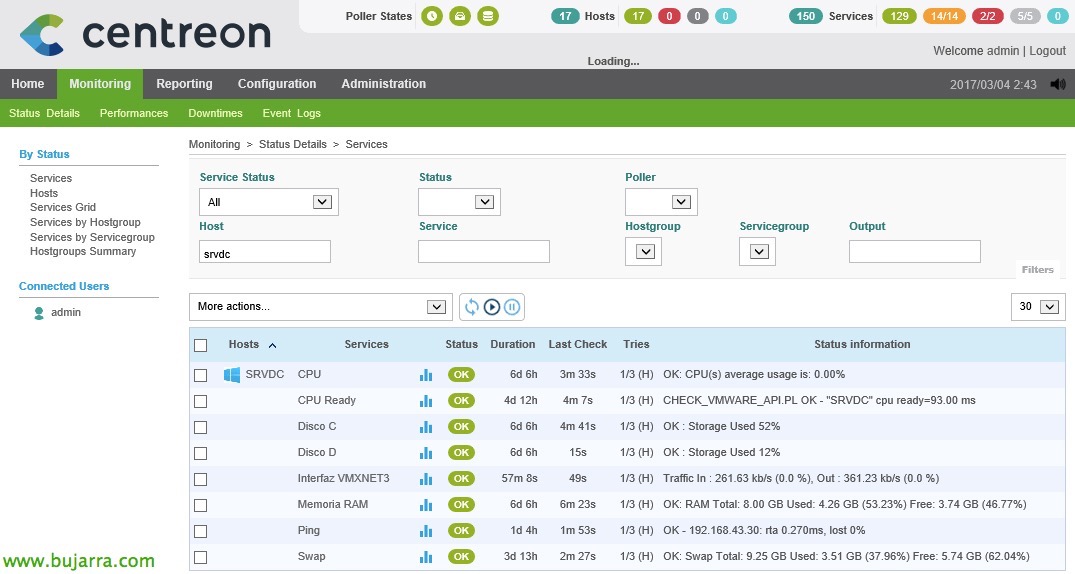
Nagios – Monitorizando nuestros hosts ESXi

En este documento, veremos todos los pasos necesarios para poder monitorizar un host ESXi, veremos los parámetros más comunes y los valores que podremos obtener para tener un entorno controlado gracias a Nagios y Centreon! Es asombrosa toda la información que podremos obtener! En otros documentos ya veremos otra info que podremos obtener de vCenter y sus MVs, hoy tocan los hosts!

Instalación de requisitos,
Empezaremos primero instalando todos los requisitos necesarios para usar uno de los scripts más comunes que podemos usar. In Nagios Exchange podremos obtener casi cualquier script que necesitemos, y de ahí nos descargaremos posteriormente uno que suelo usar yo para monitorizar hosts ESXi 4.x, 5.x o 6.x. Pero antes tendremos que instalar en la máquina nagios el SDK de VMware, así como todo lo necesario antes.
Tras tener todos los requisitos instalados y probado que funciona el script para monitorizar servidores ESXi, podremos ya salir de consola y usar el interfaz de Centreon para crear los hosts ESXi, los servicios que monitorizaremos y los comandos necesarios. Espero que se entienda bien, a seguir los pasos!
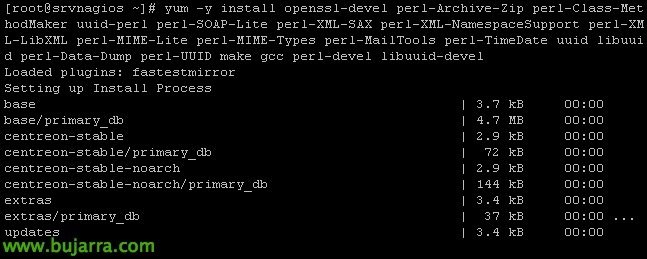
Instalando los requisitos:
[sourcecode]yum -y install openssl-devel perl-Archive-Zip perl-Class-MethodMaker uuid-perl perl-SOAP-Lite perl-XML-SAX perl-XML-NamespaceSupport perl-XML-LibXML perl-MIME-Lite perl-MIME-Types perl-MailTools perl-TimeDate uuid libuuid perl-Data-Dump perl-UUID make gcc perl-devel libuuid-devel cpan[/sourcecode]

Buscamos en la web de descargas de VMware, el vSphere SDK para Perl, descargamos el paquete gz de 64 bit.

Lo subimos al servidor de Nagios mediante WinSCP por ejemplo y lo dejamos en el directorio temporal '/tmp/'. Lo descomprimimos y lo instalamos:
[sourcecode]tar xvzf VMware-vSphere-Perl-SDK-xxxxxxx.tar.gz
cd vmware-vsphere-cli-distrib/
./vmware-install.pl[/sourcecode]
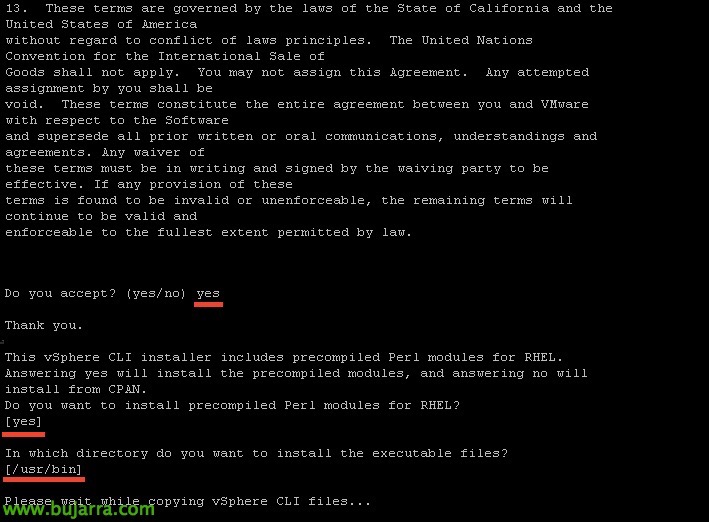
Lo instalamos con los parámetros predeterminados,

