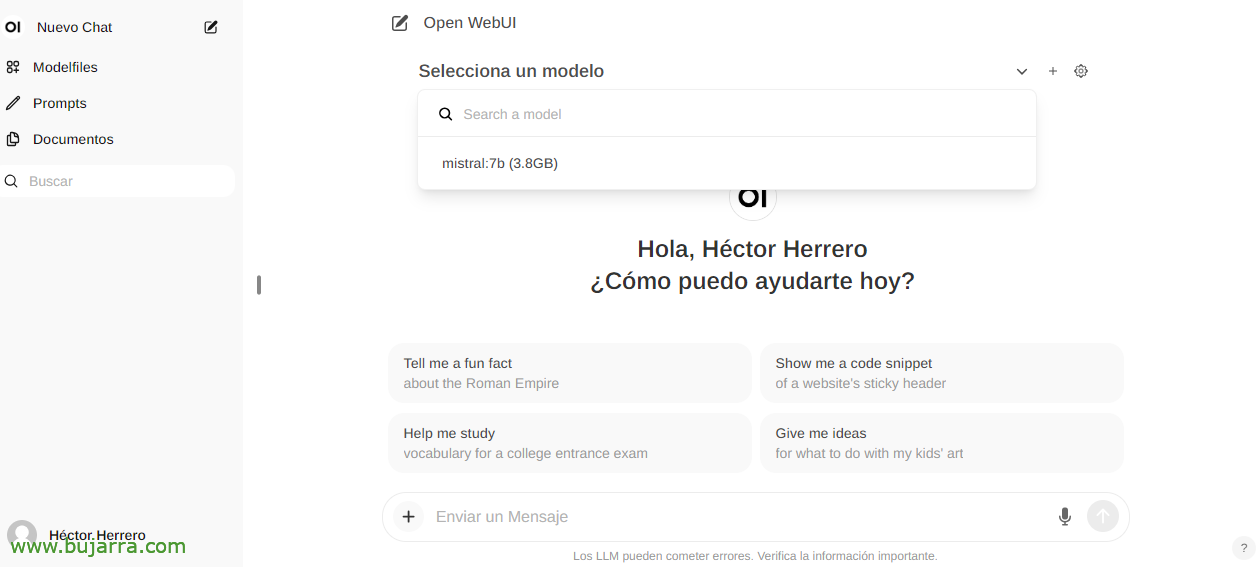
E quando crei una nuova chat, puoi scegliere qualsiasi modello scaricato per iniziare a interagire.

E niente, Abbiamo iniziato ad armeggiare, Possiamo farti qualsiasi domanda….
Riconoscimento delle immagini

Se, ad esempio, utilizziamo il Llama2 LLM, possiamo inviarti un'immagine in una conversazione o tramite API e chiederti di descrivercela, un esempio impressionante con un ritaglio Grafana… Non ti do più indizi…
Interazione con i documenti

