
Monitorizando el SLA de los Hosts en Centreon

Este documento lo usaremos para conocer el % de disponibilidad de las máquinas monitorizadas en Centreon. Si disponemos de algún SLA (Acuerdo de Nivel de Servicio) que cumplir, podremos medirlo desde Centreon así como alertarnos. Ah y si usas Grafana también lo veremos desde ahí!
Lo dicho, al final de este post sabrás cómo medir el SLA que ofrece cada máquina que tengas monitorizada, le asociaremos un Servicio a cada Host de Centreon para conocer la disponibilidad que ofrece dicha máquina. Así tendrás también su histórico y si te interesase podrías recibir alertas cuando el % sea menor del valor que te interese. Y al final eso, si usáis Grafana para visualizar vuestra monitorización de Centreon, os diré cómo visualizo ese dato, por si os aporta algo 🙂
Por cierto, igual te interesa, en este post vimos algo similar, vimos cómo obtener el SLA de los Servicios de Centreon. Hoy tocan los Hosts.
Para poder medir el SLA necesitaremos hacer una consulta a la propia base de datos de Centreon, que está basada en MariaDB (o MySQL), así que si no lo tienes, antes necesitas revisar este post para poder hacer queries a cualquier BD de MySQL.
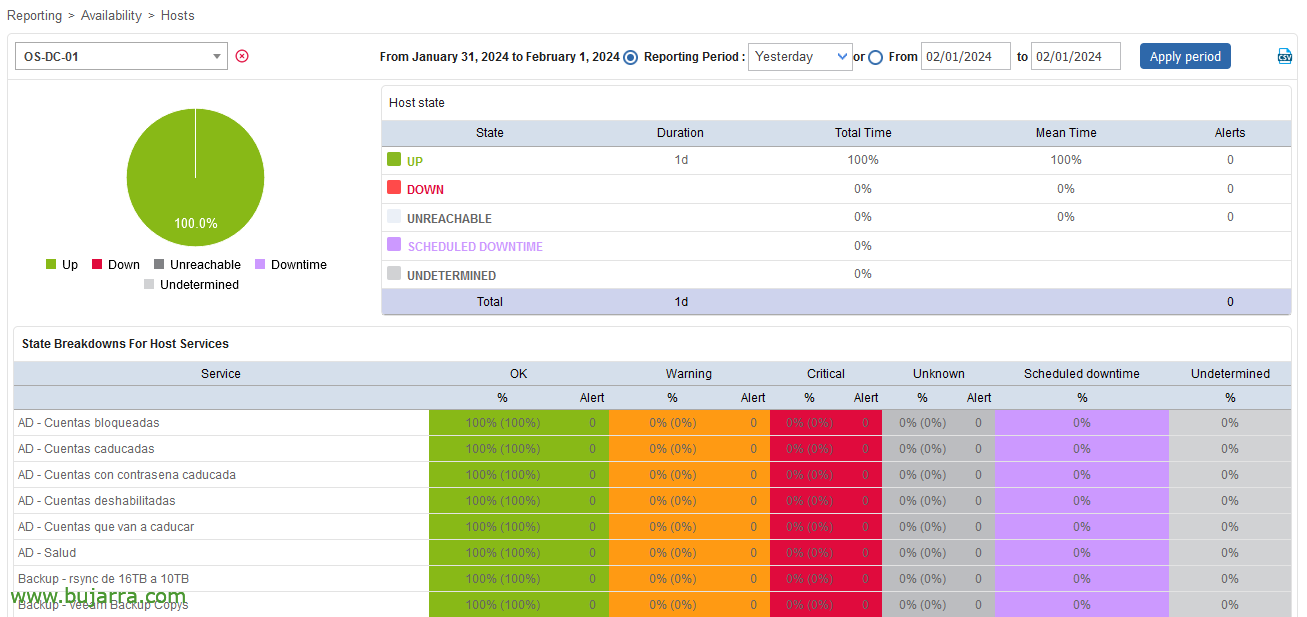
De todas formas, recordar que en Centreon el SLA se puede ver por GUI desde “Reporting” > “Availability” > “Hosts”. Nosotros obtendremos esos mismos valores, pero los monitorizaremos, eso es lo importante!

