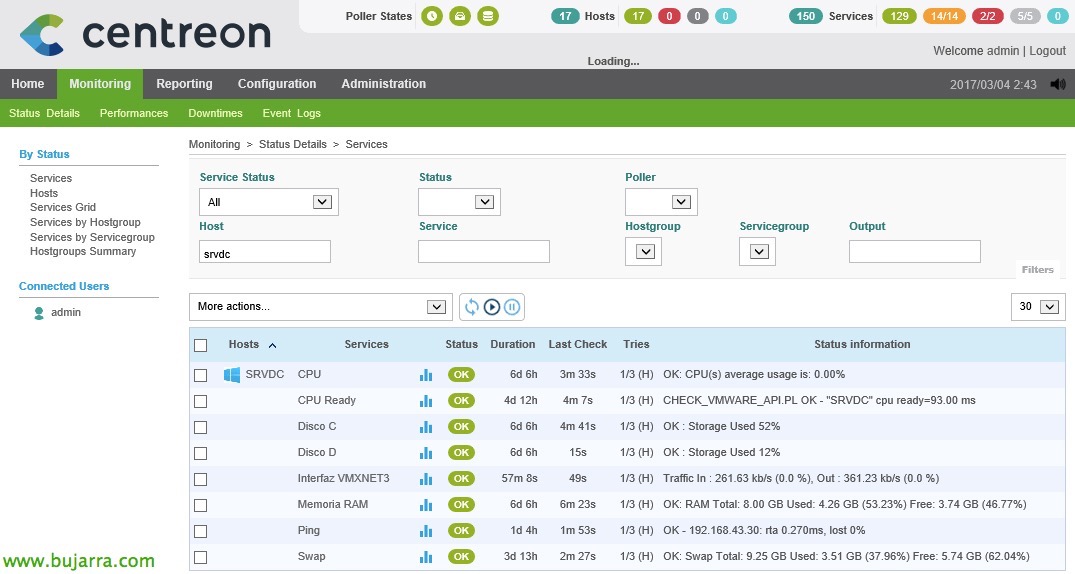
Nagios – Monitoraggio dei nostri host ESXi

In questo documento, esamineremo tutti i passaggi necessari per poter monitorare un host ESXi, vedremo i parametri più comuni e i valori che possiamo ottenere per avere un ambiente controllato grazie a Nagios e Centreon! Tutte le informazioni che possiamo ottenere sono incredibili! In altri documenti vedremo altre informazioni che possiamo ottenere da vCenter e dalle sue VM, Oggi i padroni di casa giocano!

Installazione dei requisiti,
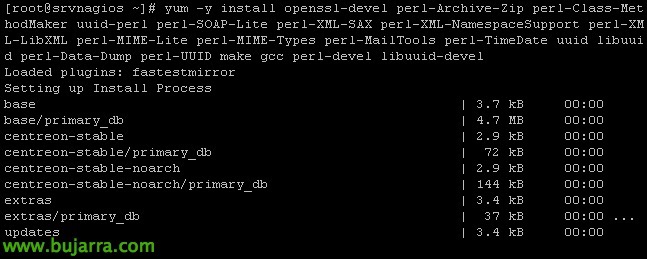
Inizieremo prima installando tutti i requisiti necessari per utilizzare uno degli script più comuni che possiamo utilizzare. In Borsa di Nagios Saremo in grado di ottenere quasi tutti gli script di cui abbiamo bisogno, e da lì ne scaricheremo uno che di solito uso per monitorare gli host ESXi 4.x, 5.x o 6.x. Ma prima dovremo installare l'SDK VMware sulla macchina nagios così come tutto il necessario prima.
Dopo aver installato e testato tutti i requisiti che lo script per monitorare i server ESXi funzioni, ora saremo in grado di uscire dalla console e utilizzare l'interfaccia Centreon per creare gli host ESXi, i servizi che monitoreremo e i comandi necessari. Spero che sia ben compreso, per seguire i passaggi!
Installazione dei requisiti:
[Codice sorgente]yum -y install openssl-devel perl-Archive-Zip perl-Class-MethodMaker uuid-perl perl-SOAP-Lite perl-XML-SAX perl-XML-NamespaceSupport perl-XML-LibXML perl-MIME-Lite perl-MIME-Types perl-MailTools perl-TimeDate uuid libuuid perl-Data-Dump perl-UUID make gcc perl-devel libuuid-devel cpan[/Codice sorgente]

Cerchiamo nel sito Web di download di VMware, vSphere SDK per Perl, Scarichiamo il pacchetto GZ da 64 pezzo.

Lo carichiamo sul server Nagios utilizzando WinSCP per esempio e lo lasciamo nella directory temporanea '/tmp/'. Lo decomprimiamo e lo installiamo:
[Codice sorgente]tar xvzf VMware-vSphere-Perl-SDK-xxxxxxx.tar.gz
cd vmware-vsphere-cli-distrib/
./vmware-install.pl[/Codice sorgente]

Lo installiamo con i parametri predefiniti,

E dopo pochi secondi lo avremo installato,

Installiamo UUID:
[Codice sorgente]cd /usr/src
WGET HTTP://search.cpan.org/CPAN/authors/id/J/JN/JNH/UUID-0.04.tar.gz
tar -xzvf UUID-0.04.tar.gz -C /opt[/Codice sorgente]

Lo compiliamo:
[Codice sorgente]cd /opt/UUID-0.04
Perla Makefile.PL
fare[/Codice sorgente]
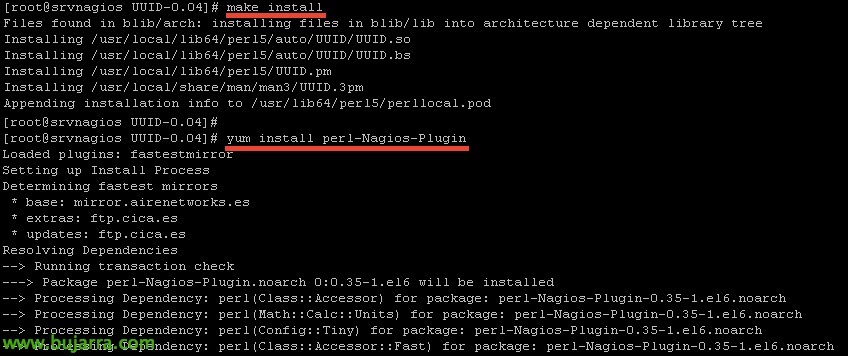
E l'abbiamo installato, così come 'perl-Nagios-Plugin’ anche questo sarà necessario:
[Codice sorgente]fare installare
yum install perl-Nagios-Plugin[/Codice sorgente]

