

オラマ, ローカル AI の使用を開始する

数ヶ月間、私はローカルのオープンソースのAIをいじくり回していました; そして、私はあなたの日常におけるその可能性のいくつかを一連の投稿で少し共有したかったのです. しかし、この最初のドキュメントでは、それをどのように設定できるか、そしてその可能性についてのいくつかの基本的な概念を見ていきます.
はじめに, もしよろしければ、アイデアとして役立つ場合に備えて、今日何に使っているかをお伝えします; 今のところ, テキストを生成するためだけに, 彼は貧しいかもしれません, しかし、それは非常に広い世界です. 通知やアラートシステムの受信から, アラートはあなたをより人間らしくしたり、解決をどこから始めるべきかを提案したりできます. 定期的にメールを送信するため, 私の組織から毎日送信されるメール, マンスリー… まあ、それは彼らに別のタッチを与えます, それは彼らに特定のデータを与え、彼らを非常に現実的なものにします. ホームオートメーションシステムにも, ホームと会話をすることができます, それは私に警告します, 音声を使う, さまざまなフレーズ…
今のところ, 私が言ったように, テキストを生成するには; しかし、可能性はたくさんあります, データベースへの接続など、自然言語でクエリを実行することができます. または、AIに送信したドキュメントに関する会話や質問に参加する可能性, またはイメージであり、彼が見たものを説明すること… このドキュメント全体を通して、何か楽しいことをできるように、いくつかの簡単な例を挙げます.

2 番目の, 悪くありません, これは何と呼ばれていますか… ご想像の通り、多くの選択肢と可能性があります, 私はあなたに話すつもりです オラマ (AIモデルとアプリケーションのためのオープンソースライブラリ). Ollama は LLM の使用を許可します (大規模言語モデル), これは, AI 用にトレーニングされた言語モデル, オープンソースでも有料でもかまいません, たぶん 100% オフラインかどうか, 味わう. 明らかに、使用するLLMに応じて、多かれ少なかれ電力が必要になります, これは, 応答が即時に行われるようにGPUを搭載する. Ollama APIを使用して、他のシステムとリモートで質問できるようになります, 非常に強力. そして、私はあなたをお勧めします WebUIを開く Ollama の GUI インターフェースとして, したがって、私たちのブラウザを使用すると、AIを快適に操作できると期待するインターフェイスが得られます.
私が言ったこと, 可能な限り最高のパフォーマンスを発揮するには、GPUが必要になります, 使用するLLMと各モデルに必要なGBによって異なります, このようにして、応答は即座に行われます. 互換性のあるハードウェアに関しては、それはかなり広範囲です (エヌビディア, AMDの, アップルM1…), 君を置いていくよ これがそのリストです.
記事を次のように分けます:
- WindowsでのOllamaとOpenWebUIのクイックインストール, MacまたはLinux
- Ollama と Open WebUI を Proxmox の Linux MV に Docker でインストールする
- Open Web UIからのアクセスと開始
- 画像認識
- ドキュメントの操作
- 諸
WindowsでのOllamaとOpenWebUIのクイックインストール, MacまたはLinux
それを証明したいなら, そして今、速い, これはオプションです, LinuxにOllama をインストールできるようになるからです, MacまたはWindows, por si la quieres correr en local, con tu GPU. イレモス・ア・ラ web de descargas de Ollama, seleccionaremos nuestro SO y nos lo descargamos, 次に, 次へ e Instalado.
En Linux nos lo bajaremos e instalaremos de la siguiente manera:
curl -fsSL https://ollama.com/install.sh | sh >>> ollamaをダウンロードしています。. ######################################################################## 100,0%##O#-# >>> ollama を /usr/local/bin にインストールします。. >>> ollama ユーザーを作成しています。. >>> レンダリンググループにollamaユーザーを追加しています。. >>> ollama ユーザーをビデオ グループに追加しています。. >>> 現在のユーザーをollamaグループに追加しています。. >>> ollama systemdサービスの作成... >>> ollama サービスの有効化と開始... シンボリックリンク /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service を作成しました。. >>> NVIDIA GPU搭載.
