

Ollama, Premiers pas avec l’IA locale

Pendant quelques mois, j’ai bricolé avec une IA locale et open source; Et je voulais partager un peu avec vous dans une série d’articles quelques-unes de ses possibilités dans notre quotidien. Mais dans ce premier document, nous verrons comment nous pouvons le mettre en place et quelques notions de base de ses possibilités.
Premières choses, Si vous le souhaitez, je vais vous dire à quoi je l’utilise aujourd’hui au cas où cela pourrait servir d’idée; Pour l’instant, exclusivement pour générer du texte, Il peut être pauvre, Mais c’est un monde très vaste. Allant de la réception de toute notification ou système d’alerte, L’alerte vous rend plus humain ou peut vous suggérer par où commencer sa résolution. Pour envoyer des e-mails périodiques, E-mails envoyés quotidiennement par mon organisation, Mensuel… Eh bien, cela leur donne une autre touche, Il les nourrit de certaines données et les rend très réelles. Aussi pour le système domotique, me permet d’avoir des conversations avec le, Il m’alerte, Utilisation de la voix, Phrases différentes…
Pour l’instant, Comme je l’ai dit, Pour générer du texte; Mais les possibilités sont nombreuses, comme la connexion à des bases de données et qui nous permet d’effectuer des requêtes avec un langage naturel. Ou la possibilité d’engager des conversations et des questions concernant un document que nous avons envoyé à l’IA, ou une image et qu’il décrit ce qu’il voit… Tout au long du document, je donnerai quelques exemples simples pour que quelque chose d’agréable puisse être fait.

Le second, bien, Comment cela s’appelle-t-il ?… Comme vous pouvez l’imaginer, il existe de nombreuses options et possibilités, Je vais vous parler de Ollama (Bibliothèque open source pour les modèles et les applications d’IA). Ollama nous permettra d’utiliser LLM (Grand modèle de langage), C’est, modèles de langage entraînés pour l’IA, Ils peuvent être open source ou payants, Peut être 100% hors ligne ou non, Au goût. Evidemment, et en fonction du LLM que nous utilisons, nous aurons besoin de plus ou moins de puissance, C’est, disposer d’un GPU pour que les réponses soient immédiates. Nous pourrons utiliser l’API Ollama pour poser des questions à distance avec d’autres systèmes, Très très puissant. Et je vous recommande Ouvrir WebUI en tant qu’interface graphique pour Ollama, ainsi, avec notre navigateur, nous aurons l’interface que vous attendez pour pouvoir travailler confortablement avec votre IA.
Ce que j’ai dit, nous aurons besoin d’un GPU pour avoir les meilleures performances possibles, cela dépendra du LLM que nous utilisons et du Go requis par chaque modèle, De cette façon, les réponses seront immédiates. En ce qui concerne le matériel compatible, il est assez étendu (NVIDIA, AMD, Apple M1…), Je vous quitte Voici sa liste.
Je vais séparer l’article en:
- Installation rapide d’Ollama et d’Open WebUI sous Windows, Mac ou Linux
- Installation d’Ollama et d’Open WebUI sur un MV Linux sur Proxmox avec Docker
- Accès via Open Web UI et mise en route
- Reconnaissance d’images
- Interagir avec les documents
- Plusieurs
Installation rapide d’Ollama et d’Open WebUI sous Windows, Mac ou Linux
Si vous voulez le prouver, Et vite maintenant, Voici l’option, puisque vous pourrez installer Ollama sur votre Linux, Mac ou Windows, Au cas où vous voudriez l’exécuter localement, avec votre GPU. Nous irons à la Site de téléchargement d’Ollama, nous sélectionnerons notre système d’exploitation et le téléchargerons chez nous, Prochain, Suivant et installé.
