

Ollama, Erste Schritte mit lokaler KI

Ein paar Monate lang habe ich an einer lokalen und Open-Source-KI getüftelt; Und ich wollte mit Ihnen in einer Reihe von Beiträgen einige seiner Möglichkeiten in unserem Alltag teilen. Aber in diesem ersten Dokument werden wir sehen, wie wir es einrichten können und einige grundlegende Vorstellungen von seinen Möglichkeiten.
Das Wichtigste, Wenn ihr mögt, verrate ich euch, wofür ich es heute verwende, falls es als Idee dienen kann; Erst einmal, ausschließlich zur Textgenerierung, Er kann arm sein, Aber es ist eine sehr weite Welt. Angefangen vom Erhalt von Benachrichtigungen oder Warnsystemen, Die Warnung macht Sie menschlicher oder kann vorschlagen, wo Sie mit der Lösung beginnen sollten. So senden Sie regelmäßige E-Mails, Täglich von meiner Organisation gesendete E-Mails, Monatlich… Nun, es gibt ihnen eine andere Note, Es füttert sie mit bestimmten Daten und macht sie sehr real. Auch für das Hausautomationssystem, ermöglicht es mir, Gespräche mit dem Home zu führen, Es alarmiert mich, Verwenden der Stimme, Unterschiedliche Phrasen…
Erst einmal, Wie ich schon sagte, So generieren Sie Text; Aber die Möglichkeiten sind vielfältig, wie zum Beispiel die Verbindung zu Datenbanken, die es uns ermöglicht, Abfragen mit einer natürlichen Sprache zu stellen. Oder die Möglichkeit, Gespräche und Fragen zu einem Dokument zu führen, das wir an die KI gesendet haben, oder ein Bild und dass er beschreibt, was er sieht… Im Laufe des Dokuments werde ich einige einfache Beispiele geben, damit etwas Angenehmes getan werden kann.

Die zweite, Nicht schlecht, Wie nennt man das?… Wie Sie sich vorstellen können, gibt es viele Optionen und Möglichkeiten, Ich werde mit Ihnen darüber sprechen Ollama (Open-Source-Bibliothek für KI-Modelle und -Anwendungen). Ollama wird es uns ermöglichen, LLM zu verwenden (Großes Sprachmodell), Das ist, Sprachmodelle, die für KI trainiert wurden, Sie können Open Source oder kostenpflichtig sein, Kann sein 100% offline oder nicht, al gusto. Natürlich, und je nachdem, welches LLM wir verwenden, benötigen wir mehr oder weniger Strom, Das ist, über eine GPU verfügen, so dass sofort reagiert werden kann. Wir werden in der Lage sein, die Ollama-API zu verwenden, um Fragen aus der Ferne mit anderen Systemen zu stellen, Sehr sehr leistungsstark. Und ich empfehle Ihnen WebUI öffnen als GUI-Schnittstelle für Ollama, Mit unserem Browser haben wir also die Schnittstelle, von der Sie erwarten, dass Sie bequem mit Ihrer KI arbeiten können.
Was ich gesagt habe, Wir werden eine GPU benötigen, um die bestmögliche Leistung zu erzielen, Dies hängt von dem von uns verwendeten LLM und den GB ab, die für jedes Modell erforderlich sind, Auf diese Weise werden die Antworten sofort erfolgen. Was die kompatible Hardware betrifft, so ist sie recht umfangreich (NVIDIA, AMD, Apple M1…), Ich verlasse dich Hier ist die Liste.
Ich werde den Artikel unterteilen in:
- Schnelle Installation von Ollama und Open WebUI unter Windows, Mac oder Linux
- Installation von Ollama und Open WebUI auf einem Linux-MV auf Proxmox mit Docker
- Zugriff über Open Web UI und erste Schritte
- Bilderkennung
- Interagieren mit Dokumenten
- Mehrere
Schnelle Installation von Ollama und Open WebUI unter Windows, Mac oder Linux
Wenn Sie es beweisen wollen, Und jetzt schnell, Das ist die Option, da Sie Ollama auf Ihrem Linux installieren können, Mac oder Windows, Falls Sie es lokal ausführen möchten, mit Ihrer GPU. Wir gehen zum Ollama Download-Website, Wir wählen unser Betriebssystem aus und laden es zu uns herunter, Nächster, Weiter und Installiert.