Y podremos directamente si queremos desde shell bajarnos un LLM y probarlo:
オラマランミストラル引っ張るマニフェストE8A35B5937A5... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 4.1 GB引っ張り43070e2d4e53... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 11 KB引っ張りe6836092461f。. 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 42 B引っ張りed11eda7790d.。. 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 30 B引っ張りf9b1e3196ecf.。. 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 483 B sha256 ダイジェスト書き込みマニフェストの検証 未使用のレイヤーの削除成功 >>> こんにちは、こんにちは! ということは "こんにちは" スペイン語で.
APIクエリに応答するようにするには、サービスファイル「nano / etc / systemd / system / ollama.service」を編集する必要があります ‘ 追加:
環境="OLLAMA_HOST=0.0.0.0:11434"
そして、私たちはサービスを充電します:
sudo systemctl daemon-reload sudo systemctl restart ollama
また、ブラウザからAIを管理するためのGUIが必要な場合は、OpenWebUIを設定する必要があります, Dockerコンテナで最も速く、最も便利:
git clone https://github.com/open-webui/open-webui.git CD open-webui/ sudo Docker compose up -d

また、ポート3000tcpでマシンのIPを攻撃することでブラウザを開くことができます (デフォルト).
Ollama と Open WebUI を Proxmox の Linux MV に Docker でインストールする
そして、この部分ではその理由をお伝えします… 私の考えは、中央集権的なAIのためのマシンを持つことです, 異なるシステムが異なるクエリを実行するために指すことができるマシン, こちらは, 仮想マシンである必要があります (利点について語る, 高可用性, バックアップ, スナップショット…), グラフィックカードをパススルーし、GPUを搭載したVMです. これには、Proxmoxを使用します, (ある日、私たちはヴイエムウェアの自殺について話しました) VMはUbuntuサーバーになります 24.04. そして、私たちがそれを行っている間、, そのVMでは、DockerコンテナでOllamaとOpenWebUIを実行します.
Proxmoxでグラフィックカードをパススルーするために私が従った手順は次のとおりです, 彼らが最も正しいかどうかはわかりません, しかし、それは完璧に機能します.
Proxmoxのインストール後 8.2, 最小限の構成, Proxmox VEヘルパースクリプトのProxmox VEポストインストールを実行しました, ProxmoxにそのPCIeグラフィックスを使用しないように指示します, 私たちは 'nano /etc/default/grub で GRUB の編集を始めました’ そして、次の行を変更します:
#GRUB_CMDLINE_LINUX_DEFAULT="静か" GRUB_CMDLINE_LINUX_DEFAULT="静かな intel_iommu=オン iommu=pt vfio_iommu_type1 initcall_blacklist=sysfb_init" インテル--> GRUB_CMDLINE_LINUX_DEFAULT="quiet intel_iommu=オン" AMDの> GRUB_CMDLINE_LINUX_DEFAULT="quiet amd_iommu=オン"
そして、私たちは実行します
更新-grub
'nano /etc/modules' で以下のモジュールを追加しました。:
私はvfio_iommu_type1 vfio_pci vfio_virqfd住んでいます
「nano /etc/modprobe.d/blacklist.conf」でドライバーをロックします:
ブラックリスト、Nouveau、ブラックリスト、NVIDIAブラックリスト、NVIDIA*、Radeon
IDは次のように書き留めます: 'spci -n -s 01:00’, ご覧の通り, 気になる人がいたら, 私の場合はNVIDIA RTXです 3060 12PCIe に接続された GB 1.