Y tras unos segundos lo tendremos instalado,

Instalamos UUID:
[sourcecode]cd /usr/src
wget http://search.cpan.org/CPAN/authors/id/J/JN/JNH/UUID-0.04.tar.gz
tar -xzvf UUID-0.04.tar.gz -C /opt[/sourcecode]
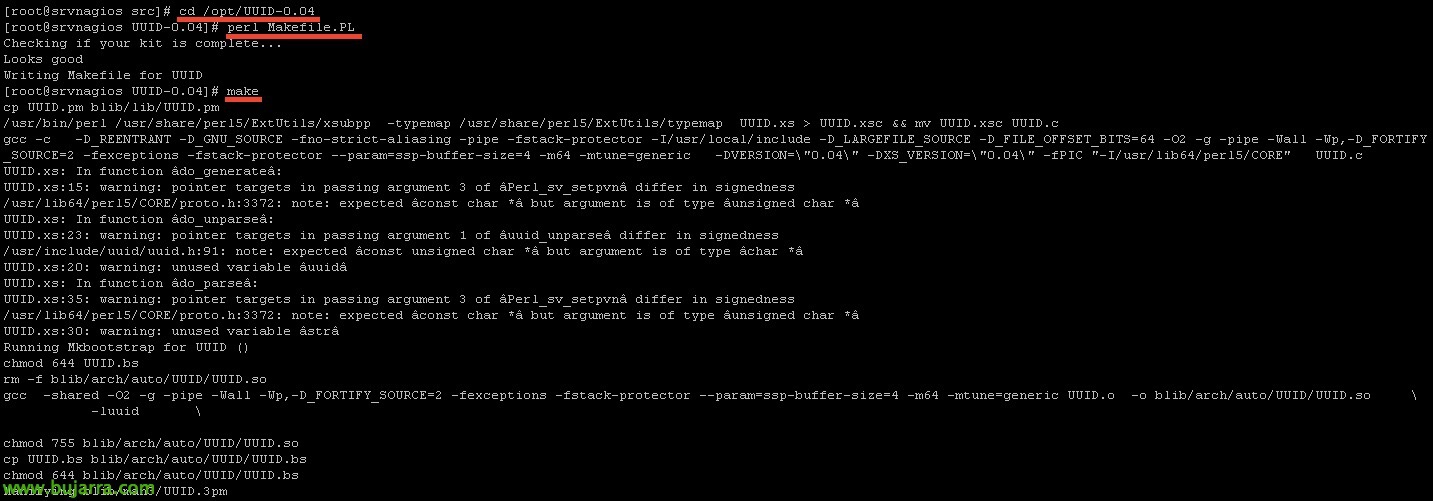
Lo compilamos:
[sourcecode]cd /opt/UUID-0.04
perl Makefile.PL
make[/sourcecode]
Y lo instalamos, así como 'perl-Nagios-Plugin’ que también será necesario:
[sourcecode]make install
yum install perl-Nagios-Plugin[/sourcecode]

Instalamos más requisitos:
[sourcecode]cpan GAAS/libwww-perl-5.837.tar.gz[/sourcecode]
Y vamos acabando con este último!
[sourcecode]cpan Monitoring::Plugin[/sourcecode]

Por fin, ya podremos bajar el script que nos permitirá obtener información de los hosts aquí https://exchange.nagios.org/directory/Plugins/Operating-Systems/*-Virtual-Environments/VMWare/check_vmware_api/details una vez descargado dejaremos el fichero 'check_vmware_api.pl’ en '/usr/lib/centreon/plugins/’ y lo haremos ejecutable con 'chmod +x check_vmware_api.pl'. Probaremos a ejecutarlo y si todo es correcto nos saldrá esta pantalla indicándonos las opciones que podremos usar.
Creando un usuario con privilegios en ESXi,
El script anterior, necesitará validarse contra el host ESXi para obtener la información que nos interese, por tanto crearemos un usuario en cada ESXi y daremos los permisos necesarios.

En cada ESXi, tras loguearnos bien con el cliente tradicional o el navegador web, iremos a la zona de “Erabiltzaileak” y crearemos uno, le estableceremos también la contraseña.

