

Ollama, empezando con la IA local

Desde hace unos mesecitos estaba trasteando con una IA local y open source; y quería compartir un poco con vosotros en una serie de posts algunas de sus posibilidades en nuestro día a día. Pero en este primer documento veremos cómo podemos montarlo y unas nociones básicas de sus posibilidades.
Lo primero, si os parece os cuento para qué la uso actualmente por si os puede servir de idea; por ahora, exclusivamente para generar texto, puede ser pobre, pero es un mundo muy amplio. Que abarca desde la recepción de cualquier sistema de notificación o alertas, te hace más humana la alerta o te puede sugerir por donde comenzar su resolución. Para enviar mails periódicos, mails que manda mi organización diarios, mensuales… pues les da otro toque, los alimenta con ciertos datos y los hace muy reales. También para el sistema domótico, me permite mantener conversaciones con el Hogar, me alerta, usando la voz, distintas frases…
Por ahora, lo dicho, para generar texto; pero las posibilidades son muchas, como pueda ser la conexión a bases de datos y que nos permita hacer consultas con un lenguaje natural. O la posibilidad de entablar conversaciones y preguntas referentes a un documento que le hayamos enviado a la IA, o una imagen y que nos describa qué ve… A lo largo del documento iré poniendo algún ejemplo sencillo para que se haga algo ameno.

Lo segundo, bien, cómo se llama esto… como os imaginaréis hay muchas opciones y posibilidades, yo voy a hablaros de Ollama (Open-source Library for AI Models and Applications). Ollama nos permitirá usar LLM (Large language model), esto es, modelos de lenguage entrenados para la IA, podrán ser de código abierto o de pago, podrán ser 100% offline o no, al gusto. Obviamente y dependiendo el LLM que usemos necesitaremos más o menos potencia, esto es, tener una GPU para que las respuestas sean inmediatas. Podremos usar la API de Ollama para hacerle preguntas de manera remota con otros sistemas, muy muy potente. Y os recomiendo Open WebUI como interfaz GUI para Ollama, así con nuestro navegador tendremos la interfaz que esperas para poder trabajar con tu IA cómodamente.
Lo dicho, necesitaremos una GPU para tener el mejor rendimiento posible, dependerá del LLM que usemos y los GB que requiera cada modelo, de esta manera las respuestas serán inmediatas. En cuanto al hardware compatible es bastante extenso (NVIDIA, AMD, Apple M1…), os dejo aquí su listado.
El artículo lo voy a separar en:
- Instalación de Ollama y Open WebUI rápida en un Windows, Mac o Linux
- Instalación de Ollama y Open WebUI en una MV Linux en Proxmox con Docker
- Acceso por Open Web UI y primeros pasos
- Reconocimiento de imágenes
- Interactuando con documentos
- Varios
Instalación de Ollama y Open WebUI rápida en un Windows, Mac o Linux
Si lo que pretendes es probarlo, ya y rápido, esta es la opción, ya que podrás instalar Ollama en tu Linux, Mac o Windows, por si la quieres correr en local, con tu GPU. Iremos a la web de descargas de Ollama, seleccionaremos nuestro SO y nos lo descargamos, Next, Next e Instalado.
En Linux nos lo bajaremos e instalaremos de la siguiente manera:
curl -fsSL https://ollama.com/install.sh | sh >>> Downloading ollama... ######################################################################## 100,0%##O#-# >>> Installing ollama to /usr/local/bin... >>> Creating ollama user... >>> Adding ollama user to render group... >>> Adding ollama user to video group... >>> Adding current user to ollama group... >>> Creating ollama systemd service... >>> Enabling and starting ollama service... Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service. >>> NVIDIA GPU installed.
Y podremos directamente si queremos desde shell bajarnos un LLM y probarlo:
ollama run mistral pulling manifest pulling e8a35b5937a5... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 4.1 GB pulling 43070e2d4e53... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 11 KB pulling e6836092461f... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 42 B pulling ed11eda7790d... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 30 B pulling f9b1e3196ecf... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 483 B verifying sha256 digest writing manifest removing any unused layers success >>> hola Hola! That means "hello" in Spanish.
Si queremos que responda a consultas API deberemos editar el fichero del servicio ‘nano /etc/systemd/system/ollama.service ‘ añadiendo:
Environment="OLLAMA_HOST=0.0.0.0:11434"
Y recargamos el servicio:
sudo systemctl daemon-reload sudo systemctl restart ollama
Y si queremos tener la GUI para gestionar nuestra IA desde el navegador deberemos montar Open WebUI, lo más rápido y cómodo en un contenedor de Docker:
git clone https://github.com/open-webui/open-webui.git cd open-webui/ sudo docker compose up -d