Unter Linux werden wir es wie folgt herunterladen und installieren:
curl -fsSL https://ollama.com/install.sh | Pst >>> Ollama herunterladen... ######################################################################## 100,0%##O#- # >>> Ollama wird nach /usr/local/bin installiert.. >>> Ollama-Benutzer erstellen... >>> Hinzufügen eines Ollama-Benutzers zur Rendergruppe.. >>> Hinzufügen eines Ollama-Benutzers zur Videogruppe.. >>> Den aktuellen Benutzer zur Ollama-Gruppe hinzufügen.. >>> Erstellen des ollama systemd-Dienstes... >>> Aktivieren und Starten des Ollama-Dienstes... Symlink /etc/systemd/system/default.target.wants/ollama.service erstellt → /etc/systemd/system/ollama.service. >>> NVIDIA-GPU installiert.
Und wir können direkt ein LLM herunterladen und es ausprobieren, wenn wir es aus der Shell heraus möchten:
Ollama Run Mistral Pulling Manifest Pulling E8A35B5937A5... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 4.1 GB zieht 43070e2d4e53... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 11 KB zieht e6836092461f... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 42 B zieht ed11eda7790d... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 30 B zieht f9b1e3196ecf... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████▏ 483 B Überprüfung des Sha256-Digest-Schreibmanifests, um nicht verwendete Layer erfolgreich zu entfernen >>> Hallo, hallo! Das bedeutet, "Hallo" auf Spanisch.
Wenn wir möchten, dass es auf API-Anfragen antwortet, müssen wir die Servicedatei 'nano /etc/systemd/system/ollama.service bearbeiten. ‘ Addierend:
Umgebung="OLLAMA_HOST=0.0.0.0:11434"
Und wir laden den Service wieder auf:
sudo systemctl daemon-reload sudo systemctl restart ollama
Und wenn wir die GUI haben möchten, um unsere KI über den Browser zu verwalten, müssen wir Open WebUI einrichten, die schnellsten und bequemsten in einem Docker-Container:
git clone https://github.com/open-webui/open-webui.git CD open-webui/ sudo Docker compose up -d

Und wir können den Browser öffnen, indem wir die IP des Computers an Port 3000tcp angreifen (Vorgabe).
Installation von Ollama und Open WebUI auf einem Linux-MV auf Proxmox mit Docker
Und in diesem Teil erzähle ich Ihnen, warum… Meine Idee ist es, eine Maschine für zentralisierte KI zu haben, Eine Maschine, auf die verschiedene Systeme verweisen können, um unterschiedliche Abfragen zu stellen, hierfür, Es muss sich um einen virtuellen Computer handeln. (Zum Thema Vorteile, Hohe Verfügbarkeit, Sicherungskopie, Schnappschüsse…), eine VM, an die wir die Grafikkarte weiterleiten und die die GPU dafür hat. Hierfür werden wir Proxmox verwenden, (Eines Tages sprachen wir über den Selbstmord von VMware) und die VM wird ein Ubuntu Server sein 24.04. Und wenn wir schon dabei sind,, In dieser VM werden Ollama und Open WebUI in Docker-Containern ausgeführt.
Hier sind die Schritte, die ich befolgt habe, um die Grafikkarte in Proxmox zu durchlaufen, Ich weiß nicht, ob sie die korrektesten sind, Aber es funktioniert perfekt.
Nach der Installation von Proxmox 8.2, Konfigurieren Sie es minimal., den Proxmox VE Post Install der Proxmox VE Helper-Scripts ausgeführt haben, Wir werden Proxmox sagen, dass sie diese PCIe-Grafik nicht verwenden sollen, Wir begannen mit der Bearbeitung von GRUB mit 'nano /etc/default/grub’ und wir modifizieren die folgende Zeile:
#GRUB_CMDLINE_LINUX_DEFAULT="ruhig" GRUB_CMDLINE_LINUX_DEFAULT="ruhiges intel_iommu=an iommu=pt vfio_iommu_type1 initcall_blacklist=sysfb_init" INTEL--> GRUB_CMDLINE_LINUX_DEFAULT="leise intel_iommu=an" AMD--> GRUB_CMDLINE_LINUX_DEFAULT="leise amd_iommu=ein"
Und wir setzen um
update-grub
Wir haben die folgenden Module mit 'nano /etc/modules' hinzugefügt::
Ich lebe vfio_iommu_type1 vfio_pci vfio_virqfd
Wir sperren die Treiber mit 'nano /etc/modprobe.d/blacklist.conf':
Blacklist Nouveau Blacklist NVIDIA Blacklist NVIDIA* Blacklist Radeon
Wir schreiben die IDs auf mit: 'spci -n -s 01:00’, Wie Sie sehen können, Wenn es eine neugierige Person gibt, in meinem Fall ist es eine NVIDIA RTX 3060 12GB mit PCIe verbunden 1.
