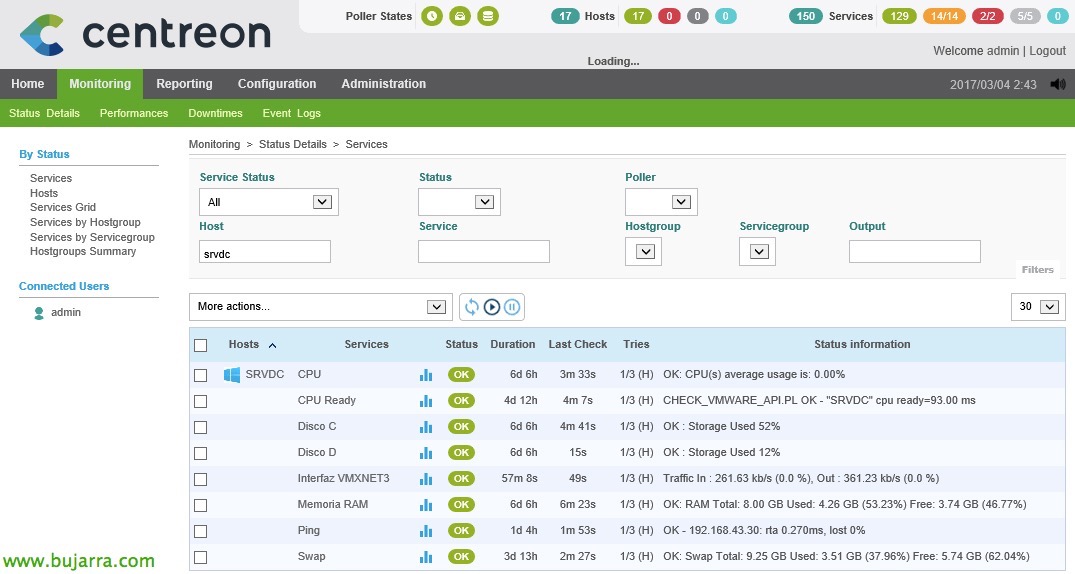
Nagis – Monitoritzant els nostres hosts ESXi

En aquest document, veurem tots els passos necessaris per poder monitoritzar un host ESXi, veurem els paràmetres més comuns i els valors que podrem obtenir per tenir un entorn controlat gràcies a Nagios i Centreon! És assenyada tota la informació que podrem obtenir! En altres documents ja veurem una altra info que podrem obtenir de vCenter i els seus MVs, avui toquen els hosts!

Instalación de requisitos,
Començam primer instal·lant tots els requisits necessaris per utilitzar un dels scripts més comuns que podem usar. En Nagios Exchange podrem obtenir gairebé qualsevol script que necessitem, i de ahí ens descarreguem posteriorment un que sol usar jo per monitorar hosts ESXi 4.x, 5.x o 6.x. Però abans tendremos a instal·lar en la màquina el SDK de VMware així com tot el necessari abans.
Després de tenir tots els requisits instal·lats i probat que funciona el script para monitorar servidors ESXi, podrem sortir de consola i utilitzar la interfície de Centreon per crear els hosts ESXi, els serveis que monitorarem i els comandos necessaris. Espero que se entienda bé, a seguir los pasos!

Instalando los requisits:
[sourcecode]yum -y install openssl-devel perl-Archive-Zip perl-Class-MethodMaker uuid-perl perl-SOAP-Lite perl-XML-SAX perl-XML-NamespaceSupport perl-XML-LibXML perl-MIME-Lite perl-MIME-Types perl-MailTools perl-TimeDate uuid libuuid perl-Data-Dump perl-UUID make gcc perl-devel libuuid-devel cpan[/sourcecode]

Busquem al web de descàrregues de VMware, el vSphere SDK per a Perl, descarreguem el paquet gz de 64 bit.