Installiamo più requisiti:
[Codice sorgente]CPAN GAAS/libwww-perl-5.837.tar.gz[/Codice sorgente]

E stiamo finendo con quest'ultimo!
[Codice sorgente]Monitoraggio cpan::Plugin[/Codice sorgente]

Finalmente, Saremo in grado di scaricare lo script che ci permetterà di ottenere informazioni dagli host qui https://exchange.nagios.org/directory/Plugins/Operating-Systems/*-Virtual-Environments/VMWare/check_vmware_api/details Una volta scaricato, lasceremo il file 'check_vmware_api.pl’ su '/usr/lib/centreon/plugins/’ E lo renderemo eseguibile con 'chmod +x check_vmware_api.pl'. Proveremo a eseguirlo e se tutto è corretto apparirà questa schermata che indica le opzioni che possiamo utilizzare.
Creazione di un utente privilegiato in ESXi,
Lo script sopra, dovrà essere convalidato rispetto all'host ESXi per ottenere le informazioni che ci interessano, quindi creeremo un utente in ogni ESXi e daremo le autorizzazioni necessarie.

In ogni ESXi, dopo aver effettuato l'accesso con il client tradizionale o il browser web, Andremo nella zona di “Gli utenti” E ne creeremo uno, Imposteremo anche la tua password.
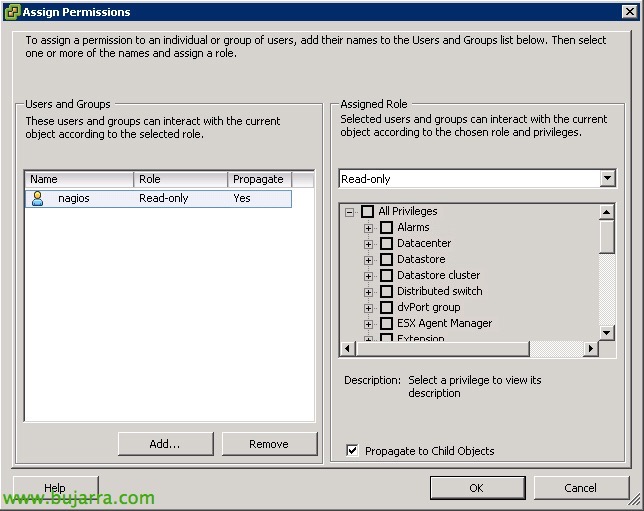
Sul “Autorizzazioni”, Aggiungeremo questo utente al maggior numero possibile di ambiti, e lo aggiungeremo con il ruolo 'Sola lettura'.
Ora, Creeremo nella directory che ci interessa (Lo lascio negli stessi plugin) un file, dove memorizzeremo il nome utente e la password che il comando utilizzerà per convalidarsi quando eseguirà i controlli. In questo esempio lo salvo in '/usr/lib/centreon/plugins/check_vmware_api.auth’ con il seguente formato:
[Codice sorgente]username=utente
password=Password[/Codice sorgente]