Empezamos! Como siempre empezaremos por el Comando, una vez definamos este primer Comando, lo podremos usar tantas veces como necesitemos. En concreto este comando nos dará el % que ha estado una máquina en estado OK, el % de tiempo que ha estado bien. Como argumentos lleva (i) los días que quieres mirar atrás para calcular el SLA, 1 día, 7 días, 30 días, 365 días… (ii) el nombre de la máquina, que realmente lo podría haber cogido con una variable de Centreon y no preguntarlo, (iii) el valor que quieres de Warning y (iv) el de Critical, para que te alerte, menos de esos valores serán considerados alerta. os dejo el Comando:
$CENTREONPLUGINS$/Nagios-Plugins/check_mysql_query.pl -q "SELECT ROUND((SUM(UPTimeScheduled)/($ARG1$ * 86400))*100,2) as porcentaje FROM hosts, log_archive_host WHERE log_archive_host.host_id = hosts.host_id AND hosts.name = '$ARG2$' AND from_unixtime(date_end) > date_sub(now(), INTERVAL $ARG1$ day) order BY date_end DESC" -H DIRECCION_IP_CENTREON_CENTRAL -d centreon_storage -u 'USUARIO_MYSQL' -p 'CONTRASEÑA_MYSQL' -t 60 --no-querytime -g -l 'SLA' -U % -w $ARG3$: -c $ARG4$: -m 'El SLA es del' -n
Si en vez de % queréis ver el tiempo que ha estado levantada, podremos cambiar la query por algo como esto:
$CENTREONPLUGINS$/Nagios-Plugins/check_mysql_query.pl -q "SELECT CONCAT(FLOOR(HOUR(sec_to_time(SUM(UPTimeScheduled))) / 24), 'd_', MOD(HOUR(sec_to_time(SUM(UPTimeScheduled))), 24), 'h_', MINUTE(sec_to_time(SUM(UPTimeScheduled))), 'm') AS Tiempo FROM hosts, log_archive_host WHERE log_archive_host.host_id = hosts.host_id AND hosts.name = '$ARG2$' AND from_unixtime(date_end) > date_sub(now(), INTERVAL $ARG1$ day) order BY date_end DESC" -H DIRECCION_IP_CENTREON_CENTRAL -d centreon_storage -u 'USUARIO_MYSQL' -p 'CONTRASEÑA_MYSQL' -t 60 --no-querytime -T -g -l 'SLA'
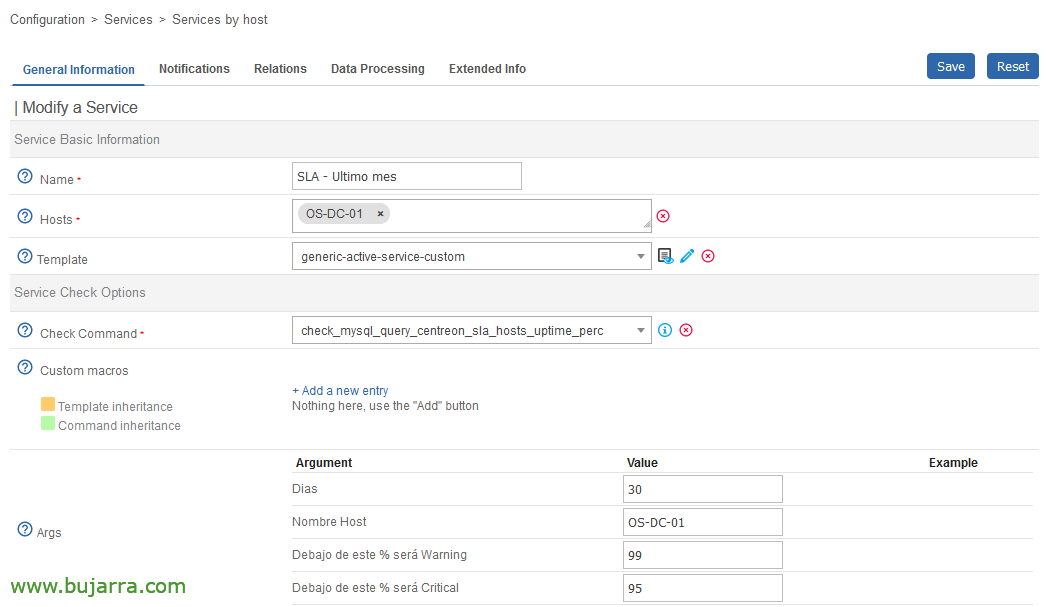
Una vez creado el Comando, ya podríamos crear tantos Servicios como necesitemos y asociarlos a nuestros Hosts, este ejemplo nos mostrará el SLA del último mes de esta máquina, nos dará Warning cuando el SLA sea menor al 99% y lanzará mensaje de Critical cuando sea menor del 95%.