El pugem al servidor de Nagios mitjançant WinSCP per exemple i el deixem al directori temporal '/tmp/'. El descomprimim i l'instal·lem:
[sourcecode]tar xvzf VMware-vSphere-Perl-SDK-xxxxxxx.tar.gz
cd vmware-vsphere-cli-distrib/
./vmware-install.pl[/sourcecode]
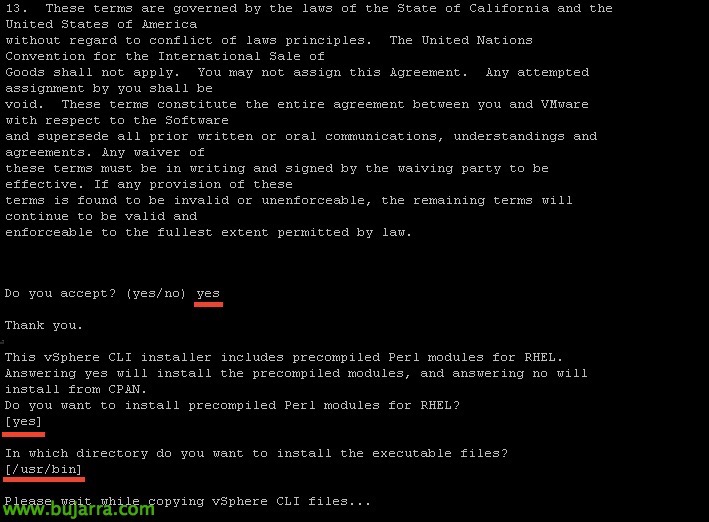
L'instal·lem amb els paràmetres predeterminats,

I després d'uns segons el tindrem instal·lat,

Instal·lem UUID:
[sourcecode]cd /usr/src
wget http://search.cpan.org/CPAN/authors/id/J/JN/JNH/UUID-0.04.tar.gz
tar -xzvf UUID-0.04.tar.gz -C /opt[/sourcecode]

El compilem:
[sourcecode]cd /opt/UUID-0.04
perl Makefile.PL
make[/sourcecode]

I el instal·lem, així com ‘perl-Nagios-Plugin’ que també serà necessari:
[sourcecode]make install
yum install perl-Nagios-Plugin[/sourcecode]

Instal·lem més requisits:
[sourcecode]cpan GAAS/libwww-perl-5.837.tar.gz[/sourcecode]

I anem acabant amb aquest últim!
[sourcecode]cpan Monitoring::Plugin[/sourcecode]
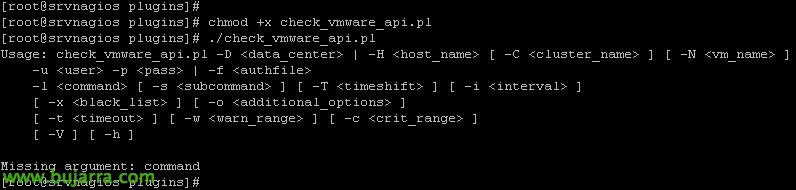
Per fi, ja podrem baixar l'script que ens permetrà obtenir informació dels hosts aquí https://exchange.nagios.org/directory/Plugins/Operating-Systems/*-Virtual-Environments/VMWare/check_vmware_api/details un cop descarregat deixarem el fitxer ‘check_vmware_api.pl’ en '/usr/lib/centreon/plugins/’ i el farem executable amb ‘chmod +x check_vmware_api.pl’. Probarem d'executar-lo i si tot és correcte ens sortirà aquesta pantalla indicant-nos les opcions que podrem fer servir.
Creant un usuari amb privilegis a ESXi,
L'script anterior, necessitarà validar-se contra l'amfitrió ESXi per obtenir la informació que ens interessi, per tant crearem un usuari a cada ESXi i donarem els permisos necessaris.
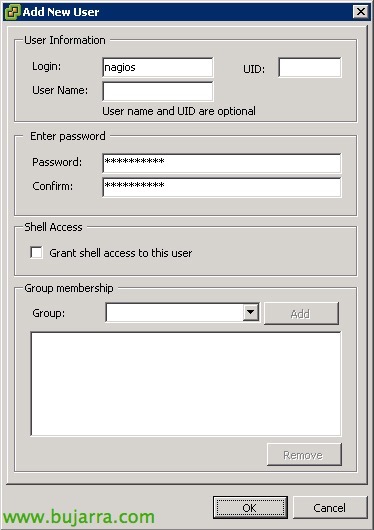
A cada ESXi, després d'iniciar sessió correctament amb el client tradicional o el navegador web, anirem a la zona de “Users” i en crearem un, li establirem també la contrasenya.
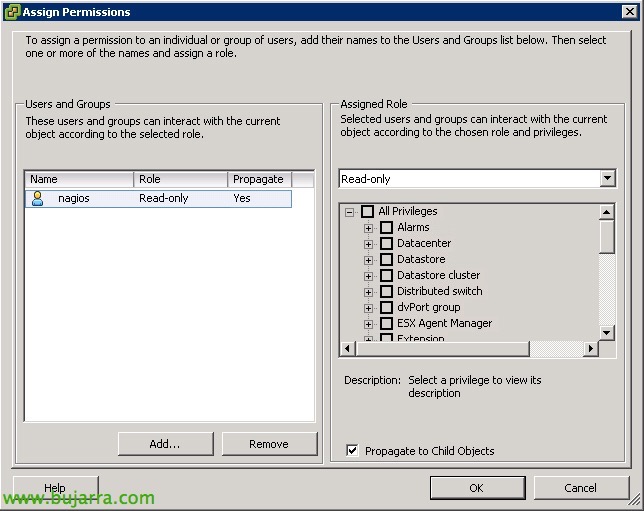
A la pestanya de “Permisos”, afegirem aquest usuari a tot l'abast possible, i l'afegirem amb el rol de ‘Read-Only’.
Ara, crearem al directori que ens interessi (jo el deixo en el mateix de plugins) un fitxer, on emmagatzemarem l'usuari i la contrasenya que la comanda utilitzarà per validar-se quan faci les comprovacions. En aquest exemple el guardo a '/usr/lib/centreon/plugins/check_vmware_api.auth'’ amb el següent format:
[sourcecode]username=usuari
password=Contrasenya[/sourcecode]