E possiamo già eseguire qualsiasi controllo su un host ESXi, Qualcosa di semplice da provare, Utilizzo della CPU:
[Codice sorgente]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l cpu -s utilizzo -w 80 -c 90[/Codice sorgente]
I parametri che accompagnano il comando sono tutti descritti di seguito, nel comando precedente '-w’ sarà il % Avviso quando Avviso e '-c’ il valore di quando è Critico. Te lo dico perché è comune in quasi tutti i comandi, e tutti coloro che usano quelli che vogliamo, In questi documenti troverete che normalmente quando si raggiunge il 80% sarà qualcosa di Avvertimento e quando raggiunge il 90% sarà Critico.
Ora non resta che scegliere gli elementi che più ci interessano monitorare, Alla fine del documento metterò tutte le possibilità che questo eccellente comando 'check_vmware_api.pl' ci dà. Ma per ora ti do gli esempi più comuni per monitorare le informazioni da un host ESXi:
Utilizzo della RAM:
[Codice sorgente]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l mem -s utilizzo -w 80 -c 90[/Codice sorgente]
Utilizzo della memoria di swap
[Codice sorgente]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l mem -s swap -w 1 -c 10[/Codice sorgente]
Utilizzo della memoria balloning
[Codice sorgente]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l mem -s memctl -w 1 -c 10[/Codice sorgente]
Utilizzo della rete
[Codice sorgente]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l net -s utilizzo -w 10240 -c 102400[/Codice sorgente]
Rilevare se è presente una scheda di interfaccia di rete caduta,
[Codice sorgente]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l net -s nic -w 1 -c 2[/Codice sorgente]
Monitoraggio dei datastore VMFS, in questo, Il comando restituisce l'uso gratuito, quindi indicheremo con il seguente formato in Avviso e Critico il % di sdoganamento,
[Codice sorgente]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l vmfs -s -s LUN04 -w 10%: -c 5%:[/Codice sorgente]
Ad esempio con il parametro 'runtime'’ Esamineremo una panoramica del server, e opzionalmente possiamo aggiungere altre opzioni come 'salute’ per vedere la salute, «Temperatura’ per visualizzare i sensori di temperatura, o 'stato’ per vedere un riassunto tra gli altri.
[Codice sorgente]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime -s salute
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime -s temperatura
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime -s stato[/Codice sorgente]
Se usiamo il parametro 'service’ saremo in grado di vedere lo stato di tutti i servizi ESXi se sono in esecuzione o meno, e inoltre possiamo aggiungere il nome dei servizi che siamo interessati a monitorare solo.
[Codice sorgente]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l servizio
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l service -s DCUI vpxa[/Codice sorgente]
Per ora, penso che questo ci basti, No? Dal momento che la sceneggiatura 'check_vmware_api.pl’ Ha ancora molte altre cose che puoi sfogliare e vedremo in altri post, sarebbe utile anche monitorare i cluster Host, Centri dati, Macchine virtuali, and so on… Un altro giorno ;), Ora continuiamo con i padroni di casa!
Creazione di un host,