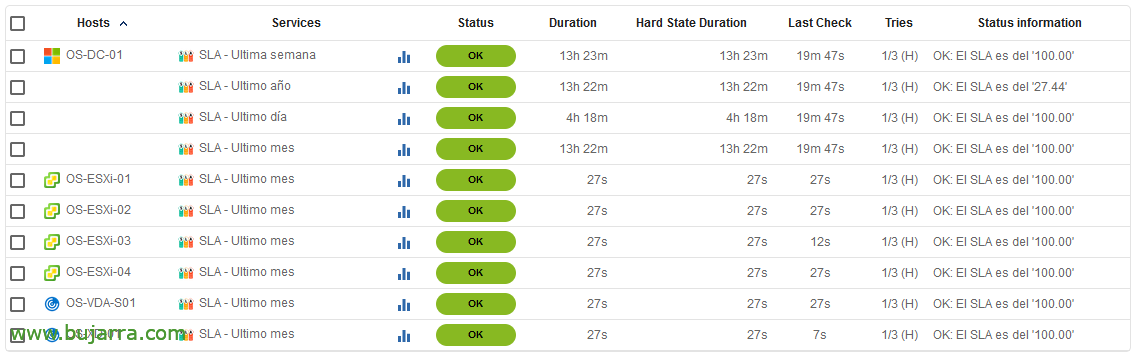
Tras grabar y exportar la configuración de Centreon, ya podremos ver los resultados.En un momentito podemos llegar a controlar el SLA de cada equipo, medirlo y mejorarlo, o usarlo cuando se nos solicite. Tener en cuenta que este script no debe ejecutarse antes de las 6am ya que Centreon internamente en la BBDD no ha generado los datos de dicho día y nos puede dar algo falseada la info, así que lo mejor es ponerle una programación particular.
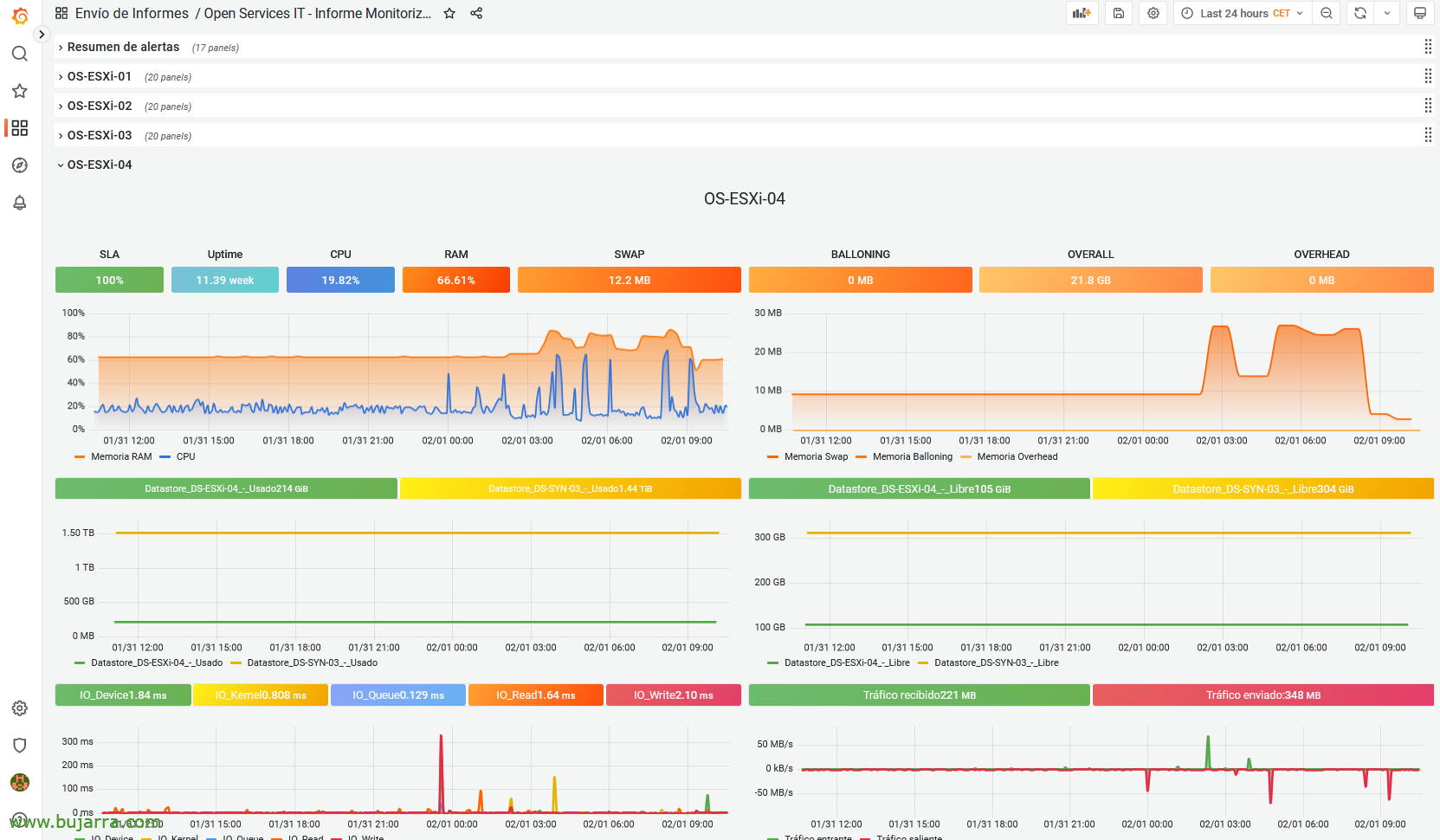
Y si tenéis Grafana y veis datos de monitorización, podemos calcular el SLA en base al periodo del tiempo de la gráfica, para ello, si os fijáis, hay un panel donde se ve el SLA.