Y ya podremos ejecutar cualquier checkeo contra un host ESXi, algo sencillo para probar, ús de CPU:
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l cpu -s usage -w 80 -c 90[/sourcecode]
Los paràmetres que acompanyen el comandament vienen abajo descritos todos, en el comandament anterior '-w’ será el % de aviso cuando sea Warning y '-c’ el valor de cuando sea Critico. Esto os lo comento por que es común en casi todos los comandos, y cada uno que use los varemos que quiera, en aquests documents trobaréis que normalment quan alcance el 80% será algo Warning y when llegue al 90% será Critical.
Ara ya solo queda elegir els elements que más nos interese observar, al final del documento os pondré todas las posibilidades que nos da este excelente comando 'check_vmware_api.pl'. Pero por ahora os pongo los ejemplos más comunes para monitorizar información de un host ESXi:
Uso de Memoria RAM:
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l mem -s usage -w 80 -c 90[/sourcecode]
Uso de Memoria Swap
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l mem -s swap -w 1 -c 10[/sourcecode]
Uso de Memoria Balloning
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l mem -s memctl -w 1 -c 10[/sourcecode]
Uso de red
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l net -s ús -w 10240 -c 102400[/sourcecode]
Detectar si tenemos alguna NIC caida,
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l net -s nic -w 1 -c 2[/sourcecode]
Monitorizar los datastores VMFS, en este, el comandament devuelve el uso libre, por lo indicaremos con el siguiente formato en Warning y Critical el % de espacio libre,
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l vmfs -s LUN04 -w 10%: -c 5%:[/sourcecode]
Por ejemplo con el parámetro ‘runtime’ veremos un resumen general del servidor, y opcionalmente podremos añadirle otras opciones como ‘health’ para ver la salud, ‘temperature’ para ver los sensores de temperatura, o ‘status’ para ver un resumen entre otros.
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime -s health
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime -s temperature
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime -s status[/sourcecode]
Si usamos el parámetro ‘service’ podremos ver el status de todos los serveis de ESXi si estan corriendo o no, i addicionalment podremos afegir el nombre de los serveis que ens interessa monitorar unica.
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l service
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l service -s DCUI vpxa[/sourcecode]
Ara amb això crec que ens val, no? Ya que el script 'check_vmware_api.pl’ encara hi ha moltes coses més curioses que podràs curiosar i ja verem en altres posts, també ens valdría per monitorar Clústers de hosts, Data Centers, Máquinas Virtuales, etc.… un altre dia ;), ara seguim amb els hosts!
Creant un host,
Aquí daremos ya por fín de alta en Nagios, el nostre primer servidor, un host ESXi! Usaremos Centreon para facilitar todo el treball.