Fitxa honetan “Baimenak”, añadiremos a este usuario a todo el ámbito posible, y le añadiremos con el rol de 'Read-Only'.
orain, crearemos en el directorio que nos interese (yo lo dejo en el mismo de plugins) un fichero, donde almacenaremos el usuario y contraseña que el comando usará para validarse cuando haga los checkeos. En este ejemplo lo guardo en '/usr/lib/centreon/plugins/check_vmware_api.auth’ con el siguiente formato:
[sourcecode]username=usuario
password=Contraseña[/sourcecode]

Y ya podremos ejecutar cualquier checkeo contra un host ESXi, algo sencillo para probar, uso de CPU:
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l cpu -s use -w 80 -c 90[/sourcecode]
Los parámetros que acompañan al comando vienen abajo descritos todos, en el comando anterior ‘-w’ izanen da % de aviso cuando sea Warning y ‘-c’ el valor de cuando sea Critico. Esto os lo comento por que es común en casi todos los comandos, y cada uno que use los varemos que quiera, en estos documentos encontraréis que normalmente cuando alcance el 80% será algo Warning y cuando llegue al 90% será Critical.
Ahora ya sólo queda elegir los elementos que más nos interese monitorizar, al final del documento os pondré todas las posibilidades que nos da este excelente comando ‘check_vmware_api.pl’. Pero por ahora os pongo los ejemplos más comunes para monitorizar información de un host ESXi:
Uso de Memoria RAM:
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l mem -s usage -w 80 -c 90[/sourcecode]
Uso de Memoria Swap
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l mem -s swap -w 1 -c 10[/sourcecode]
Uso de Memoria Balloning
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l mem -s memctl -w 1 -c 10[/sourcecode]
Uso de red
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l net -s usage -w 10240 -c 102400[/sourcecode]
Detectar si tenemos alguna NIC caida,
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l net -s nic -w 1 -c 2[/sourcecode]
Monitorizar los datastores VMFS, en este, el comando devuelve el uso libre, por lo indicaremos con el siguiente formato en Warning y Critical el % de espacio libre,
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l vmfs -s LUN04 -w 10%: -c 5%:[/sourcecode]
Por ejemplo con el parámetro 'runtime’ veremos un resumen general del servidor, y opcionalmente podremos añadirle otras opciones como ‘health’ para ver la salud, ‘temperature’ para ver los sensores de temperatura, o ‘status’ para ver un resumen entre otros.
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime -s health
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime -s temperature