01:00.0 0300: 10の:2504 (リビジョンA1) 01:00.1 0403: 10の:228そして (リビジョンA1)
nano /etc/modprobe.d/vfio.conf を編集します。’
KVM オプション ignore_msrs=1x オプション vfio-pci ids=10de:2504,10の:228E disable_vga=1
'nano /etc/modprobe.d/kvm.conf を編集します。’
KVM オプション ignore_msrs=1
そして最後に、nano /etc/modprobe.d/iommu_unsafe_interrupts.conf を編集しました。’
オプション vfio_iommu_type1 allow_unsafe_interrupts=1"
Proxmoxのグラフィックカードのパススルーにステップが残っていると確信していると言っています, ただし、ホストを再起動した後、GPUをVMに完全に追加する方法がわかります.

次のステップ, ProxmoxでVMを作成することになります, ここに私が考えていたいくつかのことがあります; 「システム」タブで’ 「Q35」と表示する必要があります’ マシンタイプとして, BIOSオプションで「OVMF」を選択します (UEFIの)’,
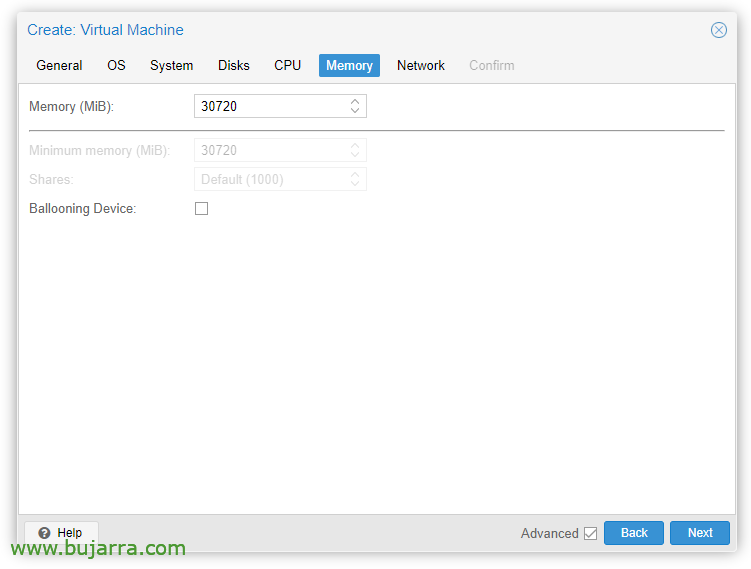
「メモリ」タブで’ 「バルーニングデバイス」のチェックを外す必要があります’
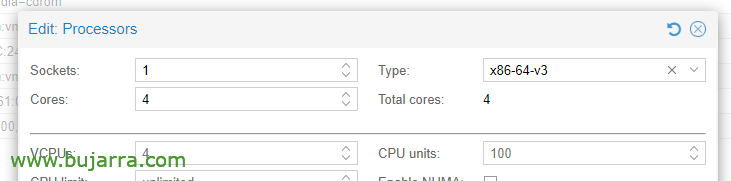
CPUオプション内, プロセッサの編集, タイプで, 少なくともx86-64-v3を選択する必要があります.
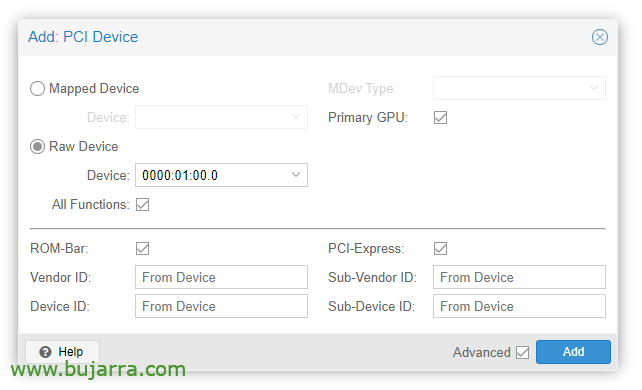
VMが作成されたら、PCIデバイスを追加できます, VMハードウェアを編集し、 “足す” > “PCIデバイス”. すべての機能をチェックします, ROMバー, プライマリ GPU と PCI-Express.