Des de “Configuration” > “Hosts” > “Add”, añadiremos el nostre primer servidor, completaremos al menos los siguientes campos:
- Name: Nom del servidor.
- Àlies: Alias del servidor.
- IP Address / DNS: La dirección IP o nombre DNS del servidor.
- SNMP Community & Version: En este caso no sería necesario.
- Monitored from: El poller que monitorizará este host.
- Template: Seleccionamos ‘generic-active-host’.
Creando un Comando,
Definiremos un Comando en Centreon usando variables para poder ejecutar los comandos que vimos antes, este comando luego será llamado desde cada Servicio que creemos para monitorizar la CPU, RAM… Qué mejor que verlo para entenderlo 🙂

Me suele gustar llamar al Comando igual que el script, por eso, en este caso crearé el comando ‘check_vmware_api.pl’. Per a això, des de “Configuration” > “Commands” > “Checks” > “Add”. Indicamos que es un comando de tipo ‘Check’ y en el ‘Command line indicamos’:
[sourcecode]$CENTREONPLUGINS$/check_vmware_api.pl -H $HOSTADDRESS$ -f $CENTREONPLUGINS$/check_vmware_api.auth -l $ARG1$ -s $ARG2$ -w $ARG3$ -c $ARG4$[/sourcecode]
- La variable $CENTREONPLUGINS$ és ‘/usr/lib/centreon/plugins/’
- La variable $HOSTADDRESS$ seria l'adreça IP o el nom FQDN del servidor a monitoritzar.
- ARG1 seria el primer argument que li passarem, si recordem és el ‘Comandament’ que s'indica després de ‘-l’.
- ARG2 seria el primer argument que li passarem,si recordem és el ‘Subcomandament’ que s'indica després de ‘-s’.
- ARG3 serà el valor de Warning.
- ARG4 serà el valor de Critical.
Posem en “Descriu arguments” per no haver de memoritzar i saber això.
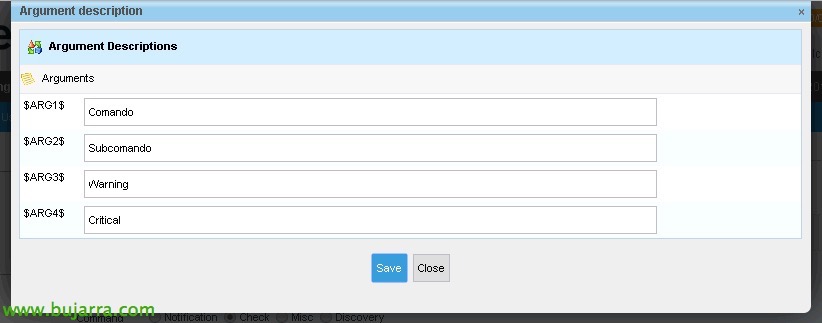
Així que associem d'una manera senzilla què és cada Argument, que després quan creem els serveis, lo agradeceremos. “Save”.
Creant els serveis,
Aquí ja per fín podrem crear els serveis de lo que volem vigilar, sea CPU, RAM, NICs caidas, estado de los datastores… per a això, ens apoyarem com hem dit al comandament que acabàvem de crear! Mirar qué fácil:

En “Configuration” > “Services” > “Add”, crearem el nostre primer servei! Rellenarem al menys les següents dades:
- Description: Nombre del servei, en el meu cas CPU, Memòria RAM, Memòria Swap…
- Linked with Hosts: Aquí añadiremos el host que hemos creat antes, nuestro servidor ESXi.
- Template: Seleccionamos 'generic-active-service'.
- Check Command: Escogemos el comandament que hem creat abans també, que en mi cas le llame como el script 'check_vmware_api.pl’
- Arguments: Deberemos rellenar todos los argumentos que nos pida el comando.
- Uso de CPU: cpu / usage / 80 / 90
- Memòria RAM: mem / usage / 80 / 90
- Memòria Swap: mem / swap / 1 / 10
- Memoria Balloning: mem / memctl / 1/ 10
- Estado de NIC: net / nic / 1 / 2
- …
Gravem amb “Save”,

Para ir crear el resto de servicios, en vez de crearlos tots des de cero, el més còmode serà duplicar-los, així només haurem d'editar els arguments i serà molt més fàcil crear els serveis.