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime -s status[/sourcecode]
Si usamos el parámetro ‘service’ podremos ver el status de todos los servicios de ESXi si están corriendo o no, y adicionalmente podremos añadirle el nombre de los servicios que nos interese monitorizar unicamente.
[sourcecode]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l service
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l service -s DCUI vpxa[/sourcecode]
Por ahora con esto creo que nos vale, ez? Ya que el script 'check_vmware_api.pl’ tiene aún muchísimas cosas más que podrás curiosear y ya veremos en otros posts, también nos valdría para monitorizar Clústers de hosts, Data Centers, Máquinas Virtuales, eta abar… otro día ;), ahora seguimos con los hosts!
Creando un host,
Aqui daremos ya por fín de alta en Nagios nuestro primero servidor, un host ESXi! Usaremos Centreon para facilitar todo el trabajo.
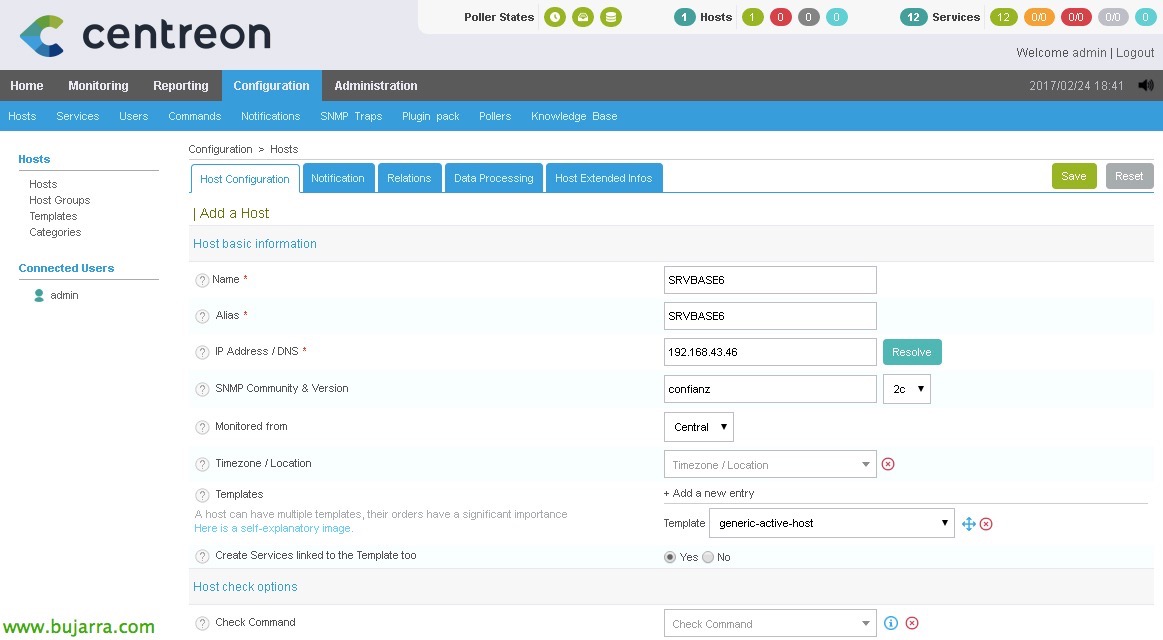
Honetatik “Konfigurazioa” > “Hosts” > “Gehitu”, añadiremos nuestro primer servidor, completaremos al menos los siguientes campos:
- Izena: Nombre del servidor.
- Alias: Alias del servidor.
- IP helbidea / DNS: La dirección IP o nombre DNS del servidor.
- SNMP komunitatea & Version: En este caso no sería necesario.
- Monitored from: Host hau monitoreatuko duen poller-a.
- Txantiloia: 'generic-active-host' hautatu dugu.
Agindu bat sortzen,
Aldagaiak erabiliz Centreonen agindu bat definituko dugu, aurretik ikusi ditugun aginduak exekutatzeko, agindu hau gero sortzen dugun Zerbitzu bakoitzetik deituko da CPUa monitoreatzeko, RAM… Hobe da ikustea ulertzeko 🙂
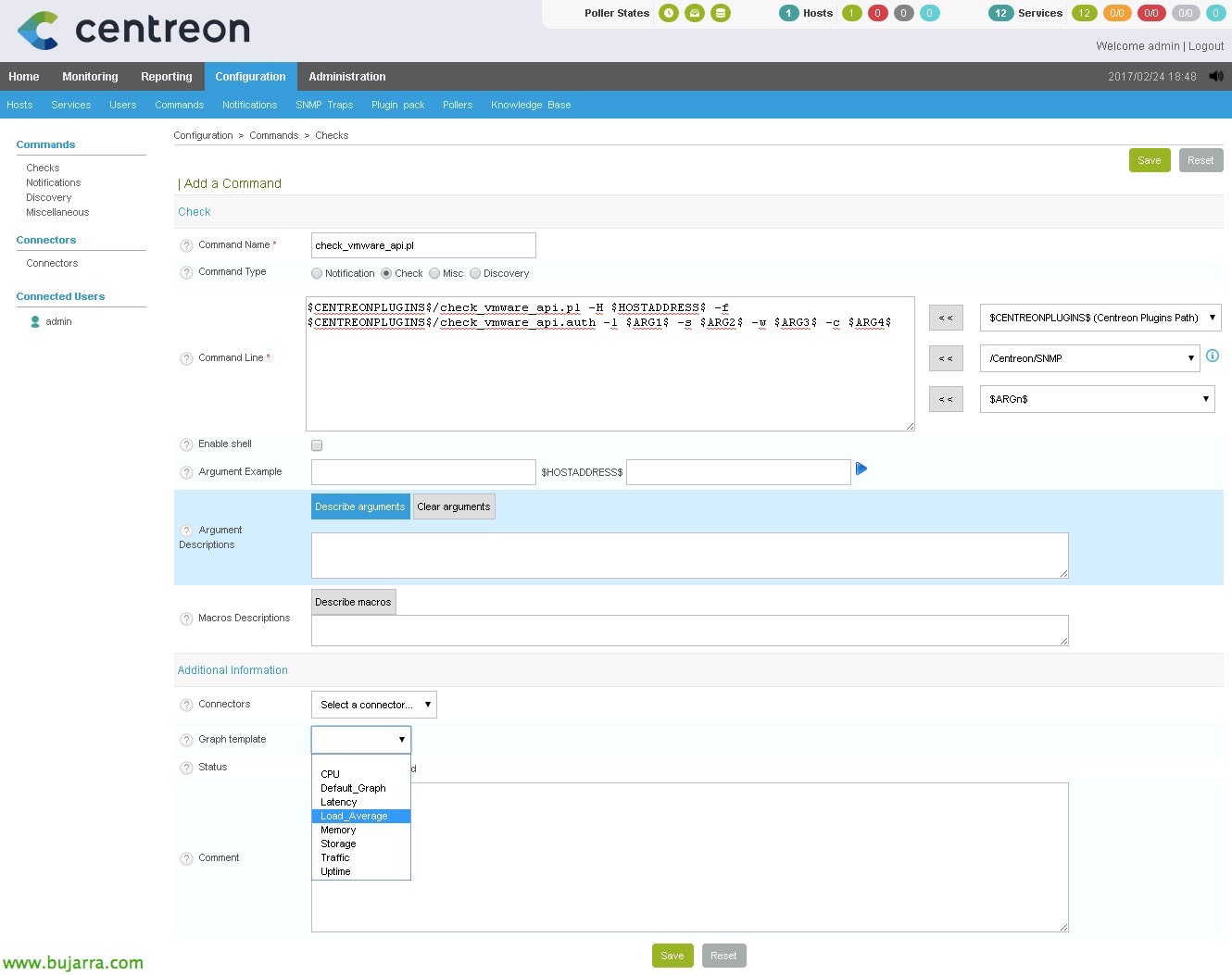
Nire gustuko izaten da agindua script bera bezalaxe izendatzea, horregatik, kasu honetan 'check_vmware_api.pl' agindua sortuko dut. Para ello, etik “Konfigurazioa” > “Commands” > “Checks” > “Gehitu”. Agindu mota 'Check' dela adierazten dugu’ eta 'Command line'-ean honela adierazten dugu:
[sourcecode]$CENTREONPLUGINS$/check_vmware_api.pl -H $HOSTADDRESS$ -f $CENTREONPLUGINS$/check_vmware_api.auth -l $ARG1$ -s $ARG2$ -w $ARG3$ -c $ARG4$[/sourcecode]
- $CENTREONPLUGINS$ aldagaia '/usr/lib/centreon/plugins/' da’
- $HOSTADDRESS$ aldagaiak monitorizatu nahi dugun zerbitzariaren IP helbidea edo FQDN izena izango luke.
- ARG1 izango da emango diogun lehen argumentua, gogoratzen bagara 'Komandoa da’ '-l' ondoren adierazten dena.
- ARG2 izango da emango diogun bigarren argumentua,gogoratzen bagara 'Azpikomandoa da’ '-s' ondoren adierazten dena.
- ARG3 Warning balioa izango da.
- ARG4 Critical balioa izango da.
Sakatu on “Describe arguments” ahaztu gabe eta hau jakin ahal izateko.