Sur Linux, nous allons le télécharger et l’installer comme suit:
curl -fsSL https://ollama.com/install.sh | Sh >>> Téléchargement ollama... ######################################################################## 100,0%##O#- # >>> Installation d’ollama dans /usr/local/bin... >>> Création d’un utilisateur ollama... >>> Ajout de l’utilisateur ollama au groupe de rendu.. >>> Ajout de l’utilisateur ollama au groupe de vidéos.. >>> Ajout de l’utilisateur actuel au groupe ollama... >>> Création du service ollama systemd.. >>> Activation et démarrage du service ollama... Création du lien symbolique /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service. >>> GPU NVIDIA installé.
Et nous pouvons télécharger directement un LLM et l’essayer si nous le voulons depuis le shell:
Ollama Run Mistral Pulling Manifest Pulling E8A35B5937A5... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 4.1 GB tirant 43070e2d4e53... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 11 KB tirant e6836092461f... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 42 B tirant ed11eda7790d... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 30 B tirant f9b1e3196ecf... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 483 B vérification du manifeste d’écriture de résumé sha256 suppression de toutes les couches inutilisées succès >>> Bonjour, bonjour! Cela signifie que "Bonjour" en espagnol.
Si nous voulons qu’il réponde aux requêtes de l’API, nous devons modifier le fichier de service 'nano /etc/systemd/system/ollama.service ‘ Additionnant:
Environnement="OLLAMA_HOST=0.0.0.0:11434"
Et nous rechargeons le service:
sudo systemctl daemon-reload sudo systemctl restart ollama
Et si nous voulons avoir l’interface graphique pour gérer notre IA depuis le navigateur, nous devrons configurer Open WebUI, le plus rapide et le plus pratique dans un conteneur Docker:
git clone https://github.com/open-webui/open-webui.git CD open-webui/ sudo Docker compose up -d

Et on peut ouvrir le navigateur en attaquant l’IP de la machine au port 3000tcp (Faire défaut).
Installation d’Ollama et d’Open WebUI sur un MV Linux sur Proxmox avec Docker
Et cette partie, je vous dis pourquoi… Mon idée est d’avoir une machine pour l’IA centralisée, une machine vers laquelle différents systèmes peuvent pointer pour effectuer différentes requêtes, pour cela, Doit être une machine virtuelle (En ce qui concerne les avantages, haute disponibilité, Sauvegarde, Snapshots…), une machine virtuelle à laquelle nous transmettons la carte graphique et qui dispose du GPU pour celle-ci. Pour cela, nous utiliserons Proxmox, (un jour, nous avons parlé du suicide de VMware) et la VM sera un serveur Ubuntu 24.04. Et pendant que nous y sommes,, dans cette VM, il exécutera Ollama et Open WebUI dans des conteneurs Docker.
Voici les étapes que j’ai suivies pour passer par la carte graphique dans Proxmox, Je ne sais pas s’ils sont les plus corrects, Mais cela fonctionne parfaitement.
Après l’installation de Proxmox 8.2, Configurez-le au minimum, avoir exécuté la post-installation de Proxmox VE des scripts d’aide Proxmox VE, nous allons dire à Proxmox de ne pas utiliser cette carte graphique PCIe, nous avons commencé à modifier GRUB avec 'nano /etc/default/grub’ et nous modifions la ligne suivante:
#GRUB_CMDLINE_LINUX_DEFAULT="tranquille" GRUB_CMDLINE_LINUX_DEFAULT="calme intel_iommu=on iommu=pt vfio_iommu_type1 initcall_blacklist=sysfb_init" INTEL--> GRUB_CMDLINE_LINUX_DEFAULT="silencieux intel_iommu=on" AMD--> GRUB_CMDLINE_LINUX_DEFAULT="silencieux amd_iommu=on"
Et nous exécutons
update-grub
Nous avons ajouté les modules suivants avec 'nano /etc/modules':
Je vis vfio_iommu_type1 vfio_pci vfio_virqfd
Nous verrouillons les pilotes avec 'nano /etc/modprobe.d/blacklist.conf':
Liste noire Nouveau Liste noire NVIDIA Liste noire NVIDIA* Liste noire Radeon
Nous notons les identifiants avec: 'spci -n -s 01:00’, Comme vous pouvez le voir, S’il y a une personne curieuse, dans mon cas, il s’agit d’une NVIDIA RTX 3060 12GB connecté à PCIe 1.