01:00.0 0300: 10von:2504 (Rev A1) 01:00.1 0403: 10von:228und (Rev A1)
Wir bearbeiten 'nano /etc/modprobe.d/vfio.conf’
KVM-Optionen ignore_msrs=1x Optionen vfio-pci ids=10de:2504,10von:228e disable_vga=1
Wir bearbeiten 'nano /etc/modprobe.d/kvm.conf’
KVM-Optionen ignore_msrs=1
Und schließlich haben wir 'nano /etc/modprobe.d/iommu_unsafe_interrupts.conf bearbeitet.’
Optionen vfio_iommu_type1 allow_unsafe_interrupts=1"
Ich sage Ihnen, dass ich sicher noch einen Schritt für das Grafikkarten-Passthrough in Proxmox übrig habe, aber nach dem Neustart des Hosts werden Sie sehen, wie Sie die GPU perfekt zu einer VM hinzufügen können.

Der nächste Schritt, besteht darin, die VM in Proxmox zu erstellen, Hier sind einige Dinge, die ich im Kopf hatte; auf der Registerkarte "System"’ Wir müssen 'Q35’ als Maschinentyp, und wählen Sie in den BIOS-Optionen 'OVMF (UEFI)’,
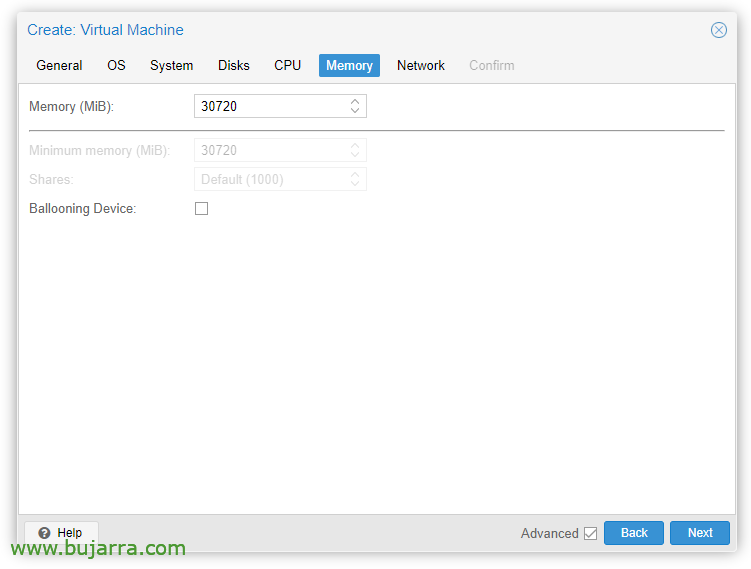
Auf der Registerkarte "Speicher"’ Wir müssen das Häkchen bei "Ballooning Device" entfernen.’
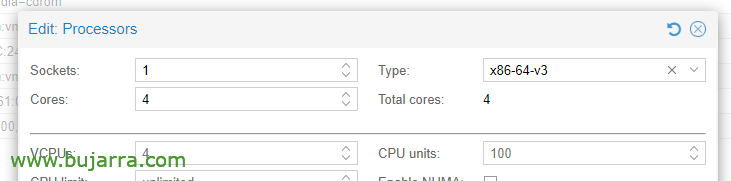
In den CPU-Optionen, Bearbeiten der Prozessoren, im Feld Typ, Wir müssen mindestens x86-64-v3 wählen.
