在 Elasticsearch 中收集 Synology LOG 并在 Grafana 中可视化它们

井, 另一篇博文是关于收集日志并将其可视化,以了解我们的基础设施中发生的情况, 今天我们有一个文档,我们将在其中了解如何将 Synology 的日志发送到我们的 Logstash,然后将其存储在 Elasticsearch 中,最后使用 Grafana 进行可视化.
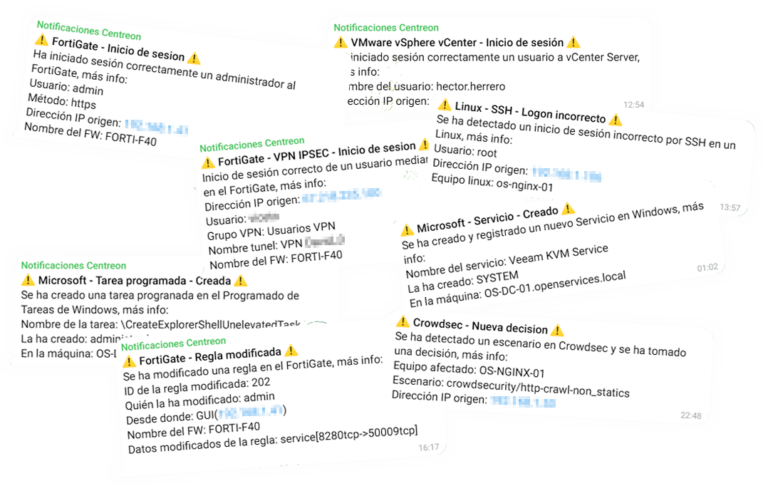
所以, 对橡胶制成的猴子的手杖! (我好老了, 酸奶…) 去! 如果我们有制造商 Synology 的 NAS,我们想知道其中发生了什么, 最好的办法是始终将自己投入到日志中, 但是阅读一行又一行的文字有点无聊, 并不总是实时的, 我们觉得难以理解的… 嗯,就是这样 (和其他事物) 我们有 Elastic Stack, Synology 会将日志发送到 Logstash, 我们将在那里接待他们并治疗他们, 将我们感兴趣的信息分成不同的字段,然后存储在 Elasticsearch 中. 为了可视化数据,我们始终可以使用 Kibana, 但我更像是 Grafana 的粉丝, 对不起, 所以无论选择是什么, 您将能够以不同的格式可视化这些收集的数据, 在表格中, 图形, 奶酪, 世界地图… 这就是您将如何解释 Synology 中发生的事情, 谁访问或试图这样做, 以及它的作用… 您将能够像往常一样看到它, 实时或历史模式进行查询. 开始!
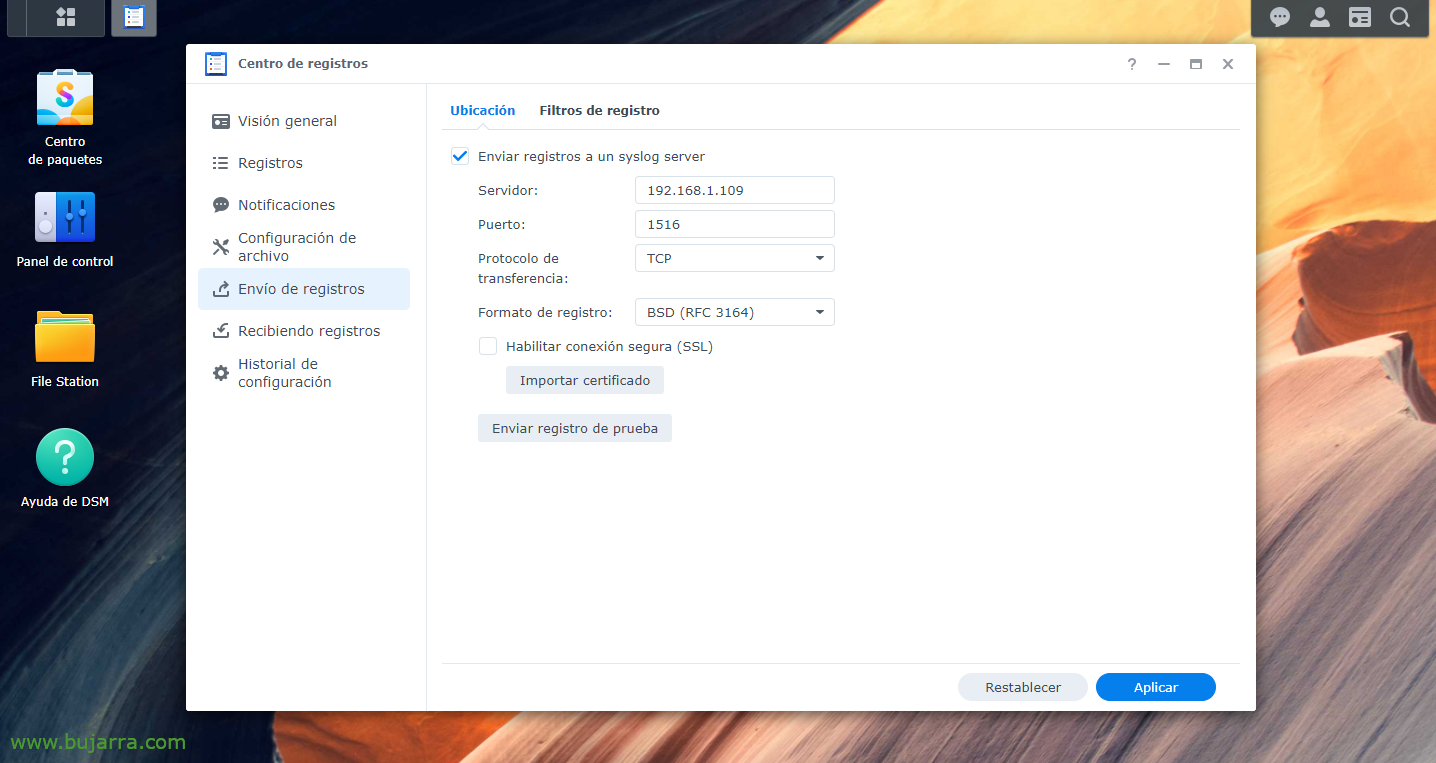
首先,我们显然必须安装 Elastic Stack 部分, 什么Logstash, Elasticsearch 和琵琶; 然后是指示我们的 Synology 将日志发送到 Logstash, 前往我们选择的港口, 我们将发明一个, 从 “记录中心” > “发送日志” > 我们使 “将日志发送到 syslog 服务器”, 我们指明 Logstash IP 以及您选择的端口和 TCP 或 UDP. 我们应用更改.
输入 {
TCP 协议 {
类型 => "群晖科技"
端口 => "1516"
标签 => ["群晖科技"]
}
}
滤波器 {
如果 [类型] == "群晖科技" {
格罗克 {
匹配 => { "消息" => [
"^<%{POSINT:syslog_pri}>%{SYSLOG 时间戳:syslog_timestamp} %{主机名:host_title} WinFileService 事件: %{词:行动}, 路径: %{GREEDYDATA:路径}, 文件/文件夹: %{词:path_type}, 大小: %{BASE10NUM:file_size} %{词:file_size_unit}, 用户: %{用户名:用户名}, 知识产权: %{知识产权:src_ip}",