Qui finalmente registreremo a Nagios il nostro primo server, un host ESXi! Useremo Centreon per rendere tutto il lavoro più facile.
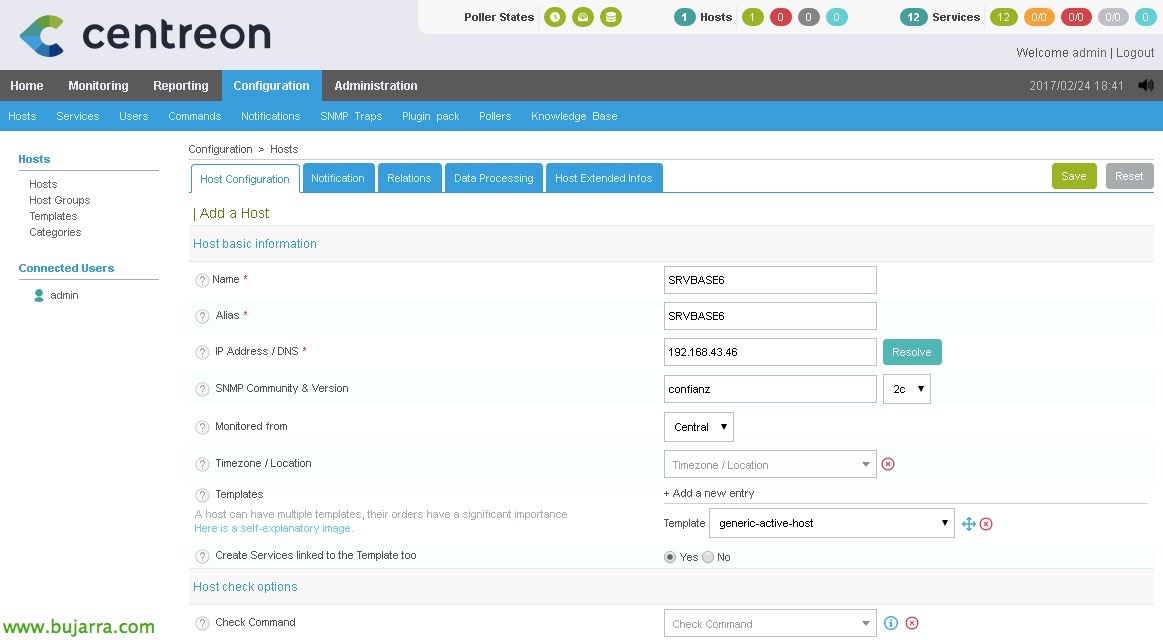
Poiché “Configurazione” > “Ospita” > “Aggiungere”, Aggiungeremo il nostro primo server, Completeremo almeno i seguenti campi:
- Nome: Nome server.
- Alias: Alias server.
- Indirizzo IP / DNS: L'indirizzo IP o il nome DNS del server.
- Comunità SNMP & Versione: In questo caso non sarebbe necessario.
- Monitorato da: Il poller che monitorerà questo host.
- Sagoma: Seleziona 'generic-active-host'.
Creazione di un comando,
Definiremo un comando in Centreon utilizzando le variabili per poter eseguire i comandi che abbiamo visto prima, questo comando verrà poi chiamato da ogni servizio che creiamo per monitorare la CPU, ARIETE… Quale modo migliore per vederlo se non capirlo 🙂
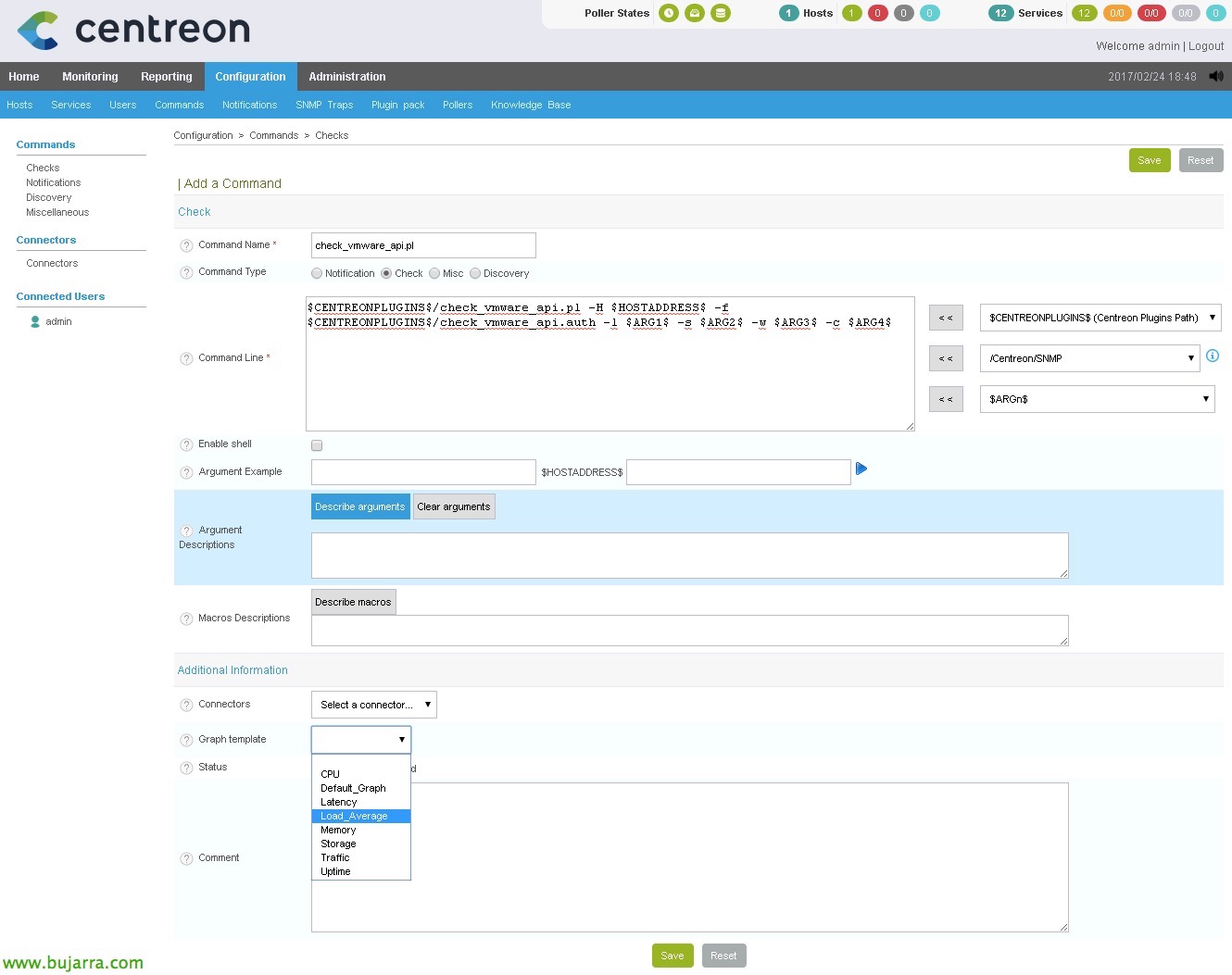
Di solito mi piace chiamare il comando allo stesso modo dello script, pertanto, In questo caso creerò il comando 'check_vmware_api.pl'. Per fare ciò,, poiché “Configurazione” > “Comandi” > “Controlli” > “Aggiungere”. Indichiamo che si tratta di un comando di tipo 'Check’ e nella sezione 'Riga di comando che indichiamo':
[Codice sorgente]$CENTREONPLUGINS$/check_vmware_api.pl -H $HOSTADDRESS$ -f $CENTREONPLUGINS$/check_vmware_api.auth -l $ARG 1$ -s $ARG 2$ -w $ARG 3$ -c $ARG 4$[/Codice sorgente]
- La variabile $CENTREONPLUGINS$ è '/usr/lib/centreon/plugins/’
- La variabile $HOSTADDRESS$ sarebbe l'indirizzo IP o il nome FQDN del server da monitorare.
- ARG1 sarebbe il primo argomento che vi trasmetteremo, se ricordiamo è l' Ordine’ indicato dopo '-l'.
- ARG2 sarebbe il primo argomento che gli passeremo,se ricordiamo è il 'SubCommand’ indicato dopo '-s'.
- ARG3 sarà il valore di Avviso.
- ARG4 sarà il valore di Critical.
Clicca su “Descrivi gli argomenti” quindi non devo memorizzare e sapere questo.
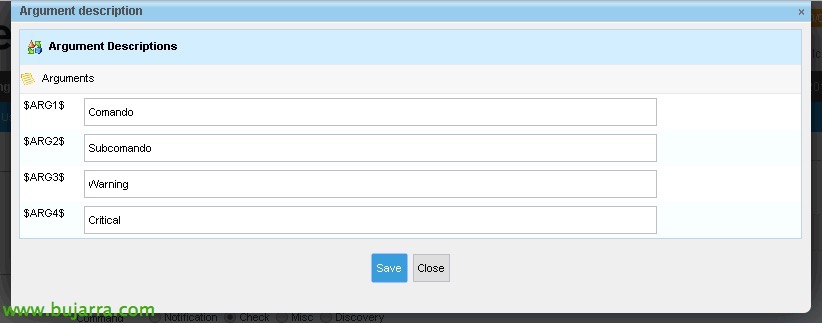
Quindi associamo in modo semplice cos'è ogni argomento, che in seguito, quando creiamo i servizi, Lo apprezzeremo. “Salvare”.
Creazione dei servizi,
Qui possiamo finalmente creare i servizi di ciò che vogliamo monitorare, essere CPU, ARIETE, Schede di rete eliminate, Stato del datastore… per questo, Ci sosterremo a vicenda come abbiamo detto nel comando che abbiamo appena creato! Guarda com'è facile:
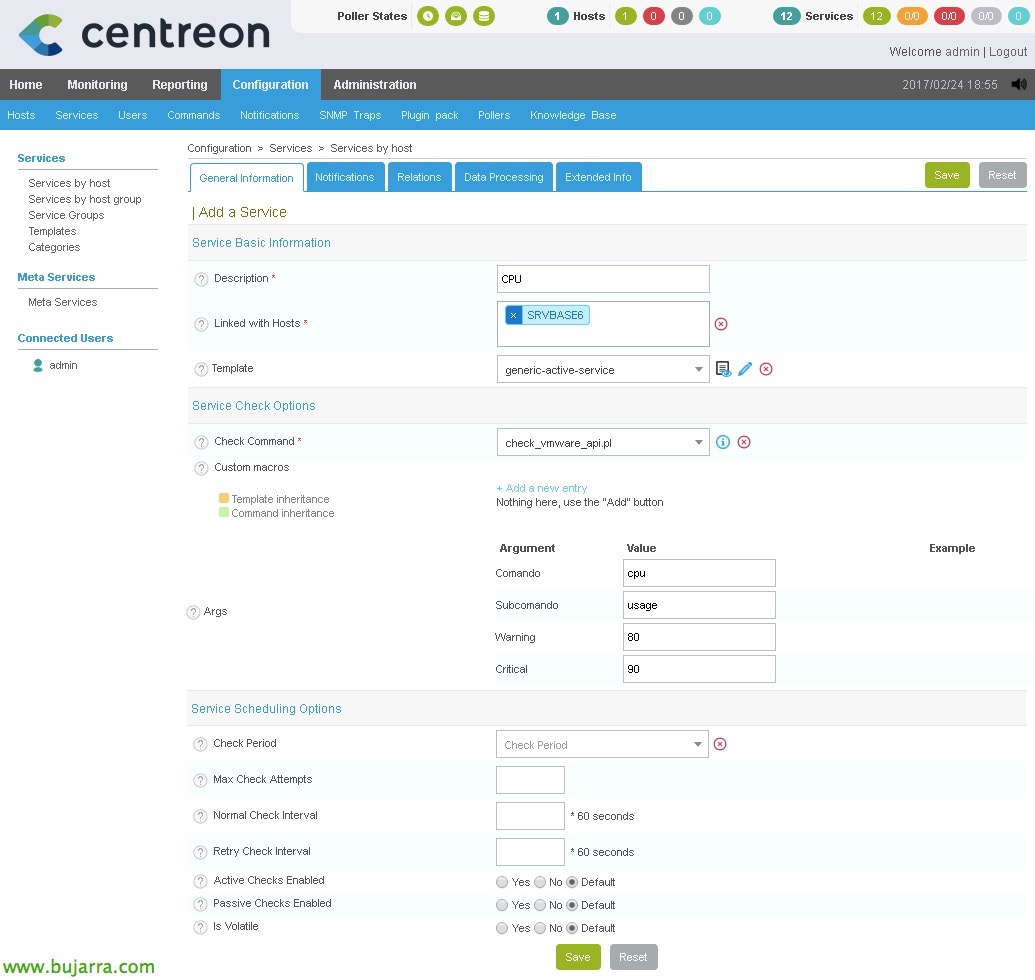
In “Configurazione” > “Servizi” > “Aggiungere”, Creeremo il nostro primo servizio! Inseriremo almeno le seguenti informazioni:
- Descrizione: Nome servizio, nel mio caso CPU, ARIETE, Scambia memoria…
- Collegato con gli host: Qui aggiungeremo l'host che abbiamo creato in precedenza, il nostro server ESXi.
- Sagoma: Seleziona 'generic-active-service'.
- Comando di controllo: Scegliamo anche il comando che abbiamo creato in precedenza, che nel mio caso lo chiamo lo script 'check_vmware_api.pl’
- Argomenti: Dobbiamo riempire tutti gli argomenti che il comando ci chiede di fare.
- Utilizzo della CPU: CPU / uso / 80 / 90
- ARIETE: mem / uso / 80 / 90
- Scambia memoria: mem / barattare / 1 / 10
- Memoria balloning: mem / Memctl / 1/ 10
- Stato NIC: Rete / Nic / 1 / 2
- …
Registriamo con “Salvare”,