Un cop hàgim creat tots els serveis associats a un host ESXi, si ara volem duplicar el treball realitzat per monitoritzar un altre host ESXi que tinguem, o tots els que tinguem, doncs des de “Configuration” > “Hosts”, seleccionarem l'ESXi que tenim i el dupliquem, amb això generem un nou host, al qual haurem de canviar el Nom, Àlies i Adreça IP i ja tindrem un altre host llest amb els mateixos serveis!
I res, el de sempre, un cop finalitzat el treball, guardem els canvis, Cenreon generarà els fitxers de nagios necessaris, “Configuration” > “Pollers” > “Export configuration”,
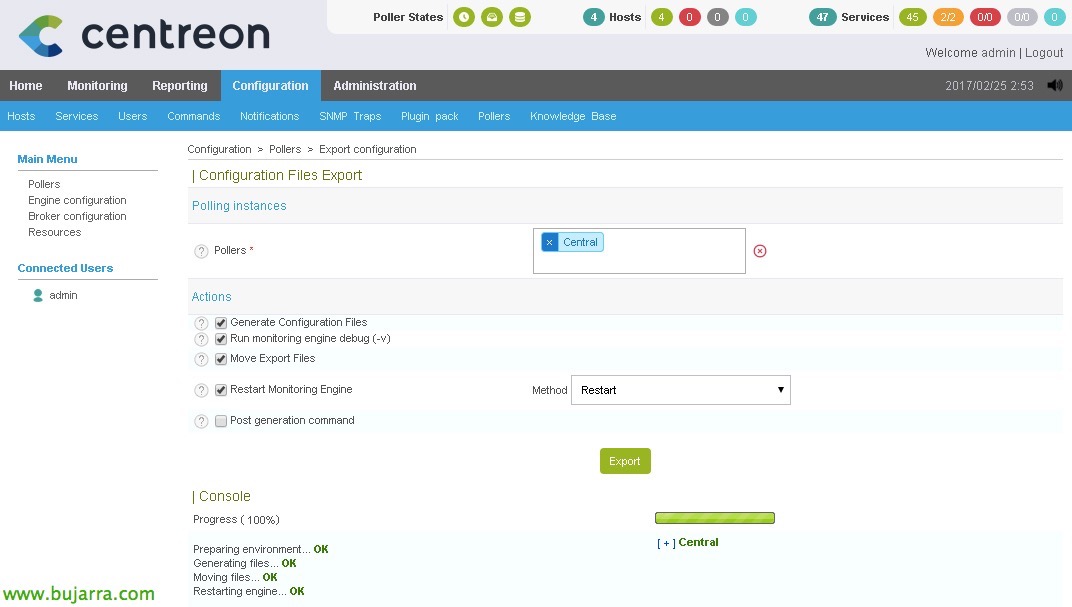
Seleccionem el nostre poller, marquem els checks i reiniciem & “Export”,