01:00.0 0300: 10de:2504 (Rév A1) 01:00.1 0403: 10de:228et (Rév A1)
Nous éditons 'nano /etc/modprobe.d/vfio.conf’
Options KVM ignore_msrs=1x Options vfio-pci ids=10de:2504,10de:228e disable_vga=1
Nous éditons 'nano /etc/modprobe.d/kvm.conf’
Options KVM ignore_msrs=1
Et enfin, nous avons édité 'nano /etc/modprobe.d/iommu_unsafe_interrupts.conf’
Options vfio_iommu_type1 allow_unsafe_interrupts=1"
Je vous dis que je suis sûr qu’il me restera une étape pour le passthrough de la carte graphique dans Proxmox, mais après avoir redémarré l’hôte, vous verrez comment vous pouvez parfaitement ajouter le GPU à une VM.

L’étape suivante, sera de créer la VM dans Proxmox, Voici quelques choses que j’avais en tête; dans l’onglet 'Système'’ Nous devons indiquer « Q35 »’ en tant que type de machine, et dans les options du BIOS, choisissez 'OVMF (UEFI)’,
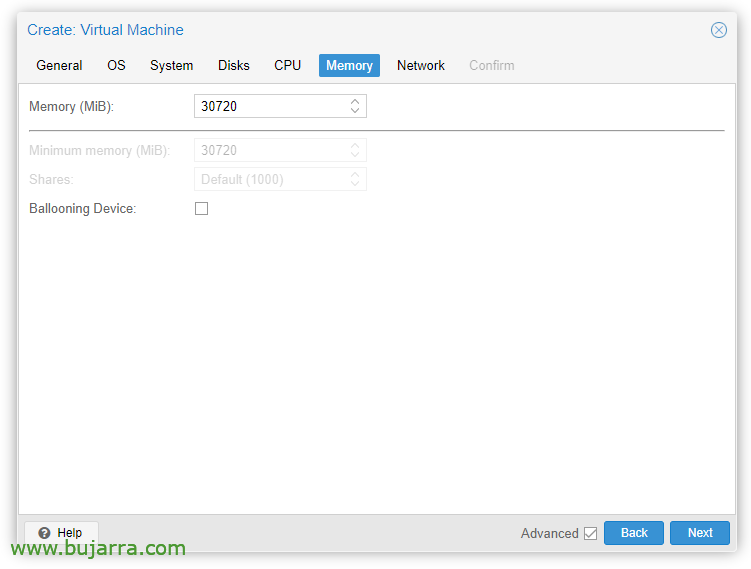
Dans l’onglet 'Mémoire'’ nous devons décocher 'Ballooning Device’
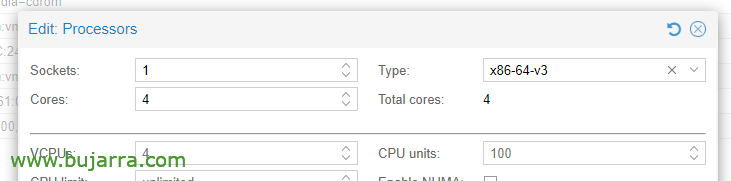
Dans les options du processeur, Modification des processeurs, dans le type, Il faut choisir au moins x86-64-v3.
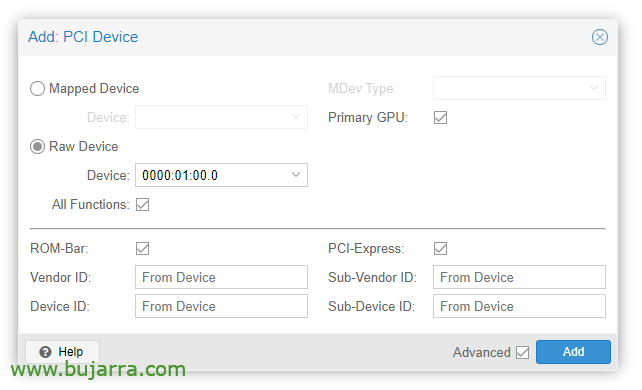
Une fois la VM créée, nous pouvons y ajouter un périphérique PCI, nous modifions le matériel de la VM et “Ajouter” > “Périphérique PCI”. Nous vérifions toutes les fonctions, Barre ROM, GPU principal et PCI-Express.