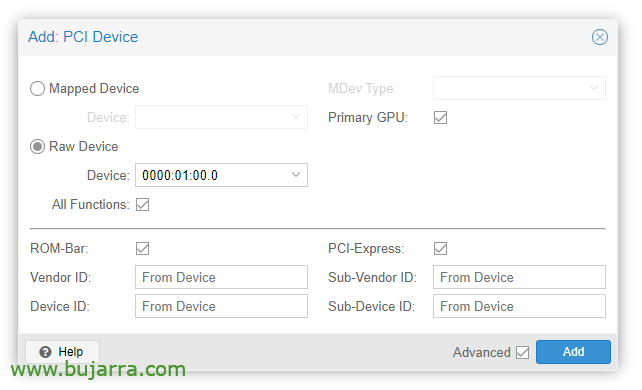
Sobald die VM erstellt wurde, können wir ihr ein PCI-Gerät hinzufügen, wir bearbeiten die VM-Hardware und “Hinzufügen” > “PCI-Gerät”. Wir prüfen alle Funktionen, ROM-Leiste, Primäre GPU und PCI-Express.
Offensichtlich werden wir in dieser Grafikkarte einen Monitor anschließen, um das Betriebssystem zu installieren (Ubuntu-Server 24.04) und sehen Sie es auf dem Bildschirm. Wir müssen auch eine USB-Tastatur/-Maus durchlaufen, um die Installation durchzuführen.
Dann können wir das Betriebssystem auf der VM installieren, Wir müssen berücksichtigen, um die Treiber zu installieren, in Ubuntu Desktop denke ich, dass sie während der Installation installiert werden und auf dem Server auch ein Häkchen markieren, sonst, Wir können sie immer noch installieren:
sudo ubuntu-drivers install sudo apt-get update sudo apt-get upgrade sudo reboot
Tras reiniciar la MV vemos si ha cargado correctamente con 'cat /proc/driver/nvidia/version’
NVRM-Ausführung: NVIDIA UNIX x86_64 Kernel-Modul 535.171.04 Di Mär 19 20:30:00 UTC 2024 GCC-Version:
Continuaríamos con la instalación de Docker (doc oficial) en la MV Ubuntu:
sudo apt-get update sudo apt-get install ca-zertifikate curl sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc sudo chmod a+r /etc/apt/keyrings/docker.asc echo \ "1_i386.deb [arch=$(dpkg --print-architektur) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \ $(. /etc/os-Veröffentlichung && ECHO "$VERSION_CODENAME") Stall" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
Debemos instalar ahora el NVIDIA Container Toolkit (doc oficial) y lo habilitamos para Docker:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#1_i386.deb [signiert von=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list sudo apt update sudo apt -y install nvidia-container-toolkit sudo systemctl restart docker sudo nvidia-ctk runtime configure --runtime configure --runtime = docker sudo systemctl restart docker
Y ya es hora de desplegar los contenedores de Ollama y Open WebUI, hierfür:
git clone https://github.com/open-webui/open-webui.git cd open-webui/
Und wir haben diese Änderungen dem Ollama-Container hinzugefügt, damit ich den Graphen verwenden und den Port für die APIs öffnen kann (Nano docker-compose.yaml):
Laufzeit: NVIDIA-Umgebung: - NVIDIA_VISIBLE_DEVICES=alle Ports: - 11434:11434
Und schließlich entladen und starten wir die Container:
sudo docker compose up -d
Und dann können wir den Browser öffnen, indem wir die IP der virtuellen Maschine angreifen, zum Port 3000TCP (Vorgabe).
Zugriff über Open Web UI und erste Schritte

Wenn wir zum ersten Mal auf Open WebUI zugreifen, können wir ein Konto erstellen, indem wir auf klicken “Einschreiben”, Wir erstellen ein Konto, indem wir einfach unseren Namen eingeben, E-Mail und ein Passwort, Anklicken “Erstellen Sie ein Konto”.