Un cop generat tot, ya podremos ir a la parte de monitorización y comprobar que todo lo que hemos hecho funciona! Veremos todos los nuevos servicios que hemos creado que monitorizan distintas cosas. Si volem forçar el checkeig, ja sabem, seleccionamos los servicios que nos interesen y en el combo seleccionamos ‘Services – Schedule immediate check (Forced)’.
Y aquí os dejo todas las posibilidades del comando:
[sourcecode]Usage: check_vmware_api.pl -D <data_center> | -H <host_name> [ -C <cluster_name> ] [ -N <vm_name> ]
-u <user> -p <pass> | -f <authfile>
-l <command> [ -s <subcommand> ] [ -T <timeshift> ] [ -i <interval> ]
[ -x <black_list> ] [ -o <additional_options> ]
[ -t <timeout> ] [ -w <warn_range> ] [ -c <crit_range> ]
[ -V ] [ -h ]
-?, –usage
Print usage information
-h, –help
Print detailed help screen
-V, –version
Print version information
–extra-opts=[secció][@file]
Read options from an ini file.
for usage and examples.
-H, –host=<hostname>
ESX or ESXi hostname.
-C, –cluster=<clustername>
ESX or ESXi clustername.
-D, –datacenter=<DCname>
Datacenter hostname.
-N, –name =<vmname>
Virtual machine name.
-u, –username=<username>
Username to connect with.
-p, –password =<password>
Password to use with the username.
-f, –authfile=<path>
Authentication file with login and password. File syntax :
username=<login>
password =<password>
-w, –warning=THRESHOLD
Warning threshold. See
for the threshold format. Per defecte, no threshold is set.
-c, –critical=THRESHOLD
Critical threshold. See
for the threshold format. Per defecte, no threshold is set.
-l, –command=COMMAND
Specify command type (CPU, MEM, NET, IO, VMFS, RUNTIME, …)
-s, –subcommand=SUBCOMMAND
Specify subcommand
-S, –sessionfile=SESSIONFILE
Specify a filename to store sessions for faster authentication
-x, –exclude=<black_list>
Specify black list
-o, –options=<additional_options>
Specify additional command options (quickstats, …)
-T, –timestamp=<timeshift>
Timeshift in seconds that could fix issues with "Unknown error". Use values like 5, 10, 20, etc.
-i, –interval=<sampling period>
Sampling Period in seconds. Basic historic intervals: 300, 1800, 7200 o 86400. See config for any changes.
Supports literval values to autonegotiate interval value: r – realtime interval, h<number> – historical interval specified by position.
Default value is 20 (realtime). Since cluster does not have realtime stats interval other than 20(default realtime) is mandatory.
-M, –maxsamples=<recompte màxim de mostres>
Nombre màxim de mostres a recuperar. El nombre màxim de mostres s'ignora per als intervals històrics.
Default value is 1 (última mostra disponible).
–trace=<level>
Configura el nivell de detall del rastreig de sol·licituds/respostes de l'API de vSphere
–generate_test=<file>
Genera un script de cas de prova a partir de la comanda/subcomanda executada i escriu-lo a <file>. If <file> is "stdout", el script del cas de prova s'escriu a stdout en lloc d'això.
-t, –timeout=INTEGER
Segons abans que el connector caduqui (default: 30)
-v, –verbose
Mostra detalls per a la depuració de línia de comandes (pot repetir fins a 3 vegades)
Comandes compatibles(^ – paràmetre en blanc o sense especificar, o – opcions, T – valor de desfasament de temps, b – blacklist) :
Específic de VM :
* cpu – mostra informació de CPU
+ usage – Ús de CPU en percentatge
+ usagemhz – Ús de CPU en MHz
+ wait – Temps d'espera de CPU en ms
+ ready – Temps de preparació de CPU en ms
^ tota la informació de CPU(sense llindars)
* mem – mostra informació de memòria
+ usage – Ús de memòria en percentatge
+ usagemb – Ús de memòria en MB
+ swap – Ús de memòria swap en MB
+ swapin – Ús de memòria swap d'entrada en MB
+ swapout – swapout mem usage in MB
+ overhead – additional mem used by VM Server in MB
+ overall – overall mem used by VM Server in MB
+ active – active mem usage in MB
+ memctl – mem used by VM memory control driver(vmmemctl) that controls ballooning
^ all mem info(except overall and no thresholds)
* net – shows net info
+ usage – overall network usage in KBps(Kilobytes per Second)
+ receive – receive in KBps(Kilobytes per Second)
+ send – send in KBps(Kilobytes per Second)
^ all net info(except usage and no thresholds)
* io – shows disk I/O info
+ usage – overall disk usage in MB/s
+ read – read disk usage in MB/s
+ write – write disk usage in MB/s
^ all disk io info(sense llindars)
* runtime – mostra informació d'execució
+ amb – estat de la connexió
+ cpu – CPU assignada en MHz
+ mem – memòria assignada en MB
+ state – estat de la màquina virtual (EN MARXA, ATURAT, SUSPÈS)
+ estatus – estat global de l'objecte (gris/verd/vermell/groc)
+ connexions de consola – connexions de consola a MV
+ invitada – estat del SO convidat, necessita VMware Tools
+ eines – estat de VMware Tools
+ problemes – tots els problemes de l'amfitrió
^ tota la informació d'execució(excepte con i sense llindars)
