Installation et configuration de VMware SRM 5 avec SRA et reprotéger

Ce document se présente comme une extension du précédent où nous avons vu l’installation et la configuration complètes de VMware vCenter Site Recovery Manager 5 (SRM 5) avec Réplication vSphere, Dans cet autre document, nous allons voir comment configurer la réplication à l’aide des tableaux (nous utiliserons HP Lefthands, soutenu par SRM 5), plus tard, nous verrons un autre nouveau SRM 5 qu’après avoir validé un test et effectué une migration/reprise après sinistre planifiée vers le centre de données de sauvegarde, nous terminerons par une 'reprotection’ réorganiser toutes les machines du centre de données principal tel qu’il était à l’origine.

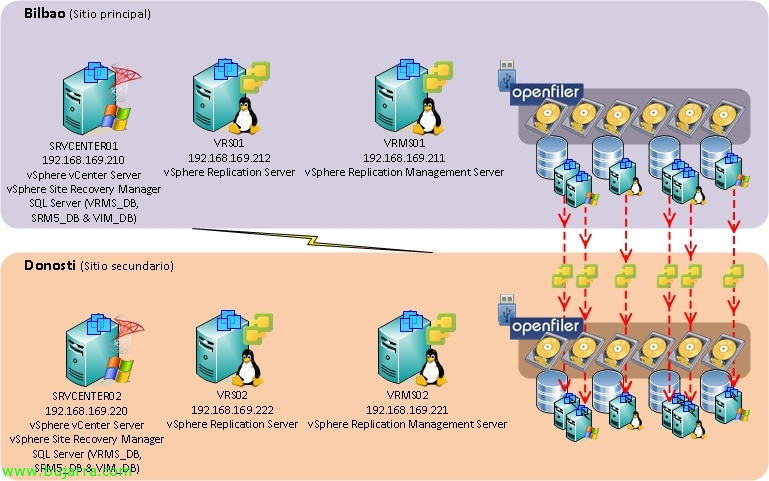
Voici le scénario simple du document, où nous avons dans le Datacenter principal un environnement VMware vCenter 5 où nous avons déjà installé SRM 5, les machines virtuelles de notre infrastructure virtuelle sont stockées dans un couple de baies en cluster dans le Datacenter principal grâce à la configuration de répliques programmées, s'appuyant sur des snapshots dans les volumes VMFS, il copiera au niveau des blocs le contenu de ceux-ci vers le cluster secondaire des baies HP Lefthand. Ces baies sont iSCSI, elles existent à la fois en physique et en appliance virtuelle ou VSA, tant pour les LAB que pour les petits environnements.

Este sería un pantallazo de la consola de gestión de mi entorno SAN de HP Lefthand donde vemos un par de sitios, uno que alberga al clúster principal formado por una sóla VSA (lo normal sería tener 2 VSA en mirror en cada sitio), que tiene una única LUN llamada LFT01 que contiene configurada una programación de instantáneas remotas sobre dicho volumen contra las cabinas de almacenamiento del sitio de respaldo.

Deberem0s realizar la instalación de Site Recovery Adapter (MADAME) que es el software que nos facilitará el proveedor de almacenamiento, este software permitirá al SRM conectarse a la cabina de almacenamiento y mostrará las LUN’s que disponen de una replicación habilitada & programada, pour que SRM puisse interagir avec les baies et répliquer, tester et/ou nettoyer les LUN d'origine ou de destination. Nous devrons donc installer le logiciel SRA de notre fabricant sur chaque serveur SRM 5.0 (VMware vCenter Site Recovery Manager 5.0).

Une fois SRA installé, nous devrons redémarrer le service 'VMware vCenter Recovery Manager Server'’ sur chaque serveur où SRM est installé.