Und von hier aus werden wir interagieren können, Wie wir sehen können, können wir neue Chats erstellen und sie mit dem konsultieren, was wir brauchen,
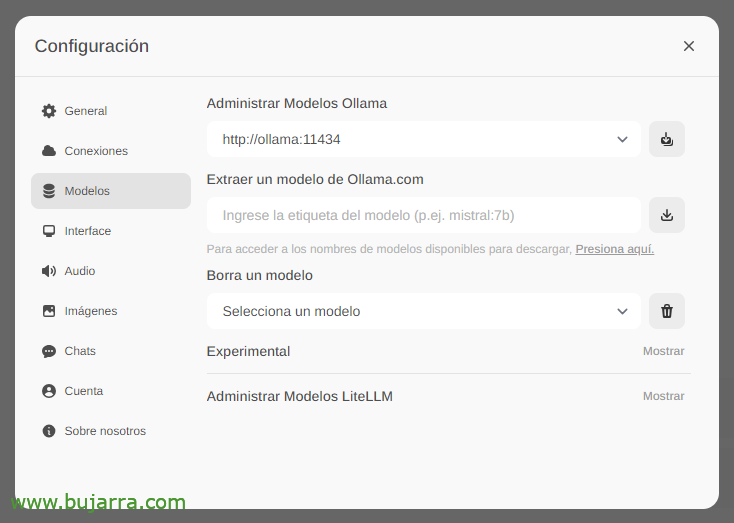
Das erste und wichtigste wird sein, die großen Sprachmodelle herunterzuladen (LLM), von 'Einstellungen'’ > "Modelle’ Wir können sie direkt aus Ollama.com extrahieren, die wir eingeben, z. B. Mistral:7b, obwohl ich Ihnen natürlich empfehlen werde, die Top LLM am häufigsten verwendet, Alles, was Sie tun müssen, ist, das Modell einzugeben, an dem Sie interessiert sind, und auf das Download-Symbol zu klicken. Ich empfehle Ihnen (Bis heute) Lama3, Es ist ein echter Knaller.
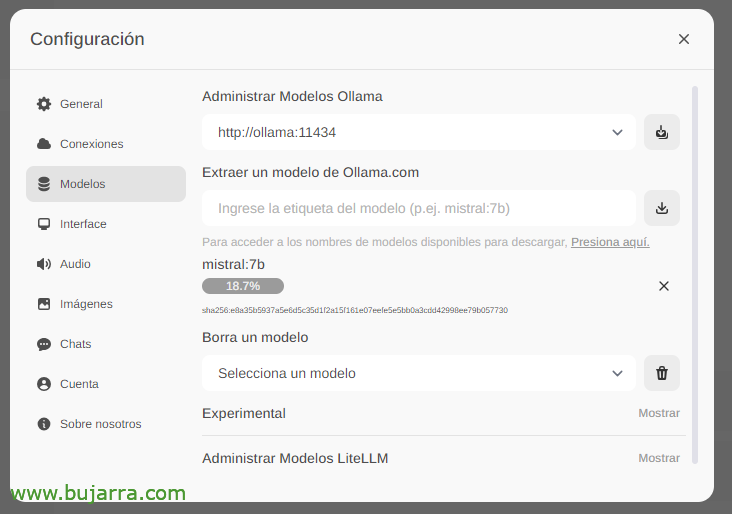
Wir warten, bis es heruntergeladen wird… Und natürlich können wir so viele runtergehen, wie wir wollen.
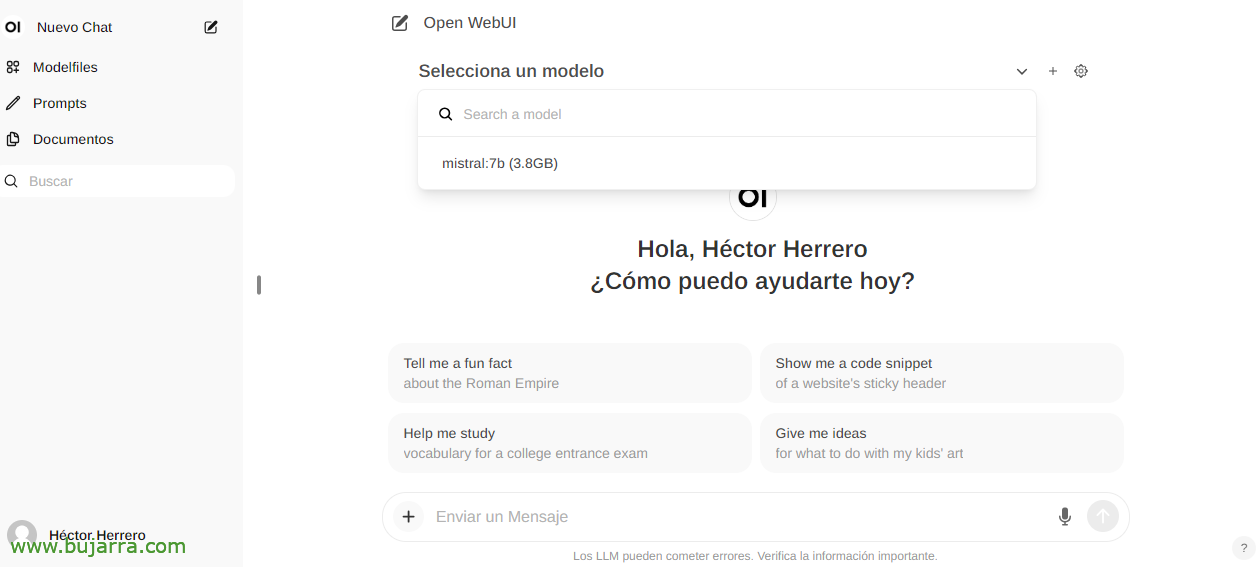
Und wenn Sie einen neuen Chat erstellen, können Sie ein beliebiges heruntergeladenes Modell auswählen, um mit der Interaktion zu beginnen.