Beraz modu errazean lotzen dugu Argumentu bakoitza zer den, eta gero zerbitzuak sortzen dugunean, eskertuko dugu. “Gorde”.
Zerbitzuak sortzea,
Hemen, azkenean, sortu ahal izango ditugu monitorizatu nahi dugun zerbitzuak, CPU izan daiteke, RAM, erorketa duten NIC-ak, datastoreen egoera… horretarako, sortu berri dugun komandoan oinarrituko gara, aipatu dugun bezala! Mirar qué fácil:

In “Konfigurazioa” > “Zerbitzuak” > “Gehitu”, crearemos nuestro primer servicio! Rellenaremos al menos los siguientes datos:
- Deskribapena: Nombre del servicio, en mi caso CPU, RAM memoria, Swap memoria…
- Gurekin lotutako Host-ak: Aquí añadiremos el host que hemos creado antes, nuestro servidor ESXi.
- Txantiloia: Seleccionamos 'generic-active-service'.
- Check Command: Escogemos el comando que hemos creado antes también, que en mi caso le llame como el script 'check_vmware_api.pl’
- Argumentos: Deberemos rellenar todos los argumentos que nos pida el comando.
- Uso de CPU: CPU / usage / 80 / 90
- RAM memoria: mem / usage / 80 / 90
- Swap memoria: mem / swap / 1 / 10
- Memoria Balloning: mem / memctl / 1/ 10
- Estado de NIC: net / nic / 1 / 2
- …
grabatu egiten dugu “Gorde”,

Para ir creando el resto de servicios, en vez de crearlos todos desde cero, lo más cómodo será duplicarlos, así sólo tendremos que editar los argumentos y será mucho más fácil crear los servicios.

Una vez que hayamos creado todos los servicios asociados a un host ESXi, si queremos ahora duplicar el trabajo realizado para monitorizar otro host ESXi que tengamos, o todos los que tengamos, pues desde “Konfigurazioa” > “Hosts”, seleccionaremos el ESXi que tenemos y lo duplicamos, con eso generamos un nuevo host, al que tendremos que cambiar el Nombre, Alias y Direccion IP y ya tendremos otro host listo con los mismos servicios!
Eta ezer, Beti bezalaxe, una vez finalizado el trabajo, guardamos los cambios, Cenreon generará los ficheros de nagios necesarios, “Konfigurazioa” > “Pollers” > “Konfigurazioaren esportazioa”,