Per creare il resto dei servizi, invece di crearli tutti da zero, La cosa più comoda sarà duplicarli, In questo modo dovremo solo modificare gli argomenti e sarà molto più facile creare i servizi.
Una volta creati tutti i servizi associati a un host ESXi, se ora vogliamo duplicare il lavoro svolto per monitorare un altro host ESXi che abbiamo, O quanti ne abbiamo, poiché “Configurazione” > “Ospita”, selezioneremo l'ESXi che abbiamo e lo duplicheremo, Con ciò generiamo un nuovo host, a cui dovremo cambiare il Nome, Alias e indirizzo IP e avremo un altro host pronto con gli stessi servizi!
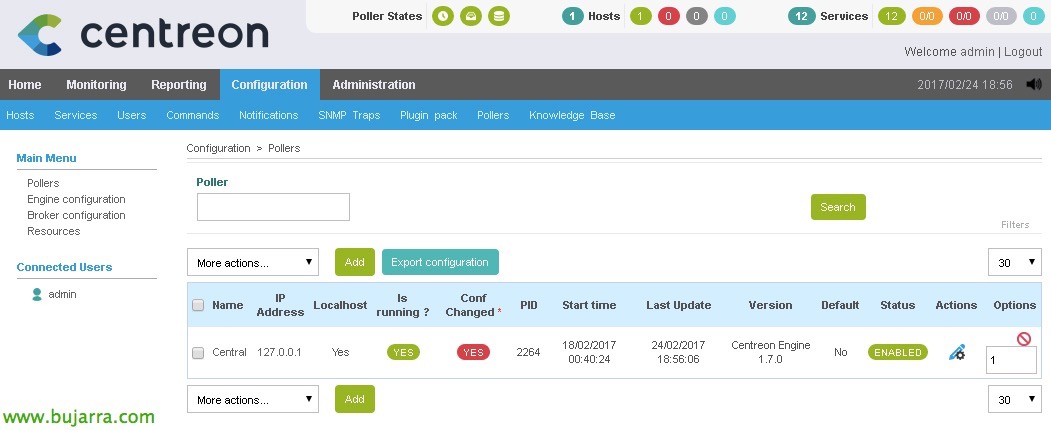
E niente, Il solito, Una volta terminato il lavoro, Salviamo le modifiche, Cenreon genererà i file nagios necessari, “Configurazione” > “Sondaggisti” > “Esportare la configurazione”,