Per vedere un altro rapido esempio delle sue possibilità… Da 'Documenti’ Possiamo caricare qualsiasi documento e poi avere conversazioni sul suo contenuto. Puoi caricare un libro e chiedergli cose o consigli, andare, Dipende da cosa parla il libro… O questo semplice esempio in cui carico un white paper di una migrazione di Active Directory, e…
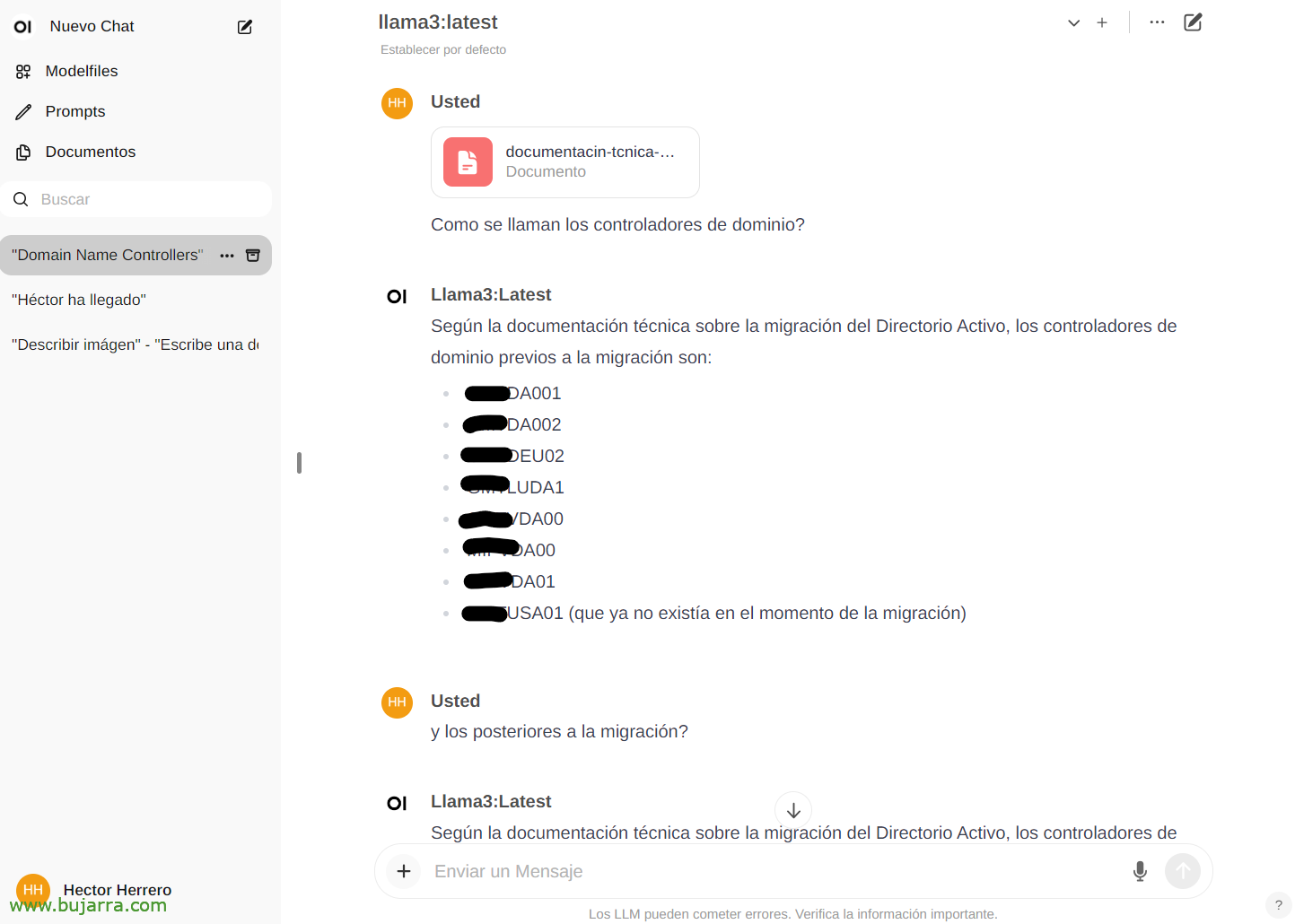
E poi nella chat possiamo consultarti su un documento specifico digitando il # e selezionando il tag che abbiamo messo sul documento. Impressionante…
Parecchi
E bene per finalizzare il documento, Vedremo le cose in futuro, Sembra molto molto buono, Non solo questo che abbiamo visto, se non tutte le sue possibilità con l'API ad esempio e la possibilità di integrare qualsiasi sistema con la nostra AI. Un'intelligenza artificiale sicura, locale, gratuito, L'ollama è qui per restare!
Nei prossimi post, grazie a questa API saremo in grado di integrare le notifiche di Centreon, di Elasticsearch, della nostra casa intelligente con Home Assistant, e la chiamo al telefono e le faccio domande, Controlla qualsiasi dispositivo della casa in modo intuitivo, Ricevi avvisi molto curiosi e un lungo eccetera…

Se vogliamo, ad esempio, con curl lanciare una query di esempio:
Curl HTTP://localhost:11434/api/genera -d '{ "modello": "maestrale:7b", "sollecito": "Conosci l'Athletic Bilbao?", "Corrente": Falso }'
{"modello":"maestrale:7b","created_at":"2024-03-29S12:38:07.663941281Z","risposta":" Sì, Conosco l'Athletic Club de Bilbao, è una società calcistica spagnola con sede nella città di Bilbao, Province Basche. È stata fondata il 14 Ottobre 1894 e attualmente gioca in LaLiga, La Prima Divisione Spagnola di Calcio. È noto per il suo stile di gioco basato sulla sua filosofia, che dà priorità allo sviluppo dei giocatori promossi delle categorie giovanili del club. Il suo stadio è il San Mamés."
O essere in grado di mettere i parametri per scegliere il modello, la temperatura per farti avere più o meno allucinazioni, Lunghezze… Vedremo altri esempi:
Curl HTTP://XXX.XXX.XXX.XXX:11434/api/genera -d '{ "modello": "maestrale:7b", "sollecito": "Conosci l'Athletic Bilbao?", "Corrente": Falso, "temperatura": 0.3, "max_length": 80}'
Bene, Non mi faccio più coinvolgere, per avere un'idea delle possibilità penso che ne valga la pena 🙂 Vedremo più cose e curiosi. E la verità è che devo omettere alcune cose perché le uso nella mia attività e sono valori differenziali che molte volte sai già cosa succede con i fornitori rivali…
Un abbraccio e vi auguro una buonissima settimana!