Seleccionamos nuestro poller, marcamos los checks y reiniciamos & “Export”,

Una vez generado todo, ya podremos ir a la parte de monitorización y comprobar que todo lo que hemos hecho funciona! Veremos todos los nuevos servicios que hemos creado que monitorizan distintas cosas. Si queremos forzar el checkeo, ya sabemos, seleccionamos los servicios que nos interesen y en el combo seleccionamos ‘Services – Egunerako egiaztapen berehalakoa (Indartutako)’.
Y aquí os dejo todas las posibilidades del comando:
[sourcecode]Usage: check_vmware_api.pl -D <data_center> | -H <host_name> [ -C <cluster_name> ] [ -N <vm_name> ]
-u <user> -p <pass> | -f <authfile>
-l <command> [ -s <subcommand> ] [ -T <timeshift> ] [ -i <interval> ]
[ -x <black_list> ] [ -edo <additional_options> ]
[ -t <timeout> ] [ -w <warn_range> ] [ -c <crit_range> ]
[ -V ] [ -h ]
-?, –usage
Inprimatzeko erabileraren informazioa
-h, –laguntza
Inprimatu laguntza-pantaila xehea
-V, –version
Inprimatzeko bertsioaren informazioa
–extra-opts=[section][@file]
Irakurri ini fitxategi bateko aukerak.
erabilera eta adibideetarako.
-H, –host=<hostname>
ESX edo ESXi ostalari-izena.
-C, –cluster=<clustername>
ESX edo ESXi klusterra-izena.
-D, –datacenter=<DCname>
Datacenter ostalari-izena.
-N, –name=<vmname>
Makina birtualaren izena.
-u, –username=<username>
Erabiltzaile-izenarekin konektatzeko.
-p, –password=<password>
Erabiltzaile-izenarekin erabiltzeko pasahitza.
-f, –authfile=<path>
Autentifikazio-fitxategia saio-hasierarekin eta pasahitzarekin. Fitxategi-sintaxia :
username=<login>
password=<password>
-w, –warning=THRESHOLD
Abisu-atalasea. Ikus
atalase-formatua. Lehenetsitako bezala, ez atalaserik ezarri.
-c, –critical=THRESHOLD
Atalase kritikoa. Ikus
atalase-formatua. Lehenetsitako bezala, ez atalaserik ezarri.
-l, –command=COMMAND
Zehaztu komando mota (CPU, MEM, NET, IO, VMFS, RUNTIME, …)
-s, –subcommand=SUBCOMMAND
Zehaztu azpikomandoa
-S, –sessionfile=SESSIONFILE
Zehaztu fitxategi-izena saioak gordetzeko autentifikazio azkarragoa lortzeko
-x, –exclude=<black_list>
Zehaztu zerrenda beltza
-edo, –options=<additional_options>
Zehaztu komando-aukera gehigarriak (quickstats, …)
-T, –timestamp=<timeshift>
Timeshift in seconds that could fix issues with "Unknown error". Erabili honako balioak 5, 10, 20, eta abar
-i, –interval=<Laginketa periodoa>
Laginketa aldia segundotan. Oinarrizko tarte historikoak: 300, 1800, 7200 edo 86400. Ikusi konfigurazioa edozein aldaketarako.
Balio literbalak onartzen ditu tartearen balioa automatikoki negoziatzeko: r – denbora errealeko tartea, h<number> – posizioaren arabera zehaztutako tarte historikoa.
Balio lehenetsia da 20 (denbora realean). Klusterrak denbora errealeko estatistiken tartea ez duenez 20(denbora errealeko lehenetsia) derrigorrezkoa da.
-M, –maxsamples=<Lagin-kopurua maximoa>
Berreskuratu beharreko gehienezko lagin-kopurua. Lagin-kopuru maximoa ez zaio ikusi tarte historikoetan.
Balio lehenetsia da 1 (azken lagin erabilgarria).
–trace=<maila>
Ezarri vSphere APIaren eskaera/erantzun aztarna
–generate_test=<fitxategia>
Exekutatutako komando/subkomandotik test kasu script bat sortu eta idatzi <fitxategia>. If <fitxategia> is "stdout", test kasu script-a stdout-era idazten da.
-t, –timeout=INTEGER
Pluginak denbora-muga bete aurretik segundoak (default: 30)
-v, –verbose
Komando-lerroko akats-bilaketarako xehetasunak erakutsi (errepika daiteke gehienez 3 aldiz)
Komando onartuenak(^ – hutsik edo ez zehaztutako parametroa, edo – aukera, T – aldaketa-orduaren balioa, b – blacklist) :
VM zehatza :
* CPU – CPU informazioa erakusten du
+ usage – CPU erabilera ehunekoan
+ usagemhz – CPU erabilera MHz-tan
+ wait – CPU itxarote-denbora ms-tan
+ ready – CPU prest den denbora ms-tan
^ CPU informazio guztia(ez dago mugarik)
* mem – memoria informazioa erakusten du
+ usage – memoria erabilera ehunekoan
+ usagemb – Memoria erabilera MB-tan
+ swap – swap memoria erabilera MB-tan
+ swapin – Swapin memoria erabilera MB-tan
+ swapout – Swapout memoria erabilera MB-tan
+ overhead – VM Server-ak erabiltzen duen memoria gehigarria MB-tan
+ overall – VM Server guztia erabiltzen duen memoria MB-tan
+ active – active mem usage in MB
+ memctl – VM memoria kontrolatzeko kontrolatzaileak erabilitako mem(vmmemctl) globoa kontrolatzen duena
^ mem-en informazio guztia(orokorra eta atalaserik ez izan ezik)
* net – net informazioa erakusten du
+ usage – sarearen erabilera orokorra KBps-tan(Kilobyte segundoko)
+ jaso – jaso KBps-tan(Kilobyte segundoko)
+ bidali – bidali KBps-tan bidali(Kilobyte segundoko)
^ net info guztia(erabilera eta atalaserik ez izan ezik)
* io – diskoaren S/O informazioa erakusten du
+ usage – diskoaren erabilera orokorra MB/s-tan
+ read – irakurri diskoaren erabilera MB/s
+ write – write disk use in MB/s
^ all disk io info(ez dago mugarik)
* runtime – shows executiontime info
+ con – connection state
+ CPU – assigned CPU in MHz
+ mem – assigned mem in MB
+ state – assigned machine state (UP, DOWN, SUSPENDED)
+ egoera – overall object status (gray/green/red/yellow)