Selezioniamo il nostro poller, Segniamo i controlli e ripartiamo & “Esportazione”,
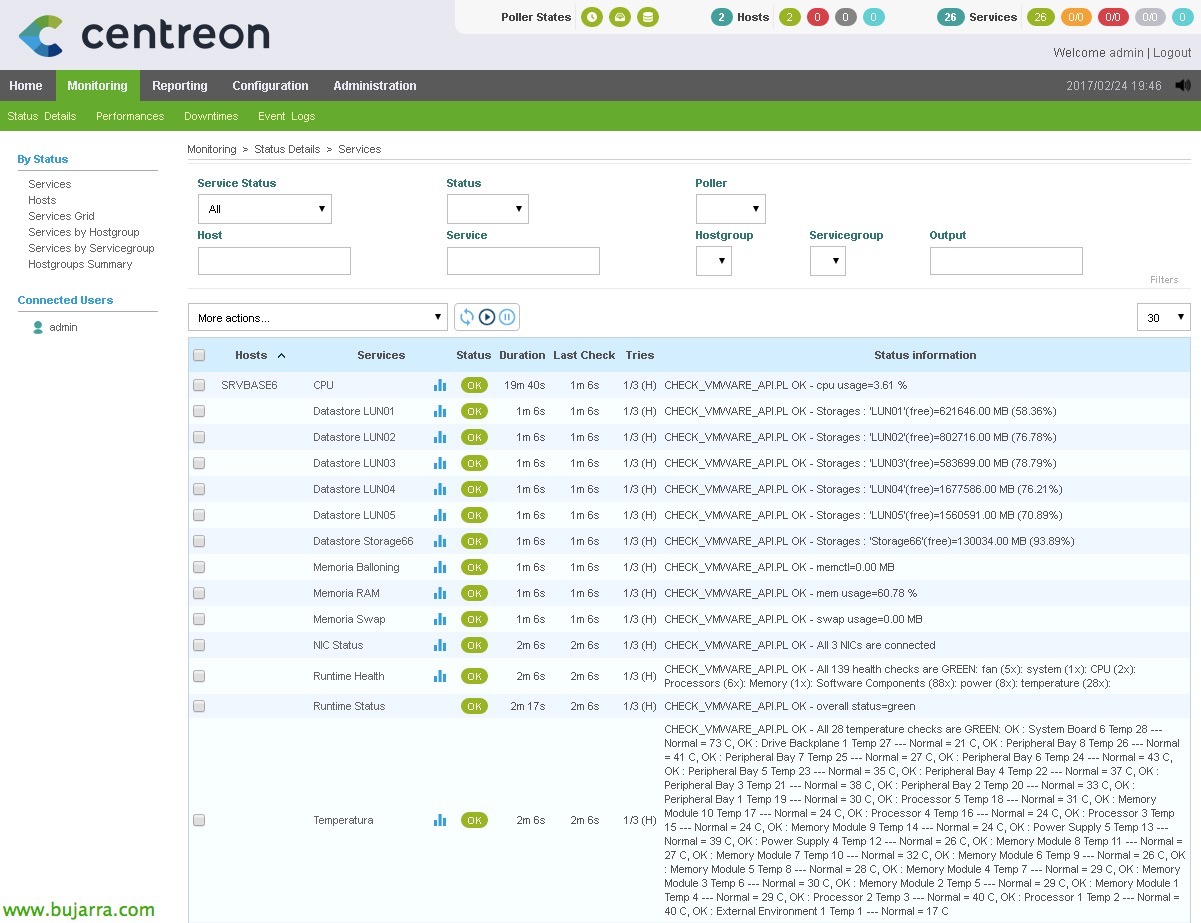
Una volta che tutto è stato generato, Ora possiamo andare alla parte di monitoraggio e verificare che tutto ciò che abbiamo fatto funzioni! Esamineremo tutti i nuovi servizi che abbiamo creato che monitorano cose diverse. Se vogliamo forzare il controllo, Lo sappiamo già, selezioniamo i servizi che ci interessano e nella combo selezioniamo 'Servizi – Pianifica il controllo immediato (Forzato)’.
E qui vi lascio tutte le possibilità del comando:
[Codice sorgente]Uso: check_vmware_api.pl -D <data_center> | -H <host_name> [ -C <cluster_name> ] [ -N <vm_name> ]
-u <utente> -p <Passare> | -f <authfile>
-l <comando> [ -s <Sottocomando> ] [ -T <Spostamento temporale> ] [ -io <intervallo> ]
[ -x <black_list> ] [ -o <additional_options> ]
[ -t <Timeout> ] [ -w <warn_range> ] [ -c <crit_range> ]
[ -V ] [ -h ]
-?, –uso
Stampa le informazioni sull'utilizzo
-h, –Guida
Stampa la schermata di aiuto dettagliata
-V, –Versione
Informazioni sulla versione di stampa
–extra-opts=[sezione][@file]
Leggere le opzioni da un file ini.
per l'uso e gli esempi.
-H, –ospite=<nome host>
Nome host ESX o ESXi.
-C, –cluster=<nome cluster>
Nome cluster ESX o ESXi.
-D, –datacenter=<DCname>
Nome host del data center.
-N, –nome=<vmname>
Nome macchina virtuale.
-u, –nome utente=<nome utente>
Nome utente con cui connettersi.
-p, –password=<parola d’ordine>
Password da utilizzare con il nome utente.
-f, –authfile=<Sentiero>
File di autenticazione con login e password. Sintassi dei file :
nome utente=<accesso>
password=<parola d’ordine>
-w, –warning=SOGLIA
Soglia di avviso. Vedere
per il formato di soglia. Per impostazione predefinita, Non è impostata alcuna soglia.
-c, –critico=SOGLIA
Soglia critica. Vedere
per il formato di soglia. Per impostazione predefinita, Non è impostata alcuna soglia.
-l, –command=COMANDO
Specificare il tipo di comando (CPU, MEM, RETE, IO, VMFS, RUNTIME, …)
-s, –subcommand=SOTTOCOMANDO
Specificare il sottocomando
-S, –sessionfile=SESSIONFILE
Specificare un nome file per memorizzare le sessioni per un'autenticazione più rapida
-x, –escludere=<black_list>
Specificare la lista nera
-o, –opzioni=<additional_options>
Specificare opzioni di comando aggiuntive (Statistiche rapide, …)
-T, –timestamp=<Spostamento temporale>
Timeshift in seconds that could fix issues with "Unknown error". Usa valori come 5, 10, 20, and so on
-io, –intervallo=<periodo di campionamento>
Periodo di campionamento in secondi. Intervalli storici di base: 300, 1800, 7200 o 86400. Vedere config per eventuali modifiche.
Supporta i valori letterali per negoziare automaticamente il valore dell'intervallo: r – Intervallo in tempo reale, h<numero> – intervallo storico specificato per posizione.
Il valore predefinito è 20 (in tempo reale). Poiché il cluster non dispone di intervalli di statistiche in tempo reale diversi da 20(Predefinito in tempo reale) è obbligatorio.
-M, –maxsamples=<Numero massimo di campioni>
Numero massimo di campioni da recuperare. Il numero massimo di campioni viene ignorato per gli intervalli cronologici.
Il valore predefinito è 1 (Ultimo campione disponibile).
–traccia=<livello>
Impostazione del livello di dettaglio della traccia di richiesta/risposta dell'API vSphere
–generate_test=<file>
Generare uno script del caso di test dal comando/sottocomando eseguito e scriverlo in <file>. Se <file> is "stdout", Lo script del test case viene invece scritto in stdout.
-t, –timeout=INTERO
Secondi prima del timeout del plug-in (default: 30)
-v, –prolisso
Mostra dettagli per il debug della riga di comando (può ripetersi fino a 3 tempi)
Comandi supportati(^ – parametro vuoto o non specificato, o – Opzioni, T – valore di spostamento temporale, b – Libro nero) :
Specifico della VM :
* CPU – Mostra le informazioni sulla CPU
+ uso – Utilizzo della CPU in percentuale
+ UtilizzoMHZ – Utilizzo della CPU in MHz
+ aspettare – Tempo di attesa della CPU in ms
+ pronto – Tempo di preparazione della CPU in ms
^ Tutte le informazioni sulla CPU(Nessuna soglia)
* mem – Mostra le informazioni MEM
+ uso – Utilizzo MEM in percentuale
+ UtilizzoMB – Utilizzo di mem in MB
+ barattare – scambiare l'utilizzo di mem in MB
+ Swapin – swapin utilizzo di mem in MB
+ sostituzione – swapout utilizzo mem in MB
+ in cielo – memoria aggiuntiva utilizzata dal server VM in MB
+ grembiule – mem complessivo utilizzato dal server VM in MB
+ attivo – utilizzo attivo di mem in MB
+ Memctl – mem utilizzato dal driver di controllo della memoria della macchina virtuale(vmmemctl) che controlla il ballooning
^ Tutte le informazioni mem(tranne che in generale e senza soglie)
* Rete – Mostra informazioni sulla rete
+ uso – utilizzo complessivo della rete in KBps(Kilobyte al secondo)
+ ricevere – ricevere in KBps(Kilobyte al secondo)
+ Invia – invia in KBps(Kilobyte al secondo)
^ Tutte le informazioni sulla rete(ad eccezione dell'utilizzo e dell'assenza di soglie)
* Io – mostra le informazioni sull'I/O del disco
+ uso – utilizzo complessivo del disco in MB/s
+ leggere – leggere l'utilizzo del disco in MB/s
+ scrivere – utilizzo del disco di scrittura in MB/s
^ Tutte le informazioni su Disk IO(Nessuna soglia)
* Runtime – Mostra le informazioni sul runtime
+ con – Stato della connessione
+ CPU – CPU allocata in MHz
+ mem – mem allocato in MB
+ stato – Stato della macchina virtuale (SU, GIÙ, SOSPESO)