Évidemment, dans cette carte graphique, nous allons connecter un moniteur pour installer le système d’exploitation (Serveur Ubuntu 24.04) et le voir à l’écran. Nous devrons également passer par un clavier/souris USB pour faire l’installation.
Ensuite, nous pouvons installer le système d’exploitation dans la machine virtuelle, Il faut en tenir compte pour installer les pilotes, dans Ubuntu Desktop, je pense qu’ils sont installés lors de l’installation et dans le serveur en marquant également une 'coche', autrement, Nous pouvons toujours les installer:
sudo Ubuntu-drivers install sudo apt-get update sudo apt-get upgrade sudo reboot
Tras reiniciar la MV vemos si ha cargado correctamente con 'cat /proc/driver/nvidia/version’
Version NVRM: Module noyau NVIDIA UNIX x86_64 535.171.04 Tue Mar 19 20:30:00 UTC 2024 Version du CCG:
Continuaríamos con la instalación de Docker (Doc oficial) en la MV Ubuntu:
sudo apt-get update sudo apt-get install ca-certificates curl sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc sudo chmod a+r /etc/apt/keyrings/docker.asc echo \ "Deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \ $(. /etc/os-release && ÉCHO "$VERSION_CODENAME") étable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
Debemos instalar ahora el NVIDIA Container Toolkit (Doc oficial) y lo habilitamos para Docker:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#Deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list sudo apt update sudo apt -y install nvidia-container-toolkit sudo systemctl restart docker sudo nvidia-ctk runtime configure --runtime=docker sudo systemctl restart docker
Y ya es hora de desplegar los contenedores de Ollama y Open WebUI, pour cela:
git clone https://github.com/open-webui/open-webui.git cd open-webui/
Y le añadimos estos cambios al contenedor de Ollama, para que pueda usar la gráfica y nos abra el puerto para las APIs (nano docker-compose.yaml):
Duree: Environnement NVIDIA: - NVIDIA_VISIBLE_DEVICES=tous les ports: - 11434:11434
Et enfin, nous déchargeons et démarrons les conteneurs:
sudo docker compose up -d
Et puis nous pouvons ouvrir le navigateur en attaquant l’IP de la machine virtuelle, vers le port 3000TCP (Faire défaut).
Accès via Open Web UI et mise en route

La première fois que nous accédons à Open WebUI, nous pouvons créer un compte en cliquant sur “Inscrire”, Nous créerons un compte en entrant simplement notre nom, e-mail et un mot de passe, Cliquez sur “Créer un compte”.

Et à partir de là, ce sera à partir de là que nous pourrons interagir, comme nous pouvons le voir, nous pouvons créer de nouveaux chats et les consulter avec ce dont nous avons besoin,
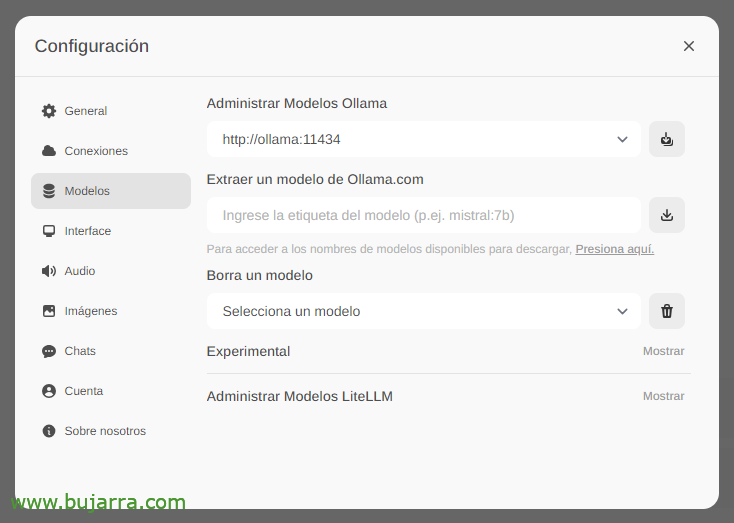
La première chose et la plus importante sera de télécharger les grands modèles de langage (LLM), à partir de 'Paramètres'’ > 'Modèles’ Nous pouvons les extraire directement de Ollama.com nous tapons, par exemple, Mistral:7b, bien que bien sûr, je vous recommanderai de visiter le top LLM les plus utilisés, Tout ce que vous avez à faire est de taper le modèle qui vous intéresse et de cliquer sur l’icône de téléchargement. Je vous recommande (à ce jour) lama3, C’est un vrai plaisir.