+ consoleconnections – console connections to VM
+ guest – guest OS status, needs VMware Tools
+ tools – VMware Tools status
+ issues – all issues for the host
^ all runtime info(except con and no thresholds)
Host specific :
* CPU – CPU informazioa erakusten du
+ usage – CPU erabilera ehunekoan
o quickstats – switch for query either PerfCounter values or Runtime info
+ usagemhz – CPU erabilera MHz-tan
o quickstats – switch for query either PerfCounter values or Runtime info
^ CPU informazio guztia
o quickstats – switch for query either PerfCounter values or Runtime info
* mem – memoria informazioa erakusten du
+ usage – memoria erabilera ehunekoan
o quickstats – switch for query either PerfCounter values or Runtime info
+ usagemb – Memoria erabilera MB-tan
o quickstats – switch for query either PerfCounter values or Runtime info
+ swap – swap memoria erabilera MB-tan
o listvm – VM aldaketak kudeatzeko irteera-zerrenda piztu/itzali
+ overhead – VM Server-ak erabiltzen duen memoria gehigarria MB-tan
+ overall – VM Server guztia erabiltzen duen memoria MB-tan
+ memctl – VM memoria kontrolatzeko kontrolatzaileak erabilitako mem(vmmemctl) globoa kontrolatzen duena
o listvm – VM baloiek sortutako irteera-zerrenda piztu/itzali
^ mem-en informazio guztia(orokorra eta atalaserik ez izan ezik)
* net – net informazioa erakusten du
+ usage – sarearen erabilera orokorra KBps-tan(Kilobyte segundoko)
+ jaso – jaso KBps-tan(Kilobyte segundoko)
+ bidali – bidali KBps-tan bidali(Kilobyte segundoko)
+ nic – ziurtatu NIC aktibo guztiak konektatuta daudela
^ net info guztia(erabilera eta atalaserik ez izan ezik)
* io – diskoko IO informazioa erakutsi
+ bertan behera utzia – bertan behera utzitako komandoen kopurua
+ berrezarriak – ibus berrespen kopurua
+ read – irakurketa atzerapena ms-tan (totalReadLatency.average)
+ write – idazketa atzerapena ms-tan (totalWriteLatency.average)
+ kernel-a – kernel atzerapena ms-tan
+ gailu – gailu atzerapena ms-tan
+ ilara – ilara atzerapena ms-tan
^ all disk io info
* vmfs – Datastore informazioa erakutsi
+ (name) – izen duen datastore-aren leku librearen informazioa (name)
o erabilia – loku librea ordezkatu erabilitakoarekin
o labur – alerteratzen duten bolumenak bakarrik zerrendatu
o erreg – izenari erreg baliokide gisa tratatu
o blacklistregexp – beltz zerrendaren erreg baliokide bezala tratatuko den ala ez
b – beltza zerrendako VMFS-ak
T (value) – berrasteko beharra duten jakiteko denbora-aldaketa egin
^ datastore informazio guztia
o erabilia – loku librea ordezkatu erabilitakoarekin
o labur – alerteratzen duten bolumenak bakarrik zerrendatu
o blacklistregexp – beltz zerrendaren erreg baliokide bezala tratatuko den ala ez
b – beltza zerrendako VMFS-ak
T (value) – berrasteko beharra duten jakiteko denbora-aldaketa egin
* runtime – shows executiontime info
+ con – connection state
+ osasuna – CPU/espazioa/memoria/sentsoreen egoera egiaztatu eta egoera okerrena adierazi
o listitems – eskuragarri dauden sentsore guztiak zerrendatu(zerrendatze helburuetarako bakarrik erabili)
o blackregexpflag – beltz zerrendaren erreg baliokide bezala tratatuko den ala ez
b – Blacklist egoera objektuak
+ storagehealth – Biltegiko egoeraren egiaztapena
o blackregexpflag – beltz zerrendaren erreg baliokide bezala tratatuko den ala ez
b – Blacklist egoera objektuak
+ tenperatura. – tenperatura sentsoreak
o blackregexpflag – beltz zerrendaren erreg baliokide bezala tratatuko den ala ez
b – Blacklist egoera objektuak
+ sensor – muga zehaztutako sentsorea
+ mantentze-lanak – erakusten du hosta mantentze-moduan dagoen ala ez
o maintwarn – hosta mantentze-moduan dagoenean alerta egoera ezartzen du
o maintcrit – hosta mantentze-moduan dagoenean egoera kritikoa ezartzen du
+ zerrenda(vm) – VMware makinen zerrenda eta haien egoerak
+ egoera – overall object status (gray/green/red/yellow)
+ issues – all issues for the host
b – bazterketa arazoak
^ all runtime info(osasuna, storagehealth, tenperatura eta sentsorea balio bakar gisa ordezkatzen dira eta ez dago mugarik)
* service – host zerbitzuaren informazioa erakusten du
+ (names) – zehaztutako zerbitzu baten edo zerbitzu batzuen egoera egiaztatu (names), sintaxia (names):<service1>,<service2>,…,<serviceN>
^ erakutsi zerbitzu guztiak
* biltegiratzea – host biltegien informazioa erakusten du
+ adapterra – bus adapterrak zerrendatu
b – baztertu adapterrak
+ lun – SCSI unitate logikoak zerrendatu
b – baztertu LUN-ak
+ path – unitate logikoen bideak zerrendatu
b – baztertu bideak
^ erakutsi biltegien informazio guztia
* uptime – hostaren iraupena erakusten du
o quickstats – switch for query either PerfCounter values or Runtime info
* gailu – hostaren gailu zehatza erakusten du
+ cd/dvd – CD/DVD unitateak dituzten birtualak zerrendatu
o listall – eskuragarri dauden gailu guztiak zerrendatu(zerrendatze helburuetarako bakarrik erabili)
DC zehatza :
* CPU – CPU informazioa erakusten du
+ usage – CPU erabilera ehunekoan
o quickstats – switch for query either PerfCounter values or Runtime info
+ usagemhz – CPU erabilera MHz-tan