Y ya podremos abrir el navegador atacando a la IP de la máquina al puerto 3000tcp (por defecto).
Instalación de Ollama y Open WebUI en una MV Linux en Proxmox con Docker
Y esta parte os cuento el porqué… Mi idea es tener una máquina para IA centralizada, una máquina a la que distintos sistemas la puedan apuntar para hacerle distintas consultas, para ello, debe ser una máquina virtual (por el tema de las ventajas, alta disponibilidad, backup, snapshots…), una MV a la que le hagamos passthrough de la tarjeta gráfica y tenga la GPU para ella. Para ello usaremos Proxmox, (un día hablamos del suicidio de VMware) y la MV será un Ubuntu Server 24.04. Y ya que estamos, en esa MV correrá Ollama y Open WebUI en contenedores Docker.
Os dejo los pasos que seguí para hacer passthrough de la tarjeta gráfica en Proxmox, no sé si son los más correctos, pero funciona perfectamente.
Tras instalar Proxmox 8.2, configurarlo mínimamente, haberle ejecutado los Proxmox VE Post Install de los Proxmox VE Helper-Scripts, vamos a decirle a Proxmox que no use esa Gráfica PCIe, comenzamos editando GRUB con ‘nano /etc/default/grub’ y modificamos la siguiente línea:
#GRUB_CMDLINE_LINUX_DEFAULT="quiet" GRUB_CMDLINE_LINUX_DEFAULT="quiet intel_iommu=on iommu=pt vfio_iommu_type1 initcall_blacklist=sysfb_init" INTEL --> GRUB_CMDLINE_LINUX_DEFAULT="quiet intel_iommu=on" AMD --> GRUB_CMDLINE_LINUX_DEFAULT="quiet amd_iommu=on"
Y ejecutamos
update-grub
Añadimos los siguientes módulos con ‘nano /etc/modules’:
vfio vfio_iommu_type1 vfio_pci vfio_virqfd
Bloqueamos los drivers con ‘nano /etc/modprobe.d/blacklist.conf’:
blacklist nouveau blacklist nvidia blacklist nvidia* blacklist radeon
Apuntamos los IDs con: ‘spci -n -s 01:00’, como podréis ver, si hay algún curioso, en mi caso es una NVIDIA RTX 3060 12GB conectada al PCIe 1.
01:00.0 0300: 10de:2504 (rev a1) 01:00.1 0403: 10de:228e (rev a1)
Editamos ‘nano /etc/modprobe.d/vfio.conf’
options kvm ignore_msrs=1x options vfio-pci ids=10de:2504,10de:228e disable_vga=1
Editamos ‘nano /etc/modprobe.d/kvm.conf’
options kvm ignore_msrs=1
Y finalmente editamos ‘nano /etc/modprobe.d/iommu_unsafe_interrupts.conf’
options vfio_iommu_type1 allow_unsafe_interrupts=1"
Ya os digo que seguramente algún paso me sobre para el passthrough de la tarjeta gráfica en Proxmox, pero tras reiniciar el host veréis cómo se puede perfectamente agregar la GPU a una MV.