Específic de l'amfitrió :
* cpu – mostra informació de CPU
+ usage – Ús de CPU en percentatge
o quickstats – canviar per consultar valors de PerfCounter o informació d'execució
+ usagemhz – Ús de CPU en MHz
o quickstats – canviar per consultar valors de PerfCounter o informació d'execució
^ tota la informació de CPU
o quickstats – canviar per consultar valors de PerfCounter o informació d'execució
* mem – mostra informació de memòria
+ usage – Ús de memòria en percentatge
o quickstats – canviar per consultar valors de PerfCounter o informació d'execució
+ usagemb – Ús de memòria en MB
o quickstats – canviar per consultar valors de PerfCounter o informació d'execució
+ swap – Ús de memòria swap en MB
o listvm – activar/desactivar la sortida de la llista de VM que fan swapping
+ overhead – additional mem used by VM Server in MB
+ overall – overall mem used by VM Server in MB
+ memctl – mem used by VM memory control driver(vmmemctl) that controls ballooning
o listvm – activar/desactivar la sortida de la llista de VM que tenen ballooning
^ all mem info(except overall and no thresholds)
* net – shows net info
+ usage – overall network usage in KBps(Kilobytes per Second)
+ receive – receive in KBps(Kilobytes per Second)
+ send – send in KBps(Kilobytes per Second)
+ nic – assegura que totes les NIC actives estiguin connectades
^ all net info(except usage and no thresholds)
* io – mostra informació d'entrada/sortida de disc
+ abortat – nombre de comandes abortades
+ reinicia – nombre de reinicis de bus
+ read – latència de lectura en ms (totalReadLatency.average)
+ write – latència d'escriptura en ms (totalWriteLatency.average)
+ nucli – latència del nucli en ms
+ device – latència del dispositiu en ms
+ cua – latència de la cua en ms
^ all disk io info
* vmfs – mostra informació del Datastore
+ (name) – informació d'espai lliure per al datastore amb nom (name)
o used – mostra l'espai utilitzat en lloc de l'espai lliure
o brief – llista només els volums amb alerta
o regexp – si es tracta el nom com a regexp
o blacklistregexp – si es tracta la llista negra com a regexp
b – VMFS a la llista negra
T (value) – desplaçament temporal per determinar si necessitem actualitzar
^ tota la informació del datastore
o used – mostra l'espai utilitzat en lloc de l'espai lliure
o brief – llista només els volums amb alerta
o blacklistregexp – si es tracta la llista negra com a regexp
b – VMFS a la llista negra
T (value) – desplaçament temporal per determinar si necessitem actualitzar
* runtime – mostra informació d'execució
+ amb – estat de la connexió
+ salut – comprova l'estat de CPU/ emmagatzematge/memòria/sensor i propaga l'estat més crític
o llistitems – llista tots els sensors disponibles(només per a finalitats de llistat)
o blackregexpflag – si es tracta la llista negra com a regexp
b – objectes d'estat a la llista negra
+ storagehealth – comprovació de l'estat de l'emmagatzematge
o blackregexpflag – si es tracta la llista negra com a regexp
b – objectes d'estat a la llista negra
+ temperature – sensors de temperatura
o blackregexpflag – si es tracta la llista negra com a regexp
b – objectes d'estat a la llista negra
+ sensor – sensor amb llindar especificat
+ manteniment – mostra si l'amfitrió està en mode de manteniment
o maintwarn – estableix l'estat d'advertència quan l'amfitrió està en mode de manteniment
o maintcrit – estableix l'estat crític quan l'amfitrió està en mode de manteniment
+ list(vm) – llista de màquines VMware i els seus estats
+ estatus – estat global de l'objecte (gris/verd/vermell/groc)
+ problemes – tots els problemes de l'amfitrió
b – problemes de la llista negra
^ tota la informació d'execució(salut, storagehealth, la temperatura i el sensor estan representats com un sol valor i sense llindars)
* service – mostra informació del servei de l'amfitrió
+ (Noms) – comprova l'estat d'un o diversos serveis especificats per (Noms), sintaxi per a (Noms):<servei1>,<servei2>,…,<serveiN>
^ mostra tots els serveis
* storage – mostra informació de l'emmagatzematge de l'amfitrió
+ adaptador – llista els adaptadors del bus
b – adaptadors a la llista negra
+ lun – llista unitats lògiques SCSI
b – LUN a la llista negra
+ path – llista els camins de la unitat lògica
b – camins de llista negra
^ mostra tota la informació d'emmagatzematge
* uptime – mostra el temps d'activitat de l'amfitrió
o quickstats – canviar per consultar valors de PerfCounter o informació d'execució
* device – mostra informació específica del dispositiu de l'amfitrió
+ cd/dvd – llista de VM amb unitats cd/dvd connectades
o llista tots – llista de tots els dispositius disponibles(només per a finalitats de llistat)
DC específic :
* cpu – mostra informació de CPU
+ usage – Ús de CPU en percentatge
o quickstats – canviar per consultar valors de PerfCounter o informació d'execució
+ usagemhz – Ús de CPU en MHz