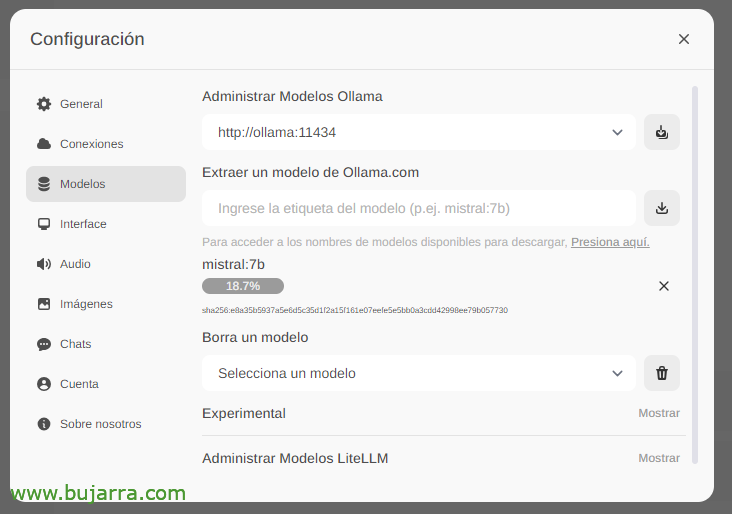
Nous attendons qu’il se télécharge… Et bien sûr, nous pouvons en descendre autant que nous le voulons.
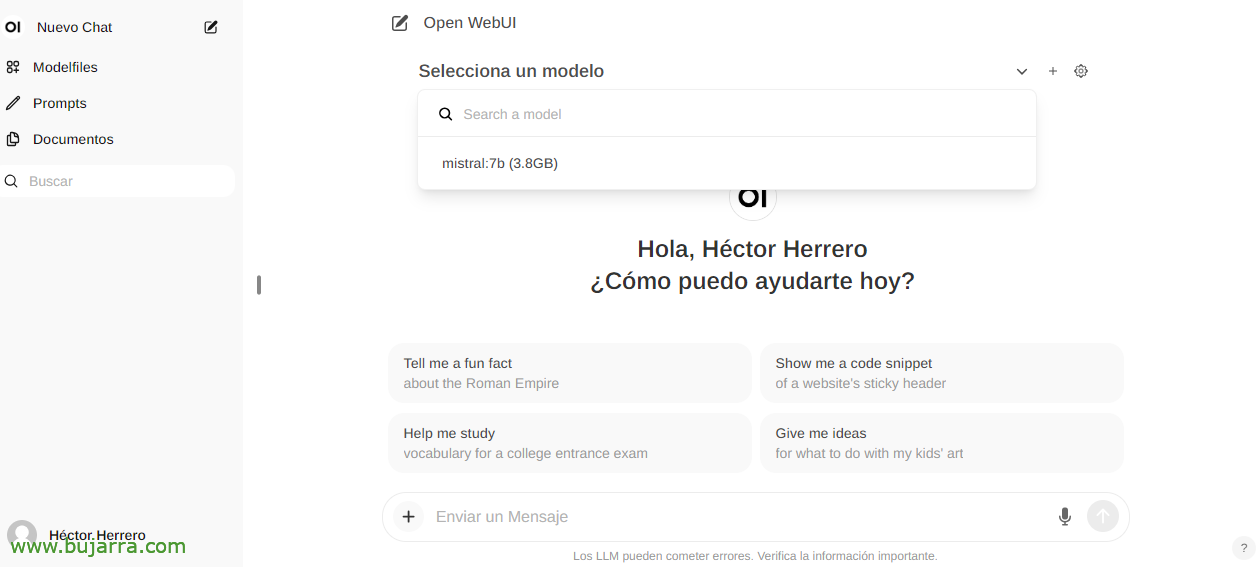
Et lorsque vous créez un nouveau chat, vous pouvez choisir n’importe quel modèle téléchargé pour commencer à interagir.

