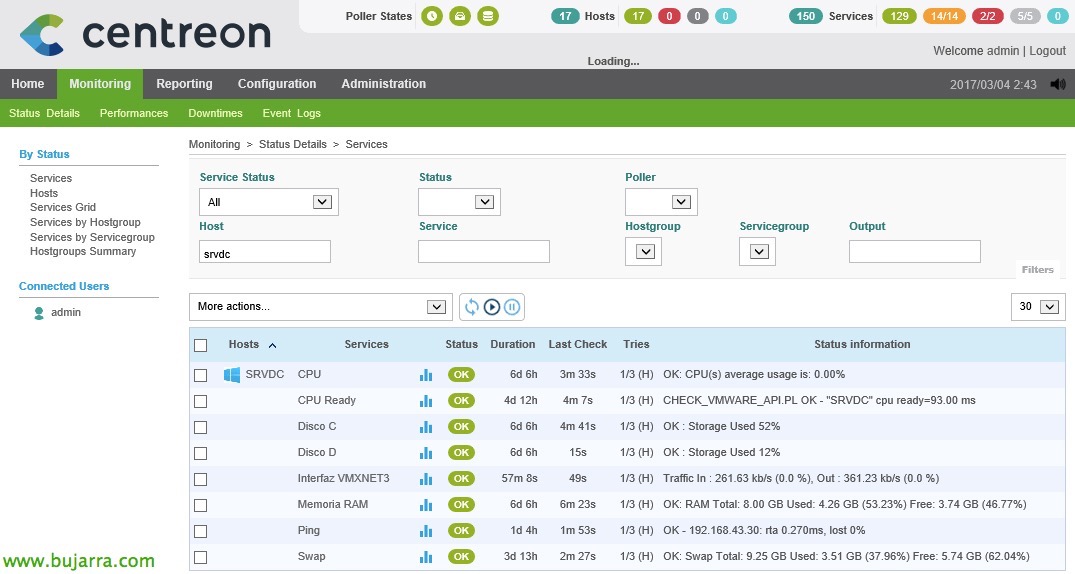
Nagios – Surveillance de nos hôtes ESXi

Dans ce document, nous allons examiner toutes les étapes nécessaires pour pouvoir surveiller un hôte ESXi, nous verrons les paramètres les plus courants et les valeurs que nous pouvons obtenir pour avoir un environnement contrôlé grâce à Nagios et Centreon! Toutes les informations que nous pouvons obtenir sont incroyables! Dans d’autres documents, nous verrons d’autres informations que nous pouvons obtenir de vCenter et de ses machines virtuelles, Aujourd’hui, les hôtes jouent!

Installation des exigences,
Nous allons d’abord commencer par installer toutes les conditions nécessaires pour utiliser l’un des scripts les plus courants que nous pouvons utiliser. Dans Bourse Nagios Nous serons en mesure d’obtenir presque tous les scripts dont nous avons besoin, et à partir de là, nous en téléchargerons un que j’utilise habituellement pour surveiller les hôtes ESXi 4.x, 5.x ou 6.x. Mais d’abord, nous devrons installer le SDK VMware sur la machine nagios ainsi que tout ce qui est nécessaire avant.
Après avoir installé et testé toutes les conditions requises, le script de surveillance des serveurs ESXi fonctionne, nous allons maintenant pouvoir quitter la console et utiliser l’interface Centreon pour créer les hôtes ESXi, les services que nous surveillerons et les commandes nécessaires. J’espère qu’il est bien compris, pour suivre les étapes!
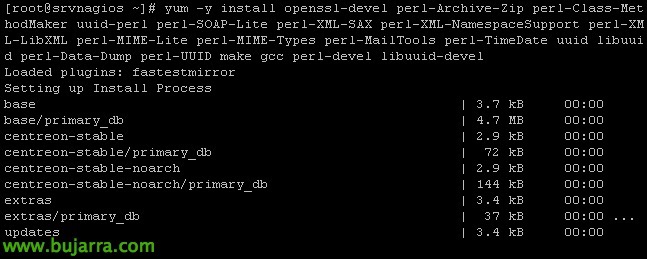
Installation des exigences:
[Code source]yum -y install openssl-devel perl-Archive-Zip perl-Class-MethodMaker uuid-perl perl-SOAP-Lite perl-XML-SAX perl-XML-NamespaceSupport perl-XML-LibXML perl-MIME-Lite perl-MIME-Lite perl-MIME-Types perl-MailTools perl-TimeDate uuid libuuid perl-Data-Dump perl-UUID make gcc perl-devel libuuid-devel cpan[/Code source]

Nous effectuons une recherche sur le site Web de téléchargement de VMware, le SDK vSphere pour Perl, Nous téléchargeons le package GZ à partir de 64 mors.