El siguiente paso, será crear la MV en Proxmox, os dejo algunas cosas que tuve en cuenta; en la pestaña ‘System’ deberemos indicar ‘q35’ como tipo de máquina, y en las opciones de BIOS escoger ‘OVMF (UEFI)’,
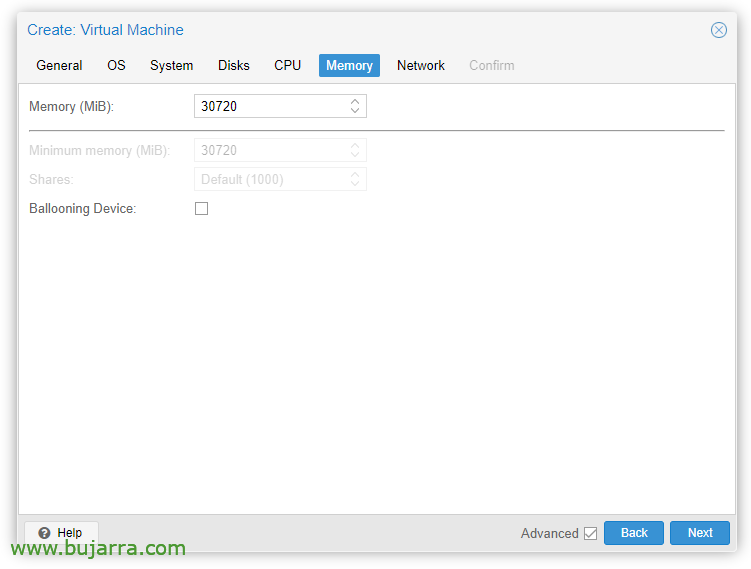
En la pestaña de ‘Memory’ deberemos desmarcar ‘Ballooning Device’
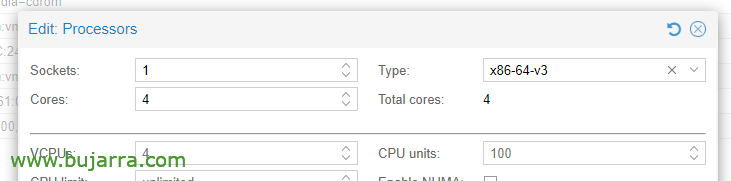
En las opciones de la CPU, editando los procesadores, en el Tipo, debemos elegir al menos x86-64-v3.
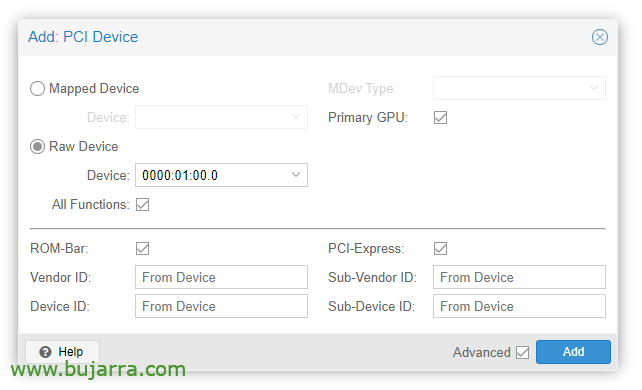
Una vez creada la MV ya podremos añadirla un dispositivo PCI, editamos el hardware de la MV y “Add” > “PCI Device”. Marcamos All Functions, ROM-bar, Primary GPU y PCI-Express.
Obviamente en esa tarjeta gráfica conectaremos un monitor para realizar la instalación del SO (Ubuntu Server 24.04) y verla en pantalla. Tendremos que hacer también passthrough de un teclado/ratón USB para hacer la instalación.
A continuación podremos instalar el SO en la MV, deberemos tener en cuenta de instalar los drivers, en Ubuntu Desktop creo que se instalan durante la instalación y en el Server también marcando un ‘tick’, si no, de todas formas podremos instalarlos:
sudo ubuntu-drivers install sudo apt-get update sudo apt-get upgrade sudo reboot
Tras reiniciar la MV vemos si ha cargado correctamente con ‘cat /proc/driver/nvidia/version’
NVRM version: NVIDIA UNIX x86_64 Kernel Module 535.171.04 Tue Mar 19 20:30:00 UTC 2024 GCC version:
Continuaríamos con la instalación de Docker (doc oficial) en la MV Ubuntu:
sudo apt-get update sudo apt-get install ca-certificates curl sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc sudo chmod a+r /etc/apt/keyrings/docker.asc echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \ $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
Debemos instalar ahora el NVIDIA Container Toolkit (doc oficial) y lo habilitamos para Docker:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list sudo apt update sudo apt -y install nvidia-container-toolkit sudo systemctl restart docker sudo nvidia-ctk runtime configure --runtime=docker sudo systemctl restart docker
Y ya es hora de desplegar los contenedores de Ollama y Open WebUI, para ello:
git clone https://github.com/open-webui/open-webui.git cd open-webui/
Y le añadimos estos cambios al contenedor de Ollama, para que pueda usar la gráfica y nos abra el puerto para las APIs (nano docker-compose.yaml):
runtime: nvidia environment: - NVIDIA_VISIBLE_DEVICES=all ports: - 11434:11434
Y finalmente descargamos y arrancamos los contenedores:
sudo docker compose up -d
Y ya podremos abrir el navegador atacando a la IP de la máquina virtual, al puerto 3000tcp (por defecto).
Acceso por Open Web UI y primeros pasos

La primera vez que accedamos a Open WebUI podremos crearnos una cuenta al pulsar en “Inscribirse”, crearemos una cuenta simplemente introduciendo nuestro nombre, email y una contraseña, pulsamos en “Crear una cuenta”.