o quickstats – switch for query either PerfCounter values or Runtime info
^ CPU informazio guztia
o quickstats – switch for query either PerfCounter values or Runtime info
* mem – memoria informazioa erakusten du
+ usage – memoria erabilera ehunekoan
o quickstats – switch for query either PerfCounter values or Runtime info
+ usagemb – Memoria erabilera MB-tan
o quickstats – switch for query either PerfCounter values or Runtime info
+ swap – swap memoria erabilera MB-tan
+ overhead – VM Server-ak erabiltzen duen memoria gehigarria MB-tan
+ overall – VM Server guztia erabiltzen duen memoria MB-tan
+ memctl – VM memoria kontrolatzeko kontrolatzaileak erabilitako mem(vmmemctl) globoa kontrolatzen duena
^ mem-en informazio guztia(orokorra eta atalaserik ez izan ezik)
* net – net informazioa erakusten du
+ usage – sarearen erabilera orokorra KBps-tan(Kilobyte segundoko)
+ jaso – jaso KBps-tan(Kilobyte segundoko)
+ bidali – bidali KBps-tan bidali(Kilobyte segundoko)
^ net info guztia(erabilera eta atalaserik ez izan ezik)
* io – diskoko IO informazioa erakutsi
+ bertan behera utzia – bertan behera utzitako komandoen kopurua
+ berrezarriak – ibus berrespen kopurua
+ read – irakurketa atzerapena ms-tan (totalReadLatency.average)
+ write – idazketa atzerapena ms-tan (totalWriteLatency.average)
+ kernel-a – kernel atzerapena ms-tan
+ gailu – gailu atzerapena ms-tan
+ ilara – ilara atzerapena ms-tan
^ all disk io info
* vmfs – Datastore informazioa erakutsi
+ (name) – izen duen datastore-aren leku librearen informazioa (name)
o erabilia – loku librea ordezkatu erabilitakoarekin
o labur – alerteratzen duten bolumenak bakarrik zerrendatu
o erreg – izenari erreg baliokide gisa tratatu
o blacklistregexp – beltz zerrendaren erreg baliokide bezala tratatuko den ala ez
b – beltza zerrendako VMFS-ak
T (value) – berrasteko beharra duten jakiteko denbora-aldaketa egin
^ datastore informazio guztia
o erabilia – loku librea ordezkatu erabilitakoarekin
o labur – alerteratzen duten bolumenak bakarrik zerrendatu
o blacklistregexp – beltz zerrendaren erreg baliokide bezala tratatuko den ala ez
b – beltza zerrendako VMFS-ak
T (value) – berrasteko beharra duten jakiteko denbora-aldaketa egin
* runtime – shows executiontime info
+ zerrenda(vm) – VMware makinen zerrenda eta haien egoerak
+ listhost – VMware esx ostalari zerbitzariak eta haien egoerak zerrendatu
+ listcluster – VMware kluster guztiak eta haien egoerak zerrendatu
+ tools – VMware Tools status
b – birtualak zerrendatik kendu
+ egoera – overall object status (gray/green/red/yellow)
+ issues – all issues for the host
b – bazterketa arazoak
^ all runtime info(kluster eta tresnak izan ezik eta ez dira mugarik ezarri)
* gomendioak – klusterrei gomendioak erakutsi
+ (name) – izenarekin klusterrei gomendioak erakutsi (name)
^ kluster guztien gomendioak
Kluster zehatza :
* CPU – CPU informazioa erakusten du
+ usage – CPU erabilera ehunekoan
+ usagemhz – CPU erabilera MHz-tan
^ CPU informazio guztia
* mem – memoria informazioa erakusten du
+ usage – memoria erabilera ehunekoan
+ usagemb – Memoria erabilera MB-tan
+ swap – swap memoria erabilera MB-tan
o listvm – VM aldaketak kudeatzeko irteera-zerrenda piztu/itzali
+ memctl – VM memoria kontrolatzeko kontrolatzaileak erabilitako mem(vmmemctl) globoa kontrolatzen duena
o listvm – VM baloiek sortutako irteera-zerrenda piztu/itzali
^ mem-en informazio guztia(goi-kargarekin eta ez da mugarik ezarri)
* klusterra – kluster zerbitzuen informazioa erakutsi
+ eraginkorraCPU – klusterrean dauden ostalari guztien CPU baliabide erabilgarri totala
+ eraginkorraMem – klusterrean dauden ostalari guztien memorien totala
+ failover – VMware HA tolerantzia jasan daitezkeen porrot kopurua
+ CPU justizia – banatutako CPU baliabideen banaketaren justizia
+ Mem justizia – banatutako mem baliabideen banaketaren justizia
^ only effectivecpu and effectivemem values for cluster services
* runtime – shows executiontime info
+ zerrenda(vm) – list of VMware machines in cluster and their statuses
+ listhost – list of VMware esx host servers in cluster and their statuses
+ egoera – overall cluster status (gray/green/red/yellow)
+ issues – all issues for the cluster
b – bazterketa arazoak
^ all cluster runtime info
* vmfs – Datastore informazioa erakutsi
+ (name) – izen duen datastore-aren leku librearen informazioa (name)
o erabilia – loku librea ordezkatu erabilitakoarekin
o labur – alerteratzen duten bolumenak bakarrik zerrendatu
o erreg – izenari erreg baliokide gisa tratatu
o blacklistregexp – beltz zerrendaren erreg baliokide bezala tratatuko den ala ez
b – beltza zerrendako VMFS-ak
T (value) – berrasteko beharra duten jakiteko denbora-aldaketa egin
^ datastore informazio guztia
o erabilia – loku librea ordezkatu erabilitakoarekin
o labur – alerteratzen duten bolumenak bakarrik zerrendatu
o blacklistregexp – beltz zerrendaren erreg baliokide bezala tratatuko den ala ez
b – beltza zerrendako VMFS-ak
T (value) – berrasteko beharra duten jakiteko denbora-aldaketa egin[/sourcecode]