o quickstats – canviar per consultar valors de PerfCounter o informació d'execució
^ tota la informació de CPU
o quickstats – canviar per consultar valors de PerfCounter o informació d'execució
* mem – mostra informació de memòria
+ usage – Ús de memòria en percentatge
o quickstats – canviar per consultar valors de PerfCounter o informació d'execució
+ usagemb – Ús de memòria en MB
o quickstats – canviar per consultar valors de PerfCounter o informació d'execució
+ swap – Ús de memòria swap en MB
+ overhead – additional mem used by VM Server in MB
+ overall – overall mem used by VM Server in MB
+ memctl – mem used by VM memory control driver(vmmemctl) that controls ballooning
^ all mem info(except overall and no thresholds)
* net – shows net info
+ usage – overall network usage in KBps(Kilobytes per Second)
+ receive – receive in KBps(Kilobytes per Second)
+ send – send in KBps(Kilobytes per Second)
^ all net info(except usage and no thresholds)
* io – mostra informació d'entrada/sortida de disc
+ abortat – nombre de comandes abortades
+ reinicia – nombre de reinicis de bus
+ read – latència de lectura en ms (totalReadLatency.average)
+ write – latència d'escriptura en ms (totalWriteLatency.average)
+ nucli – latència del nucli en ms
+ device – latència del dispositiu en ms
+ cua – latència de la cua en ms
^ all disk io info
* vmfs – mostra informació del Datastore
+ (name) – informació d'espai lliure per al datastore amb nom (name)
o used – mostra l'espai utilitzat en lloc de l'espai lliure
o brief – llista només els volums amb alerta
o regexp – si es tracta el nom com a regexp
o blacklistregexp – si es tracta la llista negra com a regexp
b – VMFS a la llista negra
T (value) – desplaçament temporal per determinar si necessitem actualitzar
^ tota la informació del datastore
o used – mostra l'espai utilitzat en lloc de l'espai lliure
o brief – llista només els volums amb alerta
o blacklistregexp – si es tracta la llista negra com a regexp
b – VMFS a la llista negra
T (value) – desplaçament temporal per determinar si necessitem actualitzar
* runtime – mostra informació d'execució
+ list(vm) – llista de màquines VMware i els seus estats
+ llistaamfitrió – llista de servidors host VMware ESX i els seus estats
+ llistaclúster – llista de clústers VMware i els seus estats
+ eines – estat de VMware Tools
b – llista negra de VM
+ estatus – estat global de l'objecte (gris/verd/vermell/groc)
+ problemes – tots els problemes de l'amfitrió
b – problemes de la llista negra
^ tota la informació d'execució(excepte clúster i eines i sense llindars)
* recomanacions – mostra recomanacions per al clúster
+ (name) – recomanacions per al clúster amb nom (name)
^ recomanacions de tots els clústers
Clúster específic :
* cpu – mostra informació de CPU
+ usage – Ús de CPU en percentatge
+ usagemhz – Ús de CPU en MHz
^ tota la informació de CPU
* mem – mostra informació de memòria
+ usage – Ús de memòria en percentatge
+ usagemb – Ús de memòria en MB
+ swap – Ús de memòria swap en MB
o listvm – activar/desactivar la sortida de la llista de VM que fan swapping
+ memctl – mem used by VM memory control driver(vmmemctl) that controls ballooning
o listvm – activar/desactivar la sortida de la llista de VM que tenen ballooning
^ all mem info(més sobrecàrrega i sense llindars)
* cluster – mostra informació dels serveis del clúster
+ cpuEfectiva – total de recursos de CPU disponibles de tots els amfitrions dins del clúster
+ memEfectiva – quantitat total de memòria de màquina de tots els amfitrions del clúster
+ failover – Número de fallades tolerables de VMware HA
+ justíciaCPU – justícia en la distribució dels recursos de CPU
+ justíciaMem – justícia de l'assignació de recursos distribuïda de MEM
^ Només valors d'efectivCPU i d'Effectmem per als serveis del clúster
* runtime – mostra informació d'execució
+ list(vm) – llista de màquines VMware en clúster i els seus estats
+ llistaamfitrió – llista de servidors amfitrions VMware ESX al clúster i els seus estats
+ estatus – estat general del clúster (gris/verd/vermell/groc)
+ problemes – tots els problemes del clúster
b – problemes de la llista negra
^ tota la informació d'execució del clúster
* vmfs – mostra informació del Datastore
+ (name) – informació d'espai lliure per al datastore amb nom (name)
o used – mostra l'espai utilitzat en lloc de l'espai lliure
o brief – llista només els volums amb alerta
o regexp – si es tracta el nom com a regexp
o blacklistregexp – si es tracta la llista negra com a regexp
b – VMFS a la llista negra
T (value) – desplaçament temporal per determinar si necessitem actualitzar
^ tota la informació del datastore
o used – mostra l'espai utilitzat en lloc de l'espai lliure
o brief – llista només els volums amb alerta
o blacklistregexp – si es tracta la llista negra com a regexp
b – VMFS a la llista negra
T (value) – desplaçament temporal per determinar si necessitem actualitzar[/sourcecode]