明らかに、そのグラフィックカードでは、OSをインストールするためにモニターを接続します (Ubuntuサーバー 24.04) そして画面上でそれを見る. また、インストールを行うには、USBキーボード/マウスをパススルーする必要があります。
その後、VMにOSをインストールできます, ドライバーをインストールするには、考慮する必要があります, Ubuntuデスクトップでは、インストール中にインストールされ、サーバーにも「チェックマーク」が付けられていると思います, 然も無くば, まだインストールできます:
sudo Ubuntu-drivers install sudo apt-get update sudo apt-get upgrade sudo reboot
Tras reiniciar la MV vemos si ha cargado correctamente con 'cat /proc/driver/nvidia/version’
NVRMバージョン: NVIDIA UNIX x86_64 カーネルモジュール 535.171.04 3月(火) 19 20:30:00 UTCの 2024 GCCバージョン:
Continuaríamos con la instalación de Docker (ドクター・オフィシャル) en la MV Ubuntu(英語):
sudo apt-get update sudo apt-get ca -certificates curl sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc sudo chmod a+r /etc/apt/keyrings/docker.asc エコー \ "デブ [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] httpsの://download.docker.com/linux/ubuntu \ $(. /etc/os-リリース && エコー "$VERSION_CODENAME") 厩" | \ sudo tee /etc/apt/sources.list.d/docker.list > /containerd.io docker-buildx-plugin docker-compose-plugin docker-buildx-plugin docker-curd-cli
Debemos instalar ahora el NVIDIA Container Toolkit (ドクター・オフィシャル) y lo habilitamos para Docker:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#デブ [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] httpsの://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list sudo apt update sudo apt -y install nvidia-container-toolkit sudo systemctl restart docker sudo nvidia-ctk runtime configure --runtime=docker sudo systemctl restart docker
Y ya es hora de desplegar los contenedores de Ollama y Open WebUI, こちらは:
git clone https://github.com/open-webui/open-webui.git CD オープン-webui/
Y le añadimos estos cambios al contenedor de Ollama, グラフを使用してAPIのポートを開くことができるようにします (ナノのdocker-compose.yaml):
実行中: NVIDIA環境: - NVIDIA_VISIBLE_DEVICES=すべてのポート: - 11434:11434
そして最後に、コンテナを降ろして開始します:
sudo docker compose up -d
そして、仮想マシンのIPを攻撃することでブラウザを開くことができます, ポート 3000TCP へ (デフォルト).
Open Web UIからのアクセスと開始

Open WebUIに初めてアクセスするときは、をクリックしてアカウントを作成できます。 “入る”, 名前を入力するだけでアカウントが作成されます, メールとパスワード, クリック “アカウントを作成する”.

そして、ここからは私たちが交流できる場所になります, ご覧のとおり、新しいチャットを作成し、必要なものについて彼らに相談することができます,
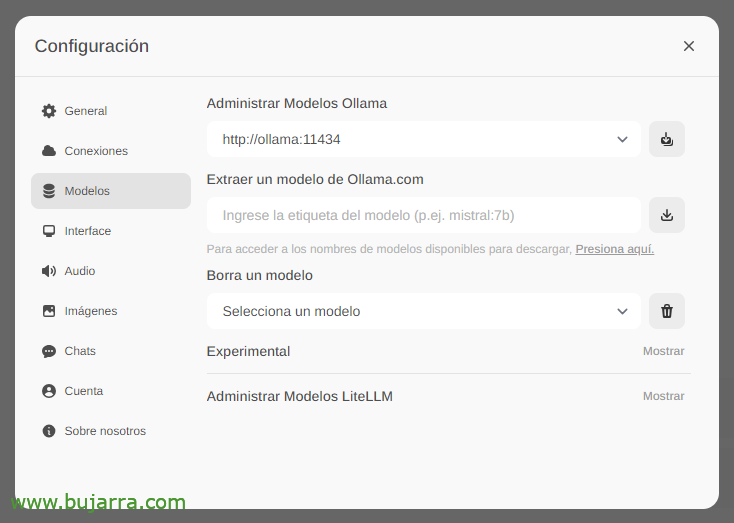
まず、最も重要なことは、大規模な言語モデルをダウンロードすることです (LLMの), 「設定」から’ > 'モデル’ 入力 Ollama.com から直接抽出できます。たとえば、ミストラル:7b, もちろん、私はあなたが訪問することをお勧めしますが 最もよく使用されるトップLLM, 興味のあるモデルを入力して、ダウンロードアイコンをクリックするだけです. 私はあなたを推薦します (今日まで) ラマ3, 本当に最高です.