Y ya desde aquí será desde donde podamos interactuar, como vemos podemos crear nuevos Chats y consultarle lo que necesitemos,
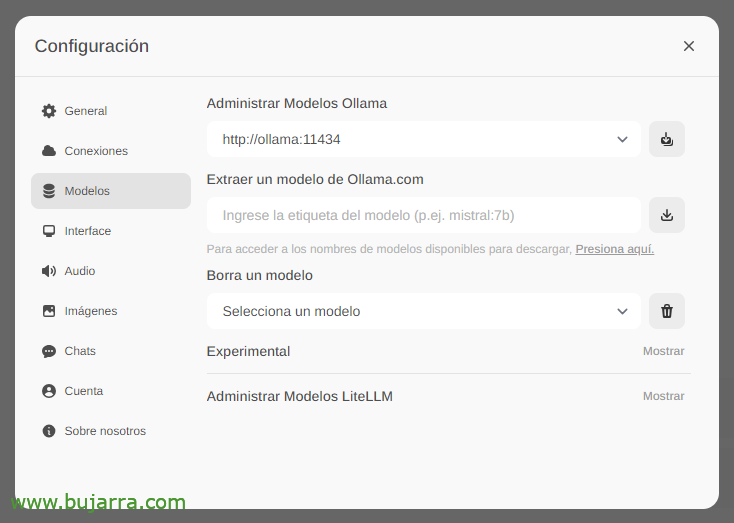
Lo primero y más importante será descargarnos los modelos de lenguaje de gran tamaño (LLM), desde ‘Configuración’ > ‘Modelos’ podremos extraerlos directamente desde Ollama.com escribimos por ejemplo mistral:7b, aunque por supuesto os recomendaré que visitéis los top LLM más usados, bastará con escribir el modelo que nos interese y pulsaremos en el icono de descarga. Os recomiendo (a día de hoy) llama3, es una autentica pasada.
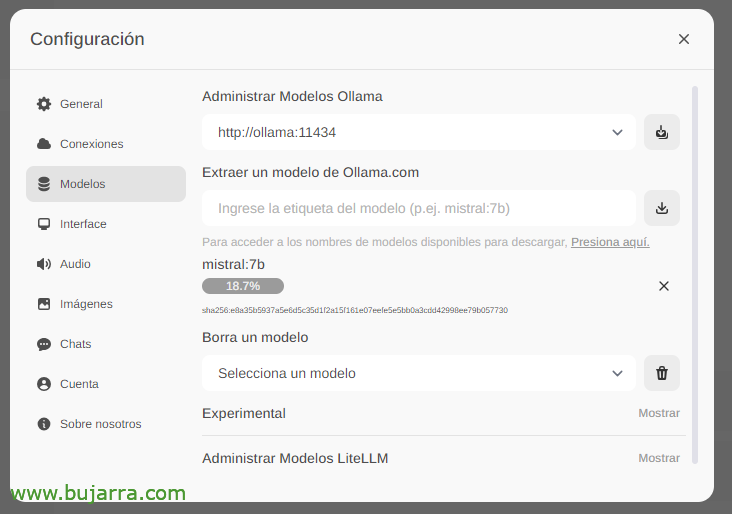
Esperamos mientras se descarga… y por supuesto que podremos bajar tantos como queramos.
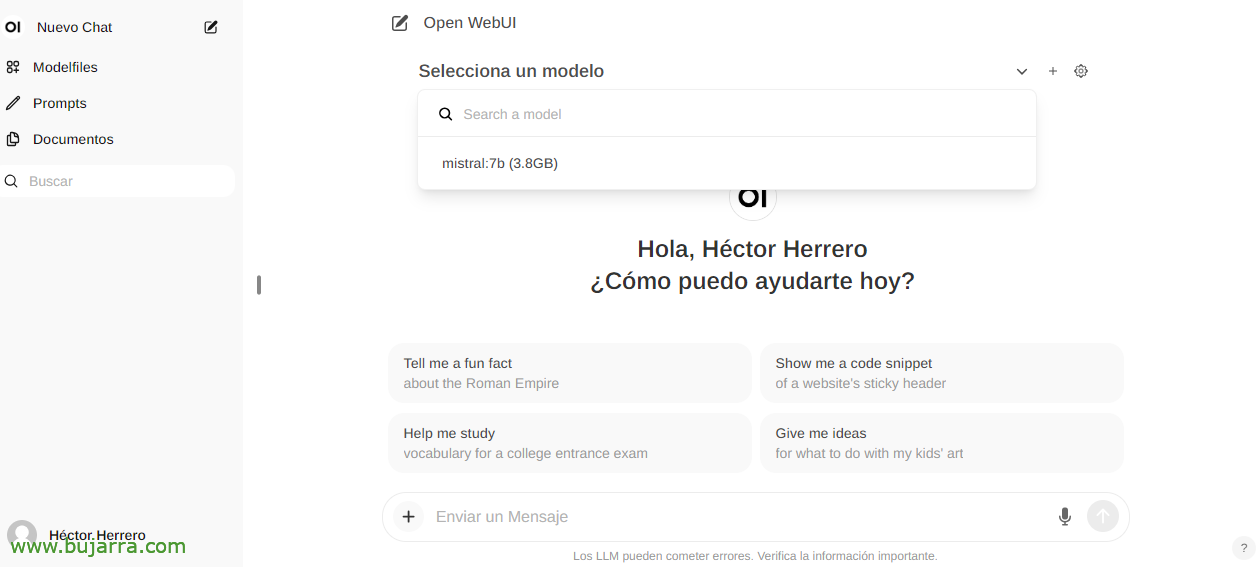
Y al crear ya un Nuevo Chat podremos escoger cualquier modelo descargado para empezar a interactuar.