+ stato – Stato generale dell'oggetto (grigio/verde/rosso/giallo)
+ ConsoleConnessioni – connessioni console alla VM
+ Ospite – stato del sistema operativo guest, ha bisogno di VMware Tools
+ utensileria – Stato di VMware Tools
+ problemi – Tutti i problemi per l'host
^ Tutte le informazioni sul runtime(tranne con e nessuna soglia)
Specifico per l'host :
* CPU – Mostra le informazioni sulla CPU
+ uso – Utilizzo della CPU in percentuale
o Statistiche rapide – opzione per la query dei valori PerfCounter o delle informazioni di runtime
+ UtilizzoMHZ – Utilizzo della CPU in MHz
o Statistiche rapide – opzione per la query dei valori PerfCounter o delle informazioni di runtime
^ Tutte le informazioni sulla CPU
o Statistiche rapide – opzione per la query dei valori PerfCounter o delle informazioni di runtime
* mem – Mostra le informazioni MEM
+ uso – Utilizzo MEM in percentuale
o Statistiche rapide – opzione per la query dei valori PerfCounter o delle informazioni di runtime
+ UtilizzoMB – Utilizzo di mem in MB
o Statistiche rapide – opzione per la query dei valori PerfCounter o delle informazioni di runtime
+ barattare – scambiare l'utilizzo di mem in MB
o listvm – attiva/disattiva l'elenco di output delle VM di scambio
+ in cielo – memoria aggiuntiva utilizzata dal server VM in MB
+ grembiule – mem complessivo utilizzato dal server VM in MB
+ Memctl – mem utilizzato dal driver di controllo della memoria della macchina virtuale(vmmemctl) che controlla il ballooning
o listvm – attiva/disattiva l'elenco di output delle VM in mongolfiera
^ Tutte le informazioni mem(tranne che in generale e senza soglie)
* Rete – Mostra informazioni sulla rete
+ uso – utilizzo complessivo della rete in KBps(Kilobyte al secondo)
+ ricevere – ricevere in KBps(Kilobyte al secondo)
+ Invia – invia in KBps(Kilobyte al secondo)
+ Nic – verifica che tutte le schede di interfaccia di rete attive siano collegate
^ Tutte le informazioni sulla rete(ad eccezione dell'utilizzo e dell'assenza di soglie)
* Io – Mostra le informazioni sull'I/O del disco
+ Interrotta – conteggio dei comandi interrotti
+ Reimposta – Il bus azzera il conteggio
+ leggere – Latenza di lettura in ms (totalReadLatency.average)
+ scrivere – Latenza di scrittura in MS (totalWriteLatency.average)
+ chicco – Latenza del kernel in MS
+ dispositivo – Latenza del dispositivo in ms
+ coda – Latenza della coda in MS
^ Tutte le informazioni su Disk IO
* VMFS – mostra le informazioni del datastore
+ (Nome) – informazioni sullo spazio libero per il datastore con nome (Nome)
o usato – output spazio utilizzato invece di libero
o breve – Elenca solo i volumi di avviso
o regexp – Se considerare il nome come regexp
o blacklistregexp – Se considerare la blacklist come regexp
b – inserire nella lista nera i VMFS
T (valore) – Timeshift per determinare se abbiamo bisogno di aggiornare
^ Tutte le informazioni sul datastore
o usato – output spazio utilizzato invece di libero
o breve – Elenca solo i volumi di avviso
o blacklistregexp – Se considerare la blacklist come regexp
b – inserire nella lista nera i VMFS
T (valore) – Timeshift per determinare se abbiamo bisogno di aggiornare
* Runtime – Mostra le informazioni sul runtime
+ con – Stato della connessione
+ Salute – Controlla lo stato di CPU/storage/memoria/sensore e propaga lo stato peggiore
o elementi di elenco – Elenca tutti i sensori disponibili(Utilizzare solo a scopo di inserzione)
o blackregexpflag – Se considerare la blacklist come regexp
b – Oggetti di stato della blacklist
+ Salute di stoccaggio – Controllo dello stato di stoccaggio
o blackregexpflag – Se considerare la blacklist come regexp
b – Oggetti di stato della blacklist
+ temperatura – sensori di temperatura
o blackregexpflag – Se considerare la blacklist come regexp
b – Oggetti di stato della blacklist
+ sensore – sensore specificato per la soglia
+ manutenzione – Indica se l'host è in modalità di manutenzione
o maintwarn – Imposta lo stato di avviso quando l'host è in modalità di manutenzione
o maintcrit – Imposta lo stato critico quando l'host è in modalità di manutenzione
+ lista(Vm) – elenco delle macchine VMware e relativi stati
+ stato – Stato generale dell'oggetto (grigio/verde/rosso/giallo)
+ problemi – Tutti i problemi per l'host
b – Problemi con la lista nera
^ Tutte le informazioni sul runtime(Salute, Salute di stoccaggio, La temperatura e il sensore sono rappresentati come un unico valore e senza soglie)
* servizio – mostra le informazioni sul servizio host
+ (Nomi) – verificare lo stato di uno o più servizi specificati da (Nomi), sintassi per (Nomi):<servizio1>,<servizio2>,…,<servizioN>
^ mostra tutti i servizi
* immagazzinamento – mostra le informazioni di archiviazione dell'host
+ adattatore – Schede bus elenco
b – adattatori blacklist
+ lun – elencare le unità logiche SCSI
b – inserire nella lista nera i LUN
+ Sentiero – Elencare i percorsi delle unità logiche
b – Percorsi della blacklist
^ Mostra tutte le informazioni di archiviazione
* Uptime – mostra il tempo di attività dell'host
o Statistiche rapide – opzione per la query dei valori PerfCounter o delle informazioni di runtime
* dispositivo – mostra le informazioni specifiche del dispositivo host
+ CD/DVD – Elenca le macchine virtuali con unità CD/DVD collegate
o listall – Elenca tutti i dispositivi disponibili(Utilizzare solo a scopo di inserzione)
Specifico per DC :
* CPU – Mostra le informazioni sulla CPU
+ uso – Utilizzo della CPU in percentuale