D’accord, une fois que nous avons installé SRM, SRA et configuré les liens entre les différents vCenter, nous devrons enregistrer les gestionnaires de la partie SAN, Dans mon cas, comme nous l'avons mentionné précédemment, je dispose d'un cluster dans le CPD principal et d'un autre dans le CPD secondaire., Je vais inscrire dans le CPD protégé le cluster de gestion des baies HP Lefthand ainsi que dans le CPD de sauvegarde le cluster formé par les VSA de ce site. Pressé “Ajouter Array Manager”,

Nous indiquons un nom et le type de SRA, dans mon cas HP P4000 SRA. Dans ce PDF officiel de VMware nous disposons de tous les fabricants, ainsi que quelles baies et avec quel firmware seraient supportées par SRM 5. En principe avec la version 5.0 de SRM, les systèmes de stockage suivants seraient compatibles: Vallon Compellent (Storage Center); Dell EqualLogic (PS4000E, PS4000X, PS4000XV, PS4100E, PS4100X, PS4100XV, PS5000E, PS5000X, PS5000XV , PS5500E, PS6000E, PS6000S, PS6000X, PS6000XV, PS6000XVS, PS6010E, PS6010S, PS6010X, PS6010XV, PS6010XVS, PS6100E, PS6100S, PS6100X, PS6100XS, PS6100XV, PS6500E, PS6500X, PS6510E, PS6510X, PS100E, PS200E. PS300E, PS3600X, PS3700X, PS3800XV, PS3900XV, PS400E, PS50E & PS70E); EMC Celerra (NX4, NS-G2, NS20, NS20FC, NS40, NS40FC, NS80, NS-120, NS-240 NS-480, NS-960 & NSX); EMC VNX (VNX5100, VNX5300, VNX5500, VNX5700 & VNX7500); EMC Isilon (S-series, NL-series & X-series); EMC Symmetrix (DMX-2, DMX-3, DMX-4, VMAX, VMAX SE, VMAXe, DMX-4 950, DMX-4 1500, DMX-4 2500, DMX-4 4500, DMX-3 950, DMX-3 1500, DMX-3 2500, DMX-3 3500, DMX-3 4500, DMX-1000, DMX-2000 & DMX-3000); EMC CLARiiON (CX300, CX3-10, CX3-20, CX3-40, CX3-80, CX4-120, CX4-240, CX4-480, CX4-960); IBM (DS6000, DS8000, 2145-4F2, 2145-8F2, 2145-8F4, 2145-8G4, 2145-8A4, 2145-CF8, 2145-CG8, 2076-112, 2076-124, 2076-312, 2076-324, N series, ), HP EVA (4000, 4100, 4400, 6000, 6100, 6400, 8000, 8100 & 8400); HP LeftHand (P4300, P4300 G2, P4500, P4500 G2, P4800, P4800 G2, P4000 VSA, NSM2120, P4300, P6300 & P6500); NetApp (ONTAP 7.2 ou supérieur, E2600, E399x, E4900, E54xx, E69xx, E79xx, IS5000, IS4600, IS4100, IS4000, 6780, 6580, 6180, 6540, 6140); Hitachi (TagmaStore, Virtual Storage, Universal Storage V & VM, SANRISE NSC 55, USP 100, USP 600, USP 1100, Adaptable Modular Storage 2100, 2300 & 2500); FalconStor (CDP Gateway, IPStor Enterprise, NSS Gateway, NSS SA, NSS VS & NSS VA); Fujitsu (ETERNUS4000 300/500, ETERNUS4000 400/600, ETERNUS8000 700/900/1100/2100, ETERNUS8000 800/1200/2200, ETERNUS DX90, ETERNUS DX90 S2, ETERNUS DX410/DX410 S2/DX440/DX440 S2 & ETERNUS DX8100/DX8400/DX8700).

Indicamos los credenciales y la dirección IP del clúster primario, “Prochain”,

“Finir”,

D’accord, realizamos los mismos pasos para el CPD de respaldo, una vez agregadas ambos sistemas de almacenamiento, nous devrons les coupler, ainsi dans actions nous cliquons sur 'Activer'.

Une fois que les baies sont jumelées, nous devons créer un groupe de protection où nous sélectionnerons la réplication basée sur les baies et non sur vSphere, nous sélectionnerons les datastores que nous protégerons (avec le contenu des MVs à protéger), ensuite nous créerons un plan de récupération avec ces groupes de protection avec lesquels nous réaliserons les tests de plans de récupération de désastre entre le CPD principal & le secondaire. “Créer un groupe de protection”,

Nous sélectionnons le site protégé (origine), nous sélectionnons dans le type “Réplication basée sur tableau (SAINT)” et nous sélectionnons les baies récemment jumelées, “Prochain”,

Nous sélectionnons les datastores à protéger, En bas, nous pouvons voir les machines virtuelles qui seront sauvegardées car elles sont hébergées sur ce volume VMFS, “Prochain”,

Nous donnons un nom au groupe de protection & “Prochain”,

Nous confirmons que la configuration est correcte & “Finir”!