Und nichts, Wir fingen an zu tüfteln, Wir können alle Fragen an Sie richten….
Bilderkennung

Wenn wir z.B. das Llama2 LLM verwenden, können wir Ihnen in einer Konversation oder per API ein Bild senden und Sie bitten, es uns zu beschreiben, ein eindrucksvolles Exemplar mit einem Grafana-Ausschnitt… Ich gebe dir keine weiteren Hinweise…
Interagieren mit Dokumenten

Um ein weiteres kurzes Beispiel für seine Möglichkeiten zu sehen… Aus "Dokumente"’ Wir können jedes Dokument hochladen und dann Gespräche über seinen Inhalt führen. Du kannst ein Buch hochladen und es um Dinge oder Ratschläge bitten, los, Das hängt davon ab, worum es in dem Buch geht… Oder dieses bloße Beispiel, dass ich ein Whitepaper einer Active Directory Migration hochlade, und…
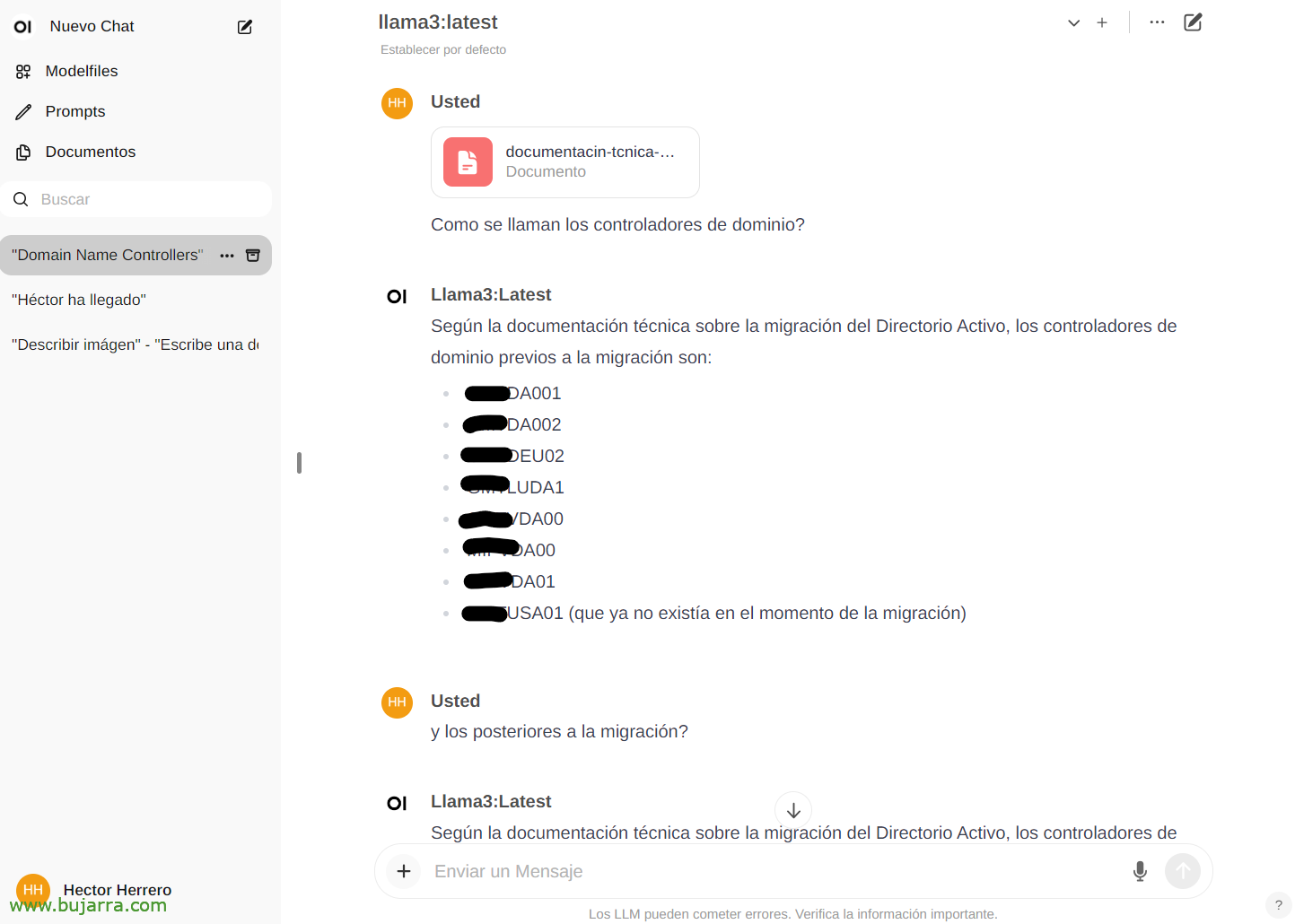
Und dann können wir Sie im Chat zu einem bestimmten Dokument konsultieren, indem wir die # und wählen Sie das Tag aus, das wir auf das Dokument gesetzt haben. Eindrucksvoll…
Mehrere
Und gut für die Fertigstellung des Dokuments, Wir werden die Dinge in der Zukunft sehen, Es sieht sehr, sehr gut aus, Nicht nur das, was wir gesehen haben, wenn nicht alle Möglichkeiten mit der API zum Beispiel und die Möglichkeit, jedes System mit unserer KI zu integrieren. Eine sichere KI, lokal, kostenlos, Ollama ist hier, um zu bleiben!
In zukünftigen Beiträgen, Dank dieser API werden wir in der Lage sein, die Benachrichtigungen von Centreon zu integrieren, von Elasticsearch, unseres Smart Homes mit Home Assistant, und ich rufe sie an und stelle ihr Fragen, Steuern Sie jedes Gerät im Haus auf intuitive Weise, Erhalten Sie sehr neugierige Benachrichtigungen und ein langes usw.…

