
Habilitando la deduplicación en Windows 2012 R2

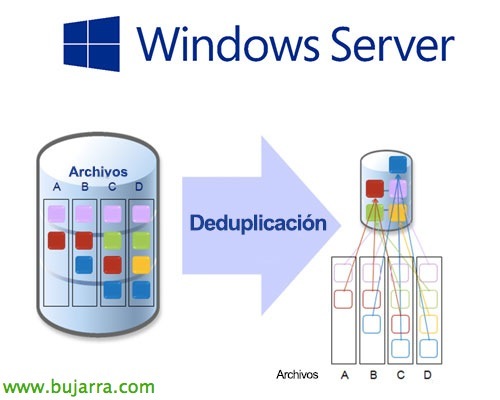
Una de grandes las novedades que trajo Windows Server 2012 es la posibilidad de deduplicar el contenido de un volumen, esta importantísima tecnología de ahorro en disco nos la daban hasta ahora las cabinas de almacenamiento de media/alta gama, a partir de ahora podremos también desde el propio OS optimizar el espacio del disco!

La deduplicación básicamente consiste en separar los datos del disco duro en pequeños bloques, analizar los bloques que se repiten, y crear punteros eliminando todos los bloques repetidos, con esto podremos tener un ahorro muy importante a la hora de almacenar información, dependerá del contenido almacenado, pero cuántos más bloques similares más ahorraremos 😉
No podremos habilitar la deduplicación en volúmenes de sistema, ni de arranque, ni formateados con ReFS, ni volúmenes CSV (Cluster Shared Volumes). Deberían estar particionados como MBR o GUID y en NTFS, podrán ser volumenes locales o de una red de almacenamiento como iSCSI, FC… Disponemos de la herramienta ‘DDPEval.exe’ en %WinDir%System32″ una vez hayamos instalado el rol en el servidor para no tener que forzar una deduplicación y esta herramienta nos indique cuánto liberaríamos! No se recomienda deduplicar volúmenes con BD tipo SQL Server o Exchange Server ya que se pueden corromper, en tal caso podríamos excluir sus directorios. En entornos con Hyper-V se recomienda usarlo cuando dispongamos un volumen con VHD de escritorios virtuales similares, no en toda la plataforma como tal con distintos servidores… aún así siempre se debería configurar la programación de la tarea de deduplicación cuando no coincida con cargas de trabajo o backups.

Bien, para habilitar la deduplicación, agregaremos el rol de ‘Desduplicación de datos’ dentro del rol de ‘Servicios de archivos y almacenamiento’.

Posteriormente, en el “Administrador del servidor”, en “Servicios de archivos y de almacenamiento” > “Volumenes”, podremos sobre cada volumen con botón derecho entrar en “Configurar desduplicación de datos…”. Si nos fijamos, en este ejemplo lo realizaré sobre el volumen F: de 300Gb y que tan sólo tiene 5Gb libres.

Podremos seleccionar el tipo de deduplicación a realizar, si sobre un volumen que almacena ficheros o uno que almacena máquinas virtuales (normalmente escritorios de VDI). Indicaremos los ficheros a deduplicar, los que tengan más de X días o podremos excluir ciertas extensiones para que sean excluidos, así como seleccionar carpetas a excluir o archivos en concreto. Seleccionamos “Establecer programación de desduplicación…”,

Y configuramos una o dos programaciones para que analice los ficheros del volumen y realice su deduplicación!

Bien, podremos ver el estado de la deduplicación desde PowerShell con ‘get-DedupStatus’, y si queremos iniciar inmediatamente el trabajo que acabamos de programar de deduplicación bastará con ejecutar ‘start-DedupJob DISCO: -type optimization’.

Podremos ir verificando el estado del trabajo con ‘get-DedupJob’ donde podremos ver el % avanzado, para volver a ver el estado de la deduplicación en el volumen lo haremos con ‘get-DedupStatus’, iremos verificando cuánto vamos optimizando!!

O podremos visualmente, volver al “Administrador del servidor” y actualizar los volúmenes, en este en concreto teníamos antes 5Gb libres y ahora 146Gb! Si querríamos volver al origen por alguna razón y des-deduplicar el contenido recientemente optimizado ejecutaremos ‘start-DedupJob DISCO: -type Unoptimization’.