Y nada, empezamos a trastear, le podemos lanzar cualquier pregunta….
Reconocimiento de imágenes

Si por ejemplo usamos el LLM de Llama2 podremos en una conversación o por API enviarle una imagen y solicitarle que nos la describa, un ejemplo impresionante con un recorte de Grafana… No os doy más pistas…
Interactuando con documentos

Por ver otro ejemplo rápido de sus posibilidades… Desde ‘Documentos’ podremos subir cualquier documento para luego mantener conversaciones sobre su contenido. Se puede subir un libro y preguntarle cosas o consejos, vaya, depende de lo que vaya el libro… O este mero ejemplo que subo un documento técnico de una migración de Directorio Activo, y…
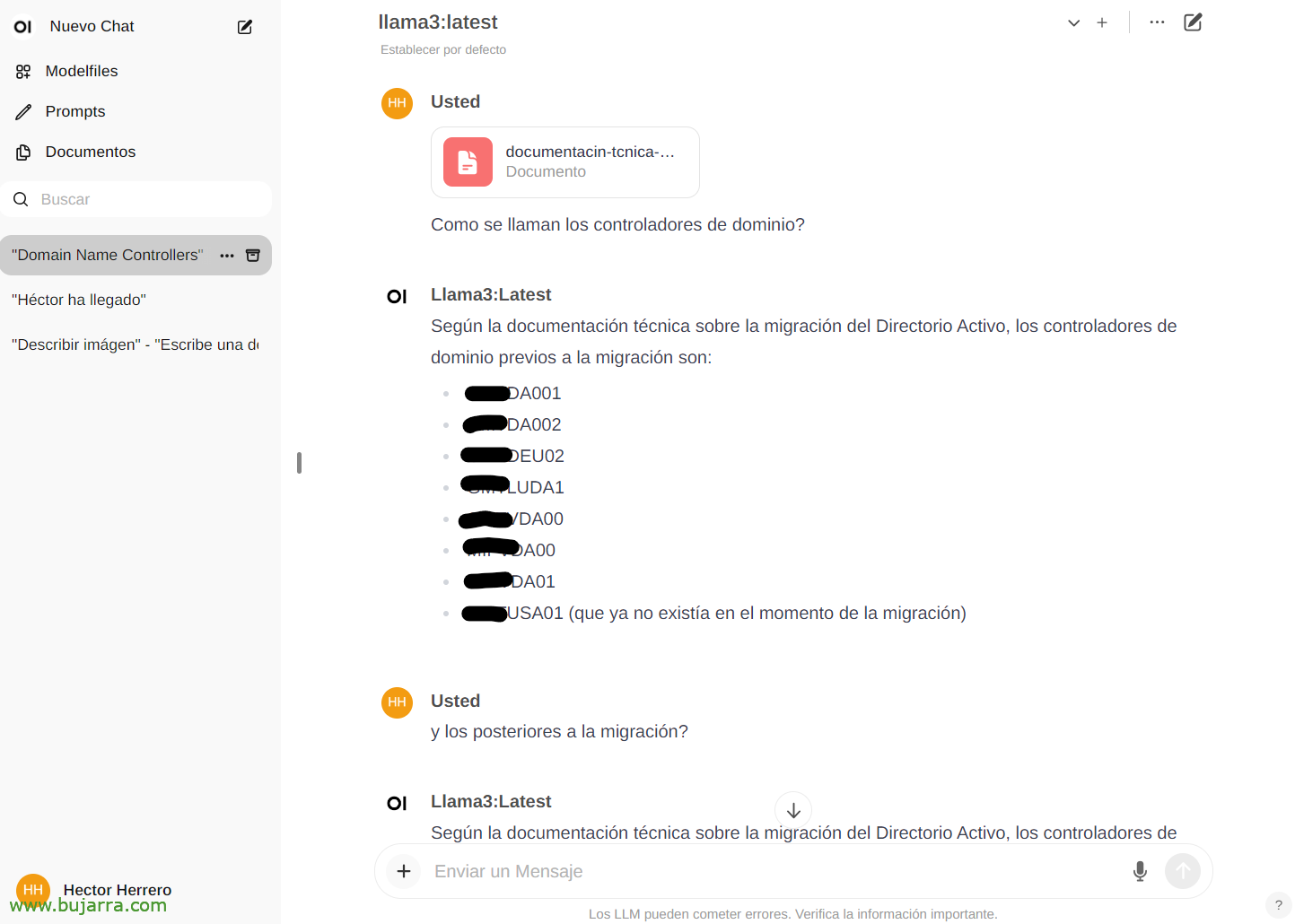
Y luego en el chat podremos consultarle sobre algún documento específico tecleando la # y seleccionando el tag que le hayamos puesto al doc. Impresionante…
Varios
Y bueno por ir finalizando el documento, veremos a futuro cositas, tiene muy muy buena pinta, no sólo e esto que hemos visto, si no todas sus posibilidades con la API por ejemplo y poder integrar cualquier sistema con nuestra IA. Una IA segura, local, gratuita, Ollama ha venido para quedarse!
En futuros posts, gracias a esta API podremos integrar las notificaciones de Centreon, de Elasticsearch, de nuestro hogar inteligente con Home Assistant, y sí llamarla por teléfono y hacerle preguntas, controlar cualquier dispositivo de casa de una manera intuitiva, recibir alertas muy curiosas y un largo etcétera…