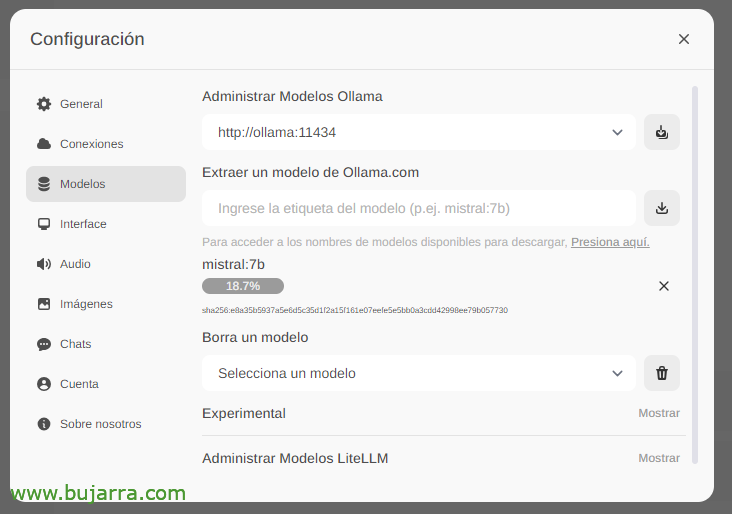
ダウンロードされるのを待ちます… そしてもちろん、好きなだけ降りることができます.
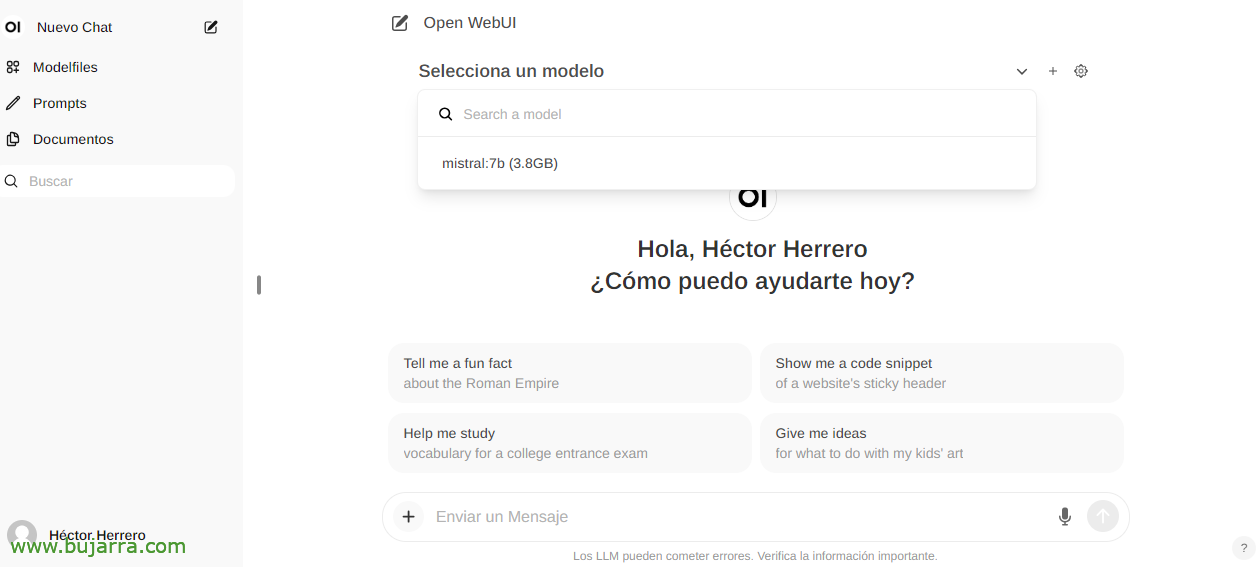
また、新しいチャットを作成するときは、ダウンロードした任意のモデルを選択して対話を開始できます.