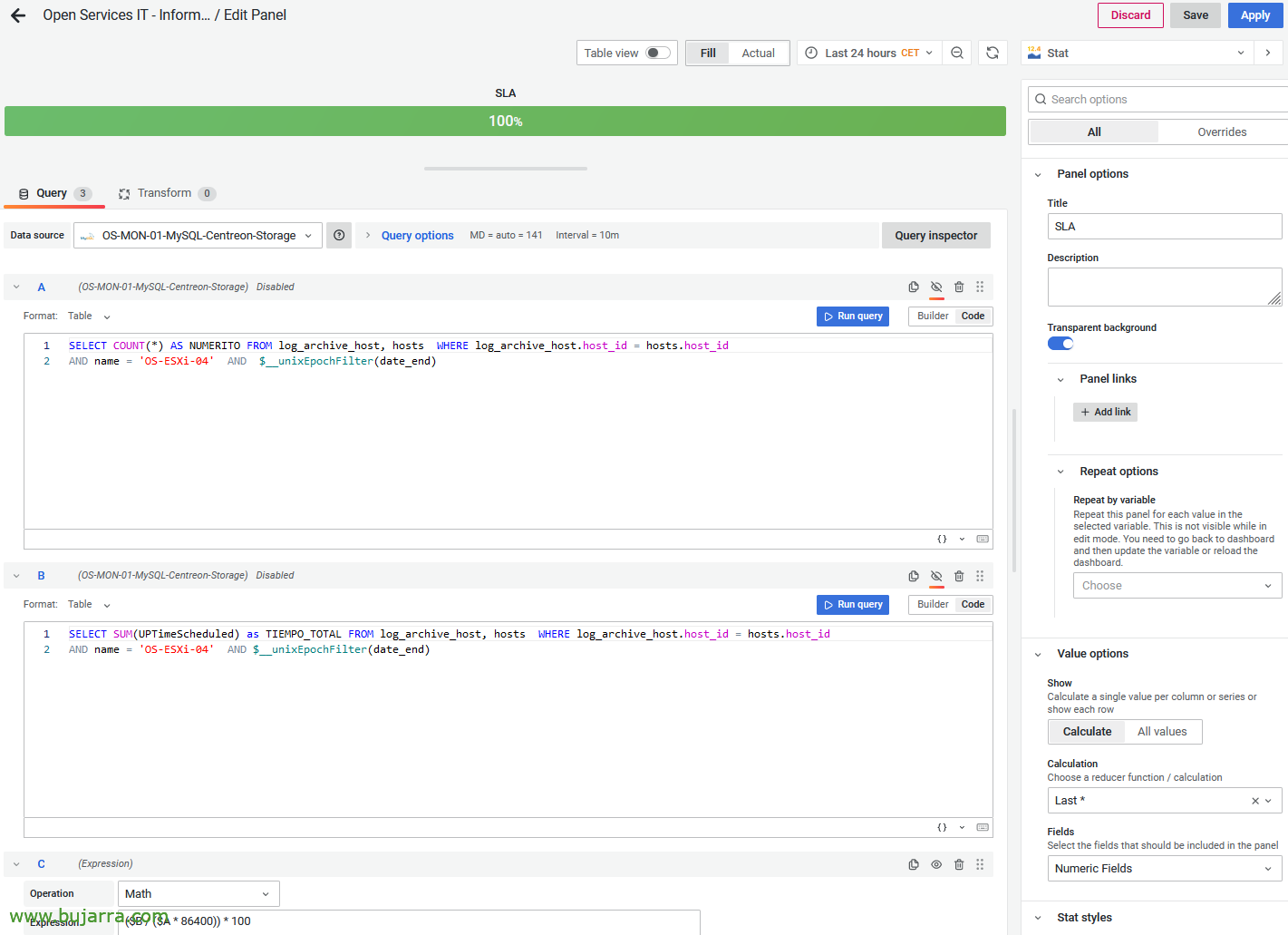
Si editamos el panel de tipo ‘estadística’, calculo el SLA obteniéndolo de 2 consultas, la primera obtendrá los días de la query (en base a lo que se seleccione en Grafana, 24h, 1 mes…); y la segunda obtiene en segundos cuánto tiempo ha estado el equipo en estado OK. Si os fijáis ambas queries están ocultas, y hay una tercera query que es de tipo matemático y obtiene el % en base a estos dos valores. os dejo las 2 queries usadas:
SELECT COUNT(*) AS NUMERITO FROM log_archive_host, hosts WHERE log_archive_host.host_id = hosts.host_id AND name = 'NOMBRE_DE_HOST' AND $__unixEpochFilter(date_end)
SELECT SUM(UPTimeScheduled) as TIEMPO_TOTAL FROM log_archive_host, hosts WHERE log_archive_host.host_id = hosts.host_id AND name = 'NOMBRE_DE_HOST' AND $__unixEpochFilter(date_end)
($B / ($A * 86400)) * 100
Así podremos ver y demostrar el SLA que cumplimos por cada máquina que ofrece servicios en nuestra organización, os recuerdo que antes puse un enlace a medir el SLA de los servicios, que depende qué necesitemos sería la otra opción.
Espero como siempre que vaya muy bien, que os cuidéis y os mando un abrazo!










