
Abilitazione della deduplicazione in Windows 2012 R2

Una de grandes las novedades que trajo Windows Server 2012 es la posibilidad de deduplicar el contenido de un volumen, esta importantísima tecnología de ahorro en disco nos la daban hasta ahora las cabinas de almacenamiento de media/alta gama, a partir de ahora podremos anche desde el propio OS optimizar lo spazio del disco!

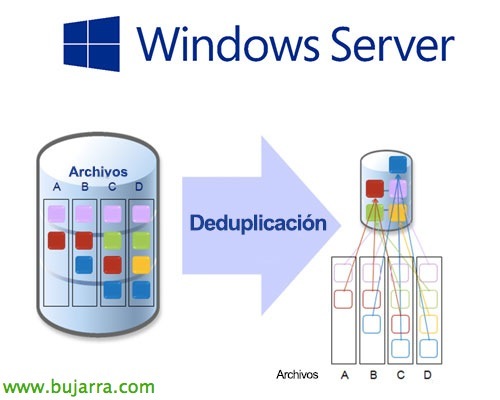
La deduplicazione consiste fondamentalmente nel separare i dati dell'hard disk in piccoli blocchi, analizzare i blocchi che si ripetono, e creare puntatori eliminando tutti i blocchi ripetuti, con questo potremo avere un risparmio molto importante al momento di archiviare informazioni, dipenderà dal contenuto archiviato, ma più blocchi simili ci sono, più risparmieremo 😉
Non possiamo abilitare la deduplicazione su volumi di sistema, né di avvio, né formattati con ReFS, né su volumi CSV (Cluster Shared Volumes). Dovrebbero essere partizionati come MBR o GUID e in NTFS, possono essere volumi locali o di una rete di archiviazione come iSCSI, FC… Disponiamo dello strumento ‘DDPEval.exe’ in %WinDir%System32″ una volta installato il ruolo sul server per non dover forzare una deduplicazione e utilizzare questo strumento per vedere quanto spazio libereremmo! Non si raccomanda di deduplicare volumi con database come SQL Server o Exchange Server poiché potrebbero corrodersi, in tal caso possiamo escludere le loro directory. In ambienti con Hyper-V si raccomanda di usarlo quando disponiamo di un volume con VHD di desktop virtuali simili, non su tutta la piattaforma in quanto tale con diversi server… tuttavia si dovrebbe sempre configurare la pianificazione del compito di deduplicazione quando non coincide con i carichi di lavoro o i backup.

Non male, per abilitare la deduplicazione, aggiungeremo il ruolo di 'Deduplicazione dati'’ all'interno del ruolo 'Servizi di file e archiviazione'.

Successivamente, Nel “Amministratore del server”, in “Servizi di file e archiviazione” > “Volumi”, potremo, su ogni volume, cliccare con il tasto destro per accedere a “Configura deduplicazione dati…”. Se ci guardiamo, in questo esempio lo eseguirò sul volume F: da 300 Gb e che ha solo 5 Gb liberi.

Potremo selezionare il tipo di deduplicazione da eseguire, se su un volume che archivia file o uno che archivia macchine virtuali (normalmente desktop VDI). Indicheremo i file da deduplicare, quelli con più di X giorni o potremo escludere alcune estensioni in modo che siano escluse, così come selezionare cartelle da escludere o file specifici. Selezionare “Impostare la pianificazione della deduplicazione…”,

Y configuramos una o dos programaciones para que analice los ficheros del volumen y realice su deduplicación!

Non male, podremos ver el estado de la deduplicación desde PowerShell con 'get-DedupStatus', y si queremos iniciar inmediatamente el trabajo que acabamos de programar de deduplicación bastará con ejecutar 'start-DedupJob DISCO: -type optimization'.

Podremos ir verificando el estado del trabajo con 'get-DedupJob’ donde podremos ver el % avanzato, para volver a ver el estado de la deduplicación en el volumen lo haremos con 'get-DedupStatus', iremos verificando cuánto vamos optimizando!!

O podremos visualmente, volver al “Amministratore del server” y actualizar los volúmenes, en este en concreto teníamos antes 5Gb libres y ahora 146Gb! Si querríamos volver al origen por alguna razón y des-deduplicar el contenido recentemente optimizado ejecutaremos 'start-DedupJob DISCO: -type Unoptimization'.










