
Überwachung von Latenzen mit Telegraf

Etwas sehr Einfaches und sehr Nützliches kann die Latenz zu verschiedenen IP-Adressen sein und kennen, Wir können in Echtzeit visualisieren, mit alkoholfreiem Getränk 1 Sekunde, die Zeiten, die es dauert, bis IP-Adressen antworten, Sie können privat oder öffentlich sein; Zum Beispiel, um herauszufinden, ob wir Probleme mit dem Internet haben und wo sie sind, Zum Beispiel 🙂
Sie werden sehen, wie schnell und einfach! Ich denke, wir alle haben Influxdb und Grafana bereits installiert, Wenn Sie Fragen haben, haben wir diese Erster Beitrag. Brunnen, Nun, von jeder Maschine, auf der Telegraf installiert ist, werden wir es in einer Minute erledigen. Wir müssen entscheiden, von wo aus wir den Ping ausführen, um seine Latenz zu kennen, Wenn wir Zweifel haben, Auf der Influxdb-Maschine selbst kann der Telegraf-Agent installiert sein, und von dort aus werden wir die Pings durchführen..
Wir bearbeiten die Telegraf-Datei und im Abschnitt Eingaben reicht es aus, etwas wie dieses hinzuzufügen, wobei wir im Beispiel einen Ping an das DNS von Google und einen weiteren an eine lokale IP in meinem Netzwerk sehen, einen Router:
... [[inputs.ping]] URLs = ["8.8.8.8"] # erforderliche Anzahl = 1 Schnittstelle = "ENS32" name_override = "ping_google" Intervall = "1s" [[inputs.ping]] URLs = ["192.168.0.1"] # erforderliche Anzahl = 1 Schnittstelle = "ENS32" name_override = "ping_router_movistar" Intervall = "1s" ...
Denken Sie daran, wenn wir Erfrischungsgetränke verwenden möchten 1 Sekunde, Wir müssen dies in den Parametern 'interval' und 'flush_interval' angeben. Wie gewöhnlich, Nachdem Sie auf Konfigurationsdatei getippt haben, Wir starten den Telegraf-Dienst neu und lassen ihn die neue Konfiguration auslesen:
sudo systemctl restart telegraf
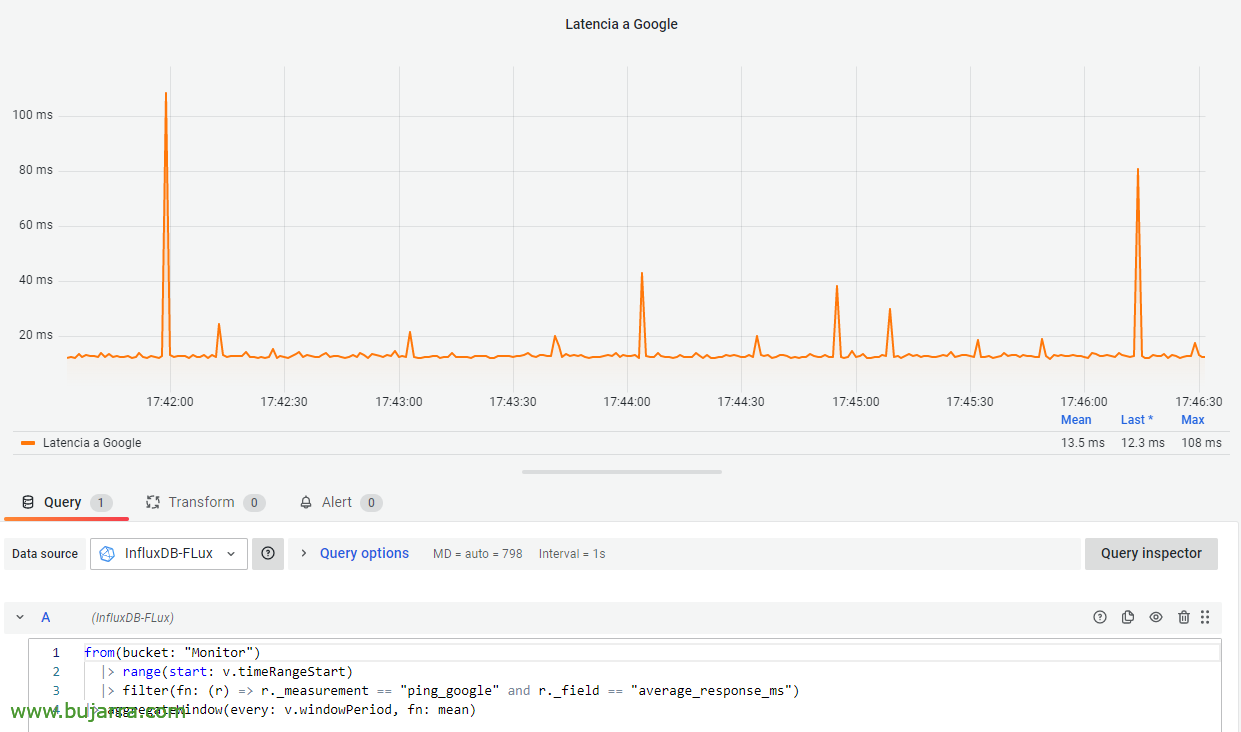
Und dazu und ein Kuchen… wir werden die Daten bereits in Influxdb haben, also geht es als nächstes nach Grafana! Dort haben wir die Datenquelle bereits für diese Influxdb konfiguriert, und der nächste Schritt wird sein, ein Dashboard in einem Dashboard hinzuzufügen, gegen die besagte Influxdb-Datenquelle vom Typ Flux und mit dieser Abfrage haben wir sie:
Von(Eimer: "Monitor") |> Bereich(Anfangen: v.timeRangeStart) |> Filter(Fn: (r) => r._measurement == "ping_google" und r._field == "average_response_ms") |> aggregateWindow(jeder: v.windowPeriode, Fn: Bedeuten)

Und zack!! Wir haben ihn! Was in einer Minute? Kostbar! Wir haben bereits ein Beispiel dafür, wie man Latenzen zu verschiedenen IP-Adressen in Echtzeit visualisieren kann. Sie können Dashboards mit Ablaufverfolgungen zeichnen, Routen und wissen, wo der Engpass ist, sofort oder natürlich als historische Beratung.
Umarmungen an alle, So sind wir modern… Jedenfalls, Jetzt im Ernst, Passt auf euch auf, Vielen Dank für Ihre Lektüre, Kleine Ratten, wenn Sie in sozialen Medien mit "Gefällt mir" markieren oder teilen… Jedenfalls, Vielen Dank!