Et rien, Nous avons commencé à bricoler, Nous pouvons vous poser toutes vos questions….
Reconnaissance d’images

Si, par exemple, nous utilisons le Llama2 LLM, nous pouvons vous envoyer une image dans une conversation ou par API et vous demander de nous la décrire, un exemple impressionnant avec une découpe Grafana… Je ne vous donne plus d’indices…
Interagir avec les documents

Pour voir un autre exemple rapide de ses possibilités… À partir de la page 'Documents’ Nous pouvons télécharger n’importe quel document, puis avoir des conversations sur son contenu. Vous pouvez télécharger un livre et lui demander des choses ou des conseils, aller, Cela dépend du sujet du livre… Ou ce simple exemple que je télécharge un livre blanc d’une migration Active Directory, et…
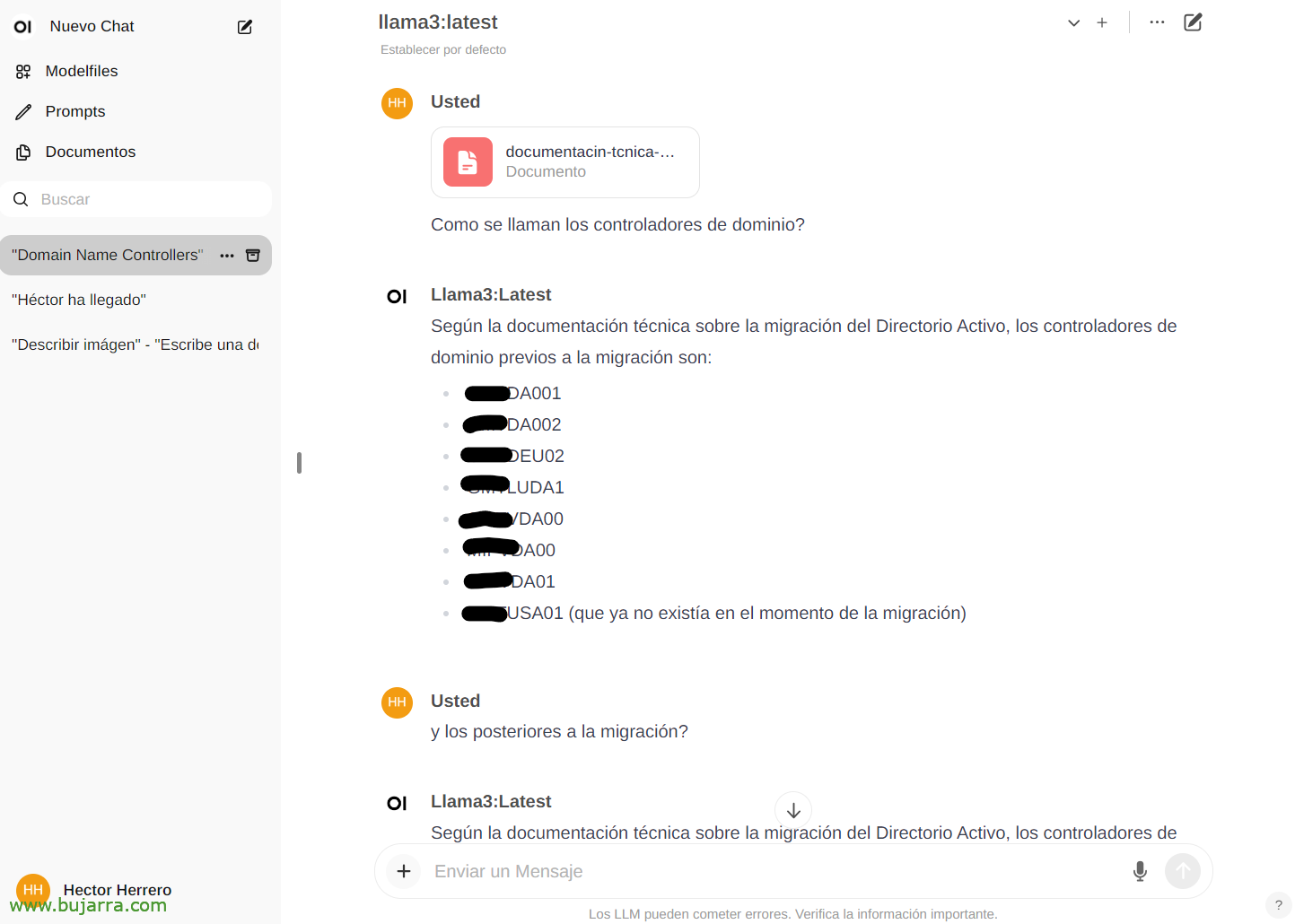
Et puis dans le chat, nous pouvons vous consulter sur un document spécifique en tapant le # et en sélectionnant la balise que nous avons mise sur le document. Impressionnant…
Plusieurs
Et bien pour finaliser le document, Nous verrons des choses à l’avenir, Ça a l’air très très bien, Et ce n’est pas tout ce que nous avons vu, si ce n’est toutes ses possibilités avec l’API par exemple et pouvoir intégrer n’importe quel système avec notre IA. Une IA sûre, local, libre, Ollama est là pour rester!
Dans les prochains articles, grâce à cette API, nous pourrons intégrer les notifications de Centreon, par Elasticsearch, de notre maison intelligente avec Home Assistant, et je l’appelle au téléphone et lui pose des questions, Contrôlez n’importe quel appareil de la maison de manière intuitive, recevoir des alertes très curieuses et un long etcetera…