そして何もない, 私たちはいじくり回し始めました, 私たちはあなたにどんな質問でも投げかけることができます….
画像認識

たとえば、Llama2 LLMを使用する場合、会話またはAPIで画像を送信し、それを説明するように依頼することができます, Grafanaの切り欠きを持つ印象的な例… これ以上の手がかりはあげない…
ドキュメントの操作

その可能性の別の簡単な例を見るために… 「ドキュメント」から’ 任意のドキュメントをアップロードし、その内容について会話をすることができます. 本をアップロードして、物事やアドバイスを求めることができます, 行く, それは本の内容によります… または、Active Directoryの移行に関するホワイトペーパーをアップロードするこの単なる例, そして…
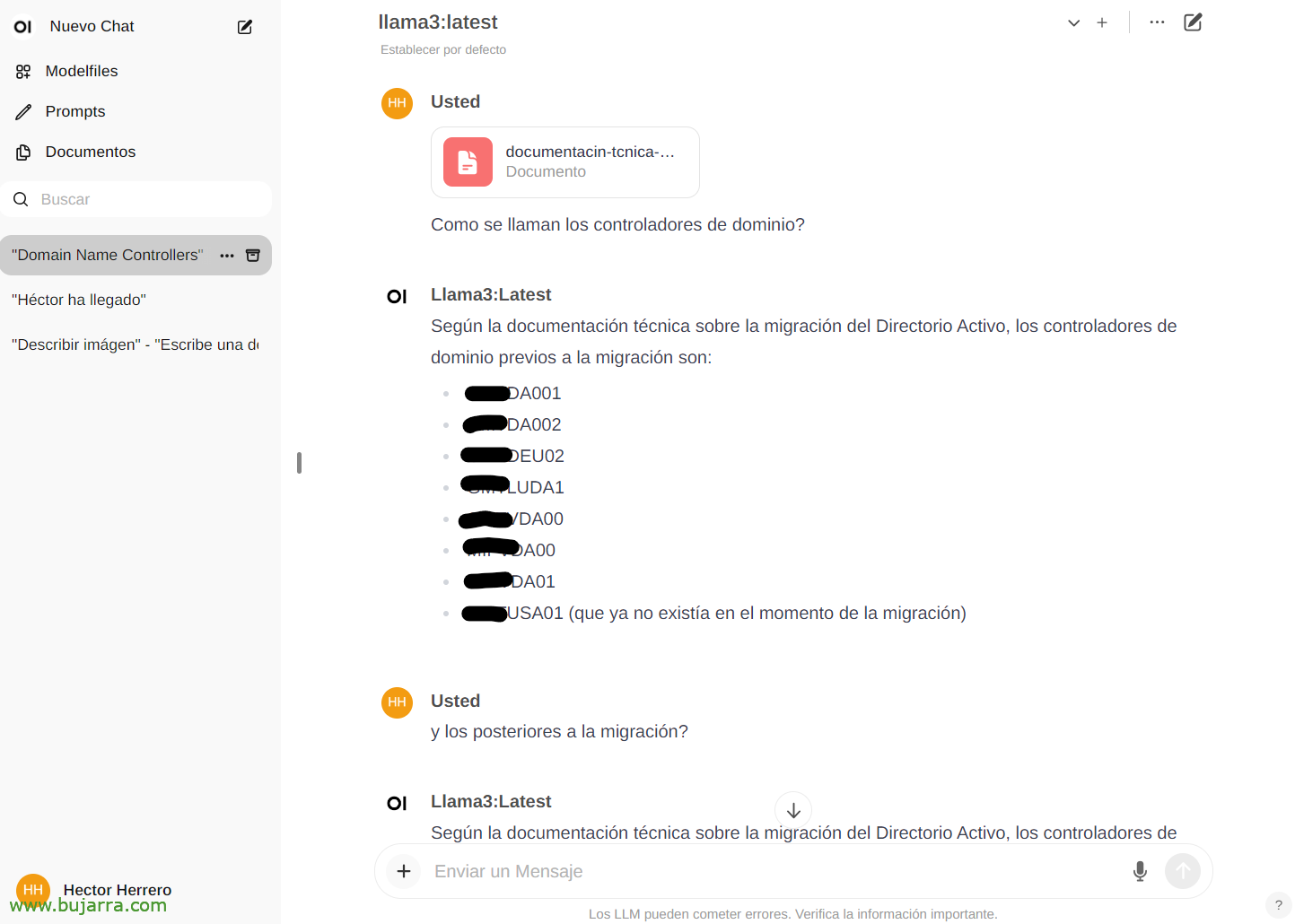
そして、チャットで、特定のドキュメントについて入力することで相談できます。 # ドキュメントに付けたタグを選択します. 印象的…
諸
そして、ドキュメントを完成させるのにも適しています, 私たちは将来、物事を見るでしょう, とてもとても良さそうに見えます, これだけでなく、私たちは見てきました, たとえば、APIのすべての可能性ではないにしても、任意のシステムをAIと統合できること. 安全なAI, 地元の, 無料, オラマはここにとどまります!
今後の投稿で, このAPIのおかげで、Centreonの通知を統合することができます, Elasticsearchより, ホームアシスタント付きのスマートホームの, そして、私は彼女に電話して質問をします, 自宅のあらゆるデバイスを直感的に操作, 非常に好奇心旺盛なアラートと長いエトセトラを受け取ります…

たとえば、curlを使用してサンプルクエリをスローしたい場合:
Curl HTTP://ローカルホスト:11434/api/generate -d '{ "モデル": "ミストラル:7b", "プロンプト": "アスレティック・ビルバオをご存知ですか?", "川": 偽 }'
{"モデル":"ミストラル:7b","created_at":"2024-03-29S12の:38:07.663941281Z","応答":" はい, アスレティック・クラブ・デ・ビルバオを知っています, は、ビルバオ市に本拠地を置くスペインのプロサッカークラブです, バスク. それはに基づいて設立されました 14 10 月 1894 現在、リーガでプレーしています, スペイン1部リーグ. 彼は彼の哲学に基づいたプレースタイルで知られています, クラブのユースカテゴリーからの昇格選手の育成を優先しています. そのスタジアムはサンマメスです。"
または、モデルを選択するためのパラメータを配置できること, あなたが多かれ少なかれ幻覚を見るようにする温度, 長さ… より多くの例が表示されます:
Curl HTTP://XXX.XXX.XXX.XXX:11434/api/generate -d '{ "モデル": "ミストラル:7b", "プロンプト": "アスレティック・ビルバオをご存知ですか?", "川": 偽, "温度": 0.3, "max_length": 80}'
まぁ, もう関わらない, 可能性のアイデアを得るために、私はそれが価値がある🙂と思う 私たちはより多くのものを見て、好奇心旺盛です. そして真実は、私がそれらを私のビジネスで使用し、それらは何度もあなたがすでにライバルのサプライヤーで何が起こるかを知っている差動値であるため、私はいくつかのものを省略しなければならないということです…
ハグをして、とても良い一週間をお過ごしください!