Nous le téléchargeons sur le serveur Nagios en utilisant WinSCP par exemple et le laissons dans le répertoire temporaire '/tmp/'. Nous le décompressons et l’installons:
[Code source]tar xvzf VMware-vSphere-Perl-SDK-xxxxxxx.tar.gz
cd vmware-vsphere-cli-distrib/
./vmware-install.pl[/Code source]

Nous l’installons avec les paramètres par défaut,

Et après quelques secondes, nous l’aurons installé,

Nous installons UUID:
[Code source]cd /usr/src
wget http://search.cpan.org/CPAN/authors/id/J/JN/JNH/UUID-0.04.tar.gz
tar -xzvf UUID-0.04.tar.gz -C /opt[/Code source]
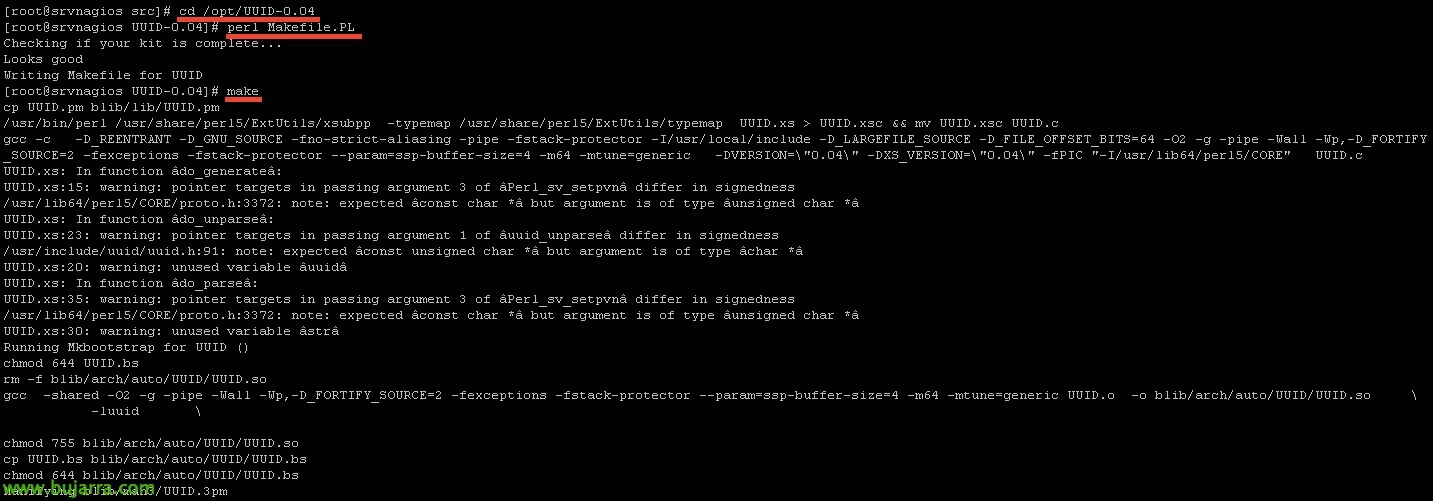
Nous le compilons:
[Code source]cd /opt/UUID-0.04
Perle Makefile.PL
faire[/Code source]

Et nous l’avons installé, ainsi que 'perl-Nagios-Plugin’ qui sera également nécessaire:
[Code source]make install
yum install perl-Nagios-Plugin[/Code source]
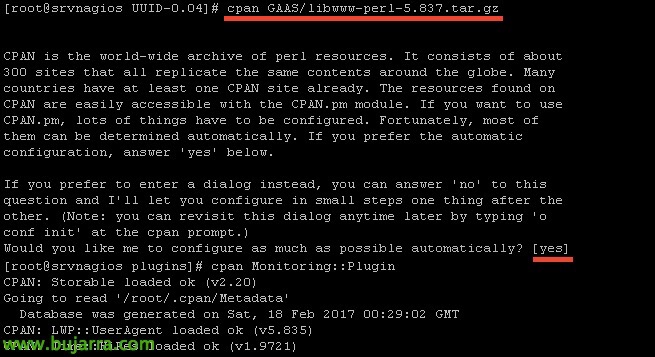
Nous installons plus d’exigences:
[Code source]CPAN GAAS/libwww-perl-5.837.tar.gz[/Code source]

Et nous en finissons avec ce dernier!
[Code source]Surveillance CPAN::Plugin[/Code source]