Si l’on veut par exemple avec curl lancer une requête d’exemple:
Boucle HTTP://localhost:11434/api/generate -d '{ "modèle": "mistral:7b", "prompt": "Connaissez-vous l’Athletic Bilbao?", "Ruisseau": Faux }'
{"modèle":"mistral:7b","created_at":"2024-03-29S12:38:07.663941281Z","réponse":" Oui, Je connais Athletic Club de Bilbao, est un club espagnol de football basé à Bilbao, Pays basque. Elle a été fondée sur 14 Octobre 1894 et joue actuellement en LaLiga, La première division espagnole de football. Il est connu pour son style de jeu basé sur sa philosophie, qui privilégie le développement des joueurs de promotion issus des catégories de jeunes du club. Son stade est le San Mamés."
Ou de pouvoir mettre des paramètres pour choisir le modèle, la température à vous faire plus ou moins halluciner, Longueurs… Nous verrons plus d’exemples:
Boucle HTTP://XXX.XXX.XXX.XXX:11434/api/generate -d '{ "modèle": "mistral:7b", "prompt": "Connaissez-vous l’Athletic Bilbao?", "Ruisseau": Faux, "température": 0.3, "max_length": 80}'
Puits, Je ne m’implique plus, pour se faire une idée des possibilités je pense que cela en vaut la peine 🙂 Nous verrons plus de choses et curieux. Et la vérité est que je dois omettre certaines choses parce que je les utilise dans mon entreprise et ce sont des valeurs différentielles que vous savez souvent déjà ce qui se passe avec les fournisseurs rivaux…
Un câlin et je vous souhaite une très bonne semaine!