Si queremos por ejemplo con curl tirarle una consulta de ejemplo:
curl http://localhost:11434/api/generate -d '{ "model": "mistral:7b", "prompt": "¿Conoces al Athletic de Bilbao?", "stream": false }'
{"model":"mistral:7b","created_at":"2024-03-29T12:38:07.663941281Z","response":" Sí, conozco al Athletic Club de Bilbao, es un club de fútbol profesional español con sede en la ciudad de Bilbao, País Vasco. Fue fundado el 14 de octubre de 1894 y juega actualmente en LaLiga, la primera división española de fútbol. Es conocido por su estilo de juego basado en su filosofía, que prioriza el desarrollo de jugadores de ascenso desde las categorías inferiores del club. Su estadio es el San Mamés."
O pudiendo meterle parámetros para elegir el modelo, la temperatura para que alucine más o menos, longitudes… veremos más ejemplos:
curl http://XXX.XXX.XXX.XXX:11434/api/generate -d '{ "model": "mistral:7b", "prompt": "¿Conoces al Athletic de Bilbao?", "stream": false, "temperature": 0.3, "max_length": 80}'
Bueno, no me enrollo más, para hacernos una idea de las posibilidades creo que nos vale 🙂 Iremos viendo más cositas y curioseando. Y la verdad que algunas cosas las tengo que omitir por que las uso en mi negocio y son valores diferenciales que muchas veces ya sabéis lo que pasa con los proveedores rivales…
Un abracete y desearos muy buena semana!