Finalement, Nous pourrons télécharger le script qui nous permettra d’obtenir des informations des hôtes ici https://exchange.nagios.org/directory/Plugins/Operating-Systems/*-Virtual-Environments/VMWare/check_vmware_api/details Une fois téléchargé, nous laisserons le fichier 'check_vmware_api.pl’ à '/usr/lib/centreon/plugins/’ Et nous le rendrons exécutable avec 'chmod +x check_vmware_api.pl'. Nous allons essayer de l’exécuter et si tout est correct, cet écran apparaîtra indiquant les options que nous pouvons utiliser.
Création d’un utilisateur privilégié dans ESXi,
Le script ci-dessus, devront être validés par rapport à l’hôte ESXi pour obtenir les informations qui nous intéressent, par conséquent, nous allons créer un utilisateur dans chaque ESXi et donner les autorisations nécessaires.

Dans chaque ESXi, après s’être bien connecté avec le client traditionnel ou le navigateur web, Nous irons dans la région de “Utilisateurs” Et nous en créerons un, Nous définirons également votre mot de passe.

Sur le “Autorisations”, Nous allons ajouter cet utilisateur à autant de portée que possible, et nous l’ajouterons avec le rôle 'Read-Only'.
Maintenant, Nous allons créer dans l’annuaire qui nous intéresse (Je le laisse dans les mêmes plugins) un fichier, où nous stockerons le nom d’utilisateur et le mot de passe que la commande utilisera pour se valider lorsqu’elle effectuera les vérifications. Dans cet exemple, je l’enregistre dans '/usr/lib/centreon/plugins/check_vmware_api.auth’ au format suivant:
[Code source]username=utilisateur
password=Mot de passe[/Code source]