"^<%{POSINT:syslog_pri}>%{SYSLOG 时间戳:syslog_timestamp} %{主机名:host_title} 连接: 用户 \[%{用户名:用户名}\] 从 \[%{主机名:团队}\(%{知识产权:src_ip}\)\] 通过 \[%{数据:协议}\] %{GREEDYDATA:消息} \[%{数据:shared_folder}\]",
"^<%{POSINT:syslog_pri}>%{SYSLOG 时间戳:syslog_timestamp} %{主机名:host_title} 连接: 用户 \[(%{用户名:用户名})?\] 从 \[%{知识产权:src_ip}\] %{GREEDYDATA:消息}",
"^<%{POSINT:syslog_pri}>%{SYSLOG 时间戳:syslog_timestamp} %{主机名:host_title} 连接[%{INT 系列:Id_proc}\]: 系统: %{GREEDYDATA:消息}",
"^<%{POSINT:syslog_pri}>%{SYSLOG 时间戳:syslog_timestamp} %{主机名:host_title} 系统 %{用户名:用户名}: %{GREEDYDATA:消息}"
]
}
}
}
}
输出 {
如果 ([类型]=="群晖科技"){
ElasticSearch 服务 {
索引 => "群晖-%{+YYYY.MM.dd}"
主机=> "DIRECCION_IP_ELASTICSEARCH:9200"
}
}
}
现在我们转到 Logstash, 在那里,我们可以创建过滤器来分隔我们收到的不同日志的不同字段. 一如既往的改进, 但这些 Groks 至少对我们有好处 7.0. 所以我们创建了一个配置文件, 例如:'/etc/logstash/conf.d/synology.conf’ 有了这些内容,我们将做一些事情.

创建配置文件后, 请记得重启 Logstash 服务以重新加载. 事后一如既往, 我们将转到 Kibana,一旦数据进入,我们就可以转到 “Management” > “堆栈管理” > “Kibana” > “索引模式” > “Create index pattern” 创建索引模式, 正如我所说, 照常 (在这种情况下,不带引号) 'synology-*' 的 URL,我们将将数据正确存储在 Elasticsearch 中. 现在我们可以从 “分析学” > “发现”我们的 Synology 索引并可视化它正在收集数据.

然后, 在 Kibana 中创建索引后, 现在,在我们的 Grafana 中,我们应该创建一个指向我们的 Elasticsearch 和 Synology 索引的“数据源”. 然后让你的想象力自由驰骋, 制作具有不同 Dashboard 的 Dashboard, 使用不同的数据进行可视化, 风格之一 桑基 查看源/目标 IP 和正在发送的流量, 列格式, 在僵局 要查看特定数据,例如正确的登录信息, 不對, 联系, 创建的文件, 修改, 消除, 执行操作的用户...