Wenn wir zum Beispiel mit curl eine Beispielabfrage werfen wollen:
HTTP krümmen://Localhost:11434/api/generate -d '{ "Modell": "Mistral:7b", "prompt": "Kennen Sie Athletic Bilbao?", "Bach": FALSCH }'
{"Modell":"Mistral:7b","created_at":"2024-03-29Nr. S12:38:07.663941281Z","Antwort":" Ja, Ich kenne Athletic Club de Bilbao, ist ein spanischer Profifußballverein mit Sitz in der Stadt Bilbao, Baskenland. Es wurde gegründet am 14 Oktober 1894 und spielt derzeit in LaLiga, Die erste spanische Fußballliga. Er ist bekannt für seinen Spielstil, der auf seiner Philosophie basiert, die die Entwicklung von Aufstiegsspielern aus den Jugendkategorien des Vereins priorisiert. Das Stadion ist das San Mamés."
Oder in der Lage zu sein, Parameter zur Auswahl des Modells festzulegen, die Temperatur, um Sie mehr oder weniger halluzinieren zu lassen, Längen… Wir werden noch mehr Beispiele sehen:
HTTP krümmen://XXX.XXX.XXX.XXX:11434/api/generate -d '{ "Modell": "Mistral:7b", "prompt": "Kennen Sie Athletic Bilbao?", "Bach": FALSCH, "Temperatur": 0.3, "max_length": 80}'
Brunnen, Ich mische mich nicht mehr ein, um eine Vorstellung von den Möglichkeiten zu bekommen Ich denke, es lohnt 🙂 sich Wir werden mehr Dinge sehen und neugierig. Und die Wahrheit ist, dass ich einige Dinge weglassen muss, weil ich sie in meinem Geschäft benutze, und es sind unterschiedliche Werte, von denen man oft schon weiß, was mit konkurrierenden Lieferanten passiert…
Eine Umarmung und wünsche dir eine schöne Woche!