Pas mal, Une fois que notre sauvegarde est définie, nous devons créer un plan de reprise où nous sélectionnerons nos groupes de protection et configurerons des ordres de démarrage/arrêt ou d'autres options par la suite, Cliquez sur “Créer un plan de récupération”,

Nous indiquons quel sera le site de reprise, “Prochain”,

Nous sélectionnons le(s) groupe(s) de protection,

Nous définissons les réseaux de test que nous utiliserons dans le datacenter de sauvegarde, Une fois ce plan généré & nous devrons le tester jusqu'à ce que nous n'ayons plus d'erreurs, “Prochain”. Si nous n'avons pas de réseaux isolés pour effectuer les tests, nous devrons les créer afin d'éviter les conflits d'IP entre le CPD de production et celui-ci. “Prochain”,

Nous indiquons le nom du plan de récupération, “Prochain”,

Nous confirmons que tout va bien & “Finir”,

Comme nous l'avons vu dans le document précédent de SRM 5.0, nous devons éditer les étapes de récupération en indiquant nos configurations au moment de démarrer/arrêter les machines, Priorités… une fois configuré selon nos besoins, nous cliquerons sur “Test” pour vérifier si la configuration est correcte,

Marque “Répliquer les modifications récentes apportées au site de récupération” avec l'intention de transférer les derniers changements de nos datastores des cabines HP Lefthand entre Bilbao et Donosti, “Prochain”,

Nous confirmons que le site protégé est le bon, ainsi que la destination, “Commencer” pour commencer le test!

Parfait, après quelques minutes, il aura répliqué au niveau SAN les derniers blocs modifiés entre les différents sites, ensuite, il enregistrera les machines, sur… quand nous verrons que tout démarre conformément aux exigences, nous procédons à un nettoyage pour le préparer au cas où nous devrions un jour utiliser le site. Nous effectuons un “Nettoyage”,

“Prochain” pour commencer avec l'assistant de nettoyage après le test satisfaisant.

“Commencer” pour commencer, cela prendra quelques minutes et nous aurons déjà la réplication entre les deux CPD prête et protégée avec VMware SRM 5 à l'exception de l'initier en cas de besoin.

D’accord, étant un laboratoire, nous pouvons simuler la panne du CPD principal et effectuer une récupération dans le CPD de secours, Pour ce faire, cliquez sur “Récupération”,

Nous marquons le contrôle de “Je comprends que ce processus modifiera de manière permanente les machines virtuelles et l'infrastructure des deux centres de données, protégé et de récupération” indiquant que VMware nous transfère la responsabilité de ce que nous allons réaliser, et nous sélectionnons le type de récupération qui nous intéresse, si c'est planifié (en cas d'erreur, cela sera annulé) ou le CPD principal n'existe tout simplement plus (car il a brûlé…) nous procéderons à une récupération après sinistre.

Comme d'habitude, nous vérifions que c'est correct & “Commencer”,

Et c’est tout! il prendra tout le temps nécessaire pour répliquer nos baies (si cela est possible), il effectuera un arrêt ordonné en inversant nos options de démarrage dans le site de machines protégées, il modifiera le datastore source en lecture seule et migrera le contenu vers les destinations Lefthand, par la suite, il modifiera ce stockage pour pouvoir y écrire et démarrera les machines déjà dans le site de récupération.
Une des nouveautés de VMware Site Recovery Manager 5 en utilisant la réplication SAN, est la possibilité d'utiliser la reprotection ou reprotect, ce qui nous permettra de ramener le site principal à son état initial une fois que nous avons tout déplacé vers le site de sauvegarde., ainsi, en utilisant cette nouvelle fonctionnalité, nous laisserons tout comme c'était à l'origine. Cliquez sur “Reprotéger”,

Nous confirmons que nous ne pourrons pas revenir en arrière sur ce mouvement, car pour cela, nous devrions utiliser un plan de récupération… “Prochain”,

Nous confirmons que les nouveaux sites de protection et de récupération sont corrects et nous commencerions, de la même manière que les processus de test ou de récupération, le transfert des données/machines entre les deux sites. “Commencer”!

Et c’est tout, Nous attendrions que cela se termine et nous pourrons alors générer à nouveau les plans de récupération, cette fois-ci contre (une fois de plus) le centre de données de sauvegarde, etc, etc…