o Statistiche rapide – opzione per la query dei valori PerfCounter o delle informazioni di runtime
+ UtilizzoMHZ – Utilizzo della CPU in MHz
o Statistiche rapide – opzione per la query dei valori PerfCounter o delle informazioni di runtime
^ Tutte le informazioni sulla CPU
o Statistiche rapide – opzione per la query dei valori PerfCounter o delle informazioni di runtime
* mem – Mostra le informazioni MEM
+ uso – Utilizzo MEM in percentuale
o Statistiche rapide – opzione per la query dei valori PerfCounter o delle informazioni di runtime
+ UtilizzoMB – Utilizzo di mem in MB
o Statistiche rapide – opzione per la query dei valori PerfCounter o delle informazioni di runtime
+ barattare – scambiare l'utilizzo di mem in MB
+ in cielo – memoria aggiuntiva utilizzata dal server VM in MB
+ grembiule – mem complessivo utilizzato dal server VM in MB
+ Memctl – mem utilizzato dal driver di controllo della memoria della macchina virtuale(vmmemctl) che controlla il ballooning
^ Tutte le informazioni mem(tranne che in generale e senza soglie)
* Rete – Mostra informazioni sulla rete
+ uso – utilizzo complessivo della rete in KBps(Kilobyte al secondo)
+ ricevere – ricevere in KBps(Kilobyte al secondo)
+ Invia – invia in KBps(Kilobyte al secondo)
^ Tutte le informazioni sulla rete(ad eccezione dell'utilizzo e dell'assenza di soglie)
* Io – Mostra le informazioni sull'I/O del disco
+ Interrotta – conteggio dei comandi interrotti
+ Reimposta – Il bus azzera il conteggio
+ leggere – Latenza di lettura in ms (totalReadLatency.average)
+ scrivere – Latenza di scrittura in MS (totalWriteLatency.average)
+ chicco – Latenza del kernel in MS
+ dispositivo – Latenza del dispositivo in ms
+ coda – Latenza della coda in MS
^ Tutte le informazioni su Disk IO
* VMFS – mostra le informazioni del datastore
+ (Nome) – informazioni sullo spazio libero per il datastore con nome (Nome)
o usato – output spazio utilizzato invece di libero
o breve – Elenca solo i volumi di avviso
o regexp – Se considerare il nome come regexp
o blacklistregexp – Se considerare la blacklist come regexp
b – inserire nella lista nera i VMFS
T (valore) – Timeshift per determinare se abbiamo bisogno di aggiornare
^ Tutte le informazioni sul datastore
o usato – output spazio utilizzato invece di libero
o breve – Elenca solo i volumi di avviso
o blacklistregexp – Se considerare la blacklist come regexp
b – inserire nella lista nera i VMFS
T (valore) – Timeshift per determinare se abbiamo bisogno di aggiornare
* Runtime – Mostra le informazioni sul runtime
+ lista(Vm) – elenco delle macchine VMware e relativi stati
+ Lista Ospite – elenco dei server host VMware esx e relativi stati
+ elencocluster – elenco dei cluster VMware e relativi stati
+ utensileria – Stato di VMware Tools
b – blacklist delle VM
+ stato – Stato generale dell'oggetto (grigio/verde/rosso/giallo)
+ problemi – Tutti i problemi per l'host
b – Problemi con la lista nera
^ Tutte le informazioni sul runtime(ad eccezione del cluster e degli strumenti e dell'assenza di soglie)
* Consigli – Mostra le raccomandazioni per il cluster
+ (Nome) – Raccomandazioni per il cluster con nome (Nome)
^ Tutte le raccomandazioni dei cluster
Specifico del cluster :
* CPU – Mostra le informazioni sulla CPU
+ uso – Utilizzo della CPU in percentuale
+ UtilizzoMHZ – Utilizzo della CPU in MHz
^ Tutte le informazioni sulla CPU
* mem – Mostra le informazioni MEM
+ uso – Utilizzo MEM in percentuale
+ UtilizzoMB – Utilizzo di mem in MB
+ barattare – scambiare l'utilizzo di mem in MB
o listvm – attiva/disattiva l'elenco di output delle VM di scambio
+ Memctl – mem utilizzato dal driver di controllo della memoria della macchina virtuale(vmmemctl) che controlla il ballooning
o listvm – attiva/disattiva l'elenco di output delle VM in mongolfiera
^ Tutte le informazioni mem(più sovraccarico e nessuna soglia)
* Grappolo – Mostra le informazioni sui servizi cluster
+ efficaceCPU – Totale delle risorse CPU disponibili di tutti gli host all'interno del cluster
+ Efficace MEM – Quantità totale di memoria del computer di tutti gli host nel cluster
+ Failover – Numero di errori che possono essere tollerati in VMware HA
+ Correttezza – Equità dell'allocazione delle risorse della CPU distribuita
+ Conformità – Equità dell'allocazione distribuita delle risorse MEM
^ Solo valori EffectiveCPU e EffectiveMem per i servizi cluster
* Runtime – Mostra le informazioni sul runtime
+ lista(Vm) – elenco delle macchine VMware nel cluster e relativi stati
+ Lista Ospite – elenco dei server host VMware esx nel cluster e relativi stati
+ stato – Stato generale del cluster (grigio/verde/rosso/giallo)
+ problemi – Tutti i problemi per il cluster
b – Problemi con la lista nera
^ Tutte le informazioni sul runtime del cluster
* VMFS – mostra le informazioni del datastore
+ (Nome) – informazioni sullo spazio libero per il datastore con nome (Nome)
o usato – output spazio utilizzato invece di libero
o breve – Elenca solo i volumi di avviso
o regexp – Se considerare il nome come regexp
o blacklistregexp – Se considerare la blacklist come regexp
b – inserire nella lista nera i VMFS
T (valore) – Timeshift per determinare se abbiamo bisogno di aggiornare
^ Tutte le informazioni sul datastore
o usato – output spazio utilizzato invece di libero
o breve – Elenca solo i volumi di avviso
o blacklistregexp – Se considerare la blacklist come regexp
b – inserire nella lista nera i VMFS
T (valore) – Timeshift per determinare se abbiamo bisogno di aggiornare[/Codice sorgente]