Et nous pouvons déjà exécuter n’importe quelle vérification sur un hôte ESXi, Quelque chose de simple à essayer, Utilisation du processeur:
[Code source]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l cpu -s utilisation -w 80 -c 90[/Code source]
Les paramètres qui accompagnent la commande sont tous décrits ci-dessous, Dans la commande précédente '-w’ sera le % Avertissement lors de l’avertissement et de '-c’ la valeur de quand il est Critique. Je vous dis cela parce que c’est commun à presque toutes les commandes, et tous ceux qui utilisent ceux que nous voulons, Dans ces documents, vous constaterez que normalement, lorsque vous atteignez le 80% sera quelque chose d’avertissement et quand il atteint le 90% sera Critique.
Il ne reste plus qu’à choisir les éléments qui nous intéressent le plus à surveiller, À la fin du document, je mettrai toutes les possibilités que nous offre cette excellente commande 'check_vmware_api.pl'. Mais pour l’instant, je vous donne les exemples les plus courants pour surveiller les informations d’un hôte ESXi:
Utilisation de la RAM:
[Code source]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l mem -s usage -w 80 -c 90[/Code source]
Utilisation de la mémoire d’échange
[Code source]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l mem -s swap -w 1 -c 10[/Code source]
Utilisation de la mémoire balloning
[Code source]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l mem -s memctl -w 1 -c 10[/Code source]
Utilisation du réseau
[Code source]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l net -s utilisation -w 10240 -c 102400[/Code source]
Détecter si nous avons une carte réseau tombée,
[Code source]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l net -s nic -w 1 -c 2[/Code source]
Surveiller les banques de données VMFS, dans ce, La commande renvoie l’utilisation libre, nous indiquerons donc avec le format suivant en Avertissement et Critique l’élément % de dédouanement,
[Code source]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l vmfs -s -s LUN04 -w 10%: -c 5%:[/Code source]
Par exemple avec le paramètre 'runtime'’ Nous allons voir un aperçu du serveur, Et en option, nous pouvons ajouter d’autres options telles que 'santé'’ pour voir la santé, « Température’ Pour afficher les capteurs de température, ou 'status’ pour voir un résumé parmi d’autres.
[Code source]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime -s santé
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime -s température
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l runtime -s état[/Code source]
Si nous utilisons le paramètre 'service’ nous pourrons voir l’état de tous les services ESXi, qu’ils soient en cours d’exécution ou non, Et en plus, nous pouvons ajouter le nom des services que nous souhaitons surveiller uniquement.
[Code source]./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l service
./check_vmware_api.pl -H SERVIDOR_ESXI -f check_vmware_api.auth -l service -s DCUI vpxa[/Code source]
Pour l’instant, je pense que cela nous suffit, Non? Depuis le script 'check_vmware_api.pl’ Il y a encore beaucoup plus de choses que vous pouvez parcourir et que nous verrons dans d’autres articles, il serait également utile de surveiller les clusters d’hôtes, Centres de données, Machines virtuelles, etc… Un autre jour ;), Maintenant, nous continuons avec les hôtes!
Création d’un hôte,
Ici, nous allons enfin enregistrer dans Nagios notre premier serveur, un hôte ESXi! Nous utiliserons Centreon pour faciliter tout le travail.
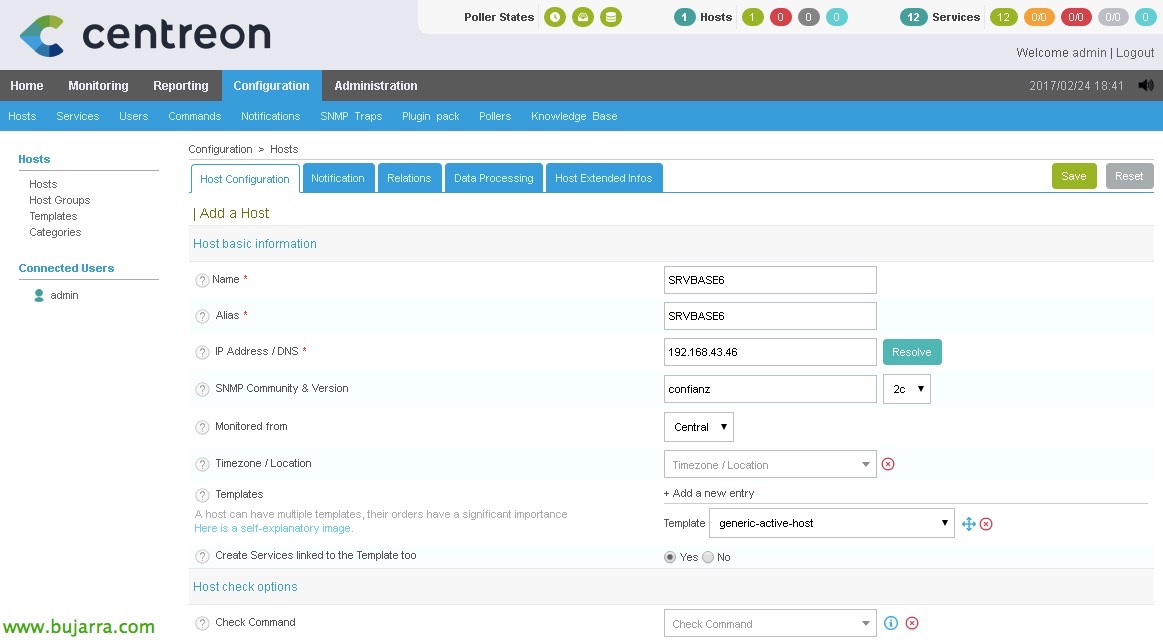
Depuis “Configuration” > “Hôtes” > “Ajouter”, Nous allons ajouter notre premier serveur, Nous remplirons au moins les champs suivants:
- Nom: Nom du serveur.
- Alias: Alias de serveur.
- Adresse IP / DNS: L’adresse IP ou le nom DNS du serveur.
- Communauté SNMP & Version: Dans ce cas, il ne serait pas nécessaire.
- Suivi à partir de: L’analyseur qui va surveiller cet hôte.
- Modèle: Sélectionnez 'generic-active-host'.
Création d’une commande,
Nous allons définir une commande dans Centreon à l’aide de variables pour pouvoir exécuter les commandes que nous avons vues précédemment, cette commande sera ensuite appelée à partir de chaque service que nous créons pour surveiller le processeur, BÉLIER… Quelle meilleure façon de le voir que de le 🙂 comprendre

J’aime généralement appeler la commande de la même manière que le script, donc, Dans ce cas, je vais créer la commande 'check_vmware_api.pl'. Pour ce faire,, depuis “Configuration” > “Commandes” > “Contrôles” > “Ajouter”. Nous indiquons qu’il s’agit d’une commande de type 'Check’ et dans la 'Ligne de commande que nous indiquons':
[Code source]$CENTREONPLUGINS$/check_vmware_api.pl -H $HOSTADDRESS$ -f $CENTREONPLUGINS$/check_vmware_api.auth -l $ARG 1$ -s $ARG 2$ -w $ARG 3$ -c $ARG 4$[/Code source]
- La variable $CENTREONPLUGINS$ est '/usr/lib/centreon/plugins/’
- La variable $HOSTADDRESS$ serait l’adresse IP ou le nom FQDN du serveur à surveiller.
- ARG1 serait le premier argument que nous vous transmettrons, si nous nous souvenons que c’est le 'Commandement’ indiqué après '-l'.
- ARG2 serait le premier argument que nous lui transmettrons,si nous nous souvenons qu’il s’agit du 'SubCommand’ indiqué après '-s'.
- ARG3 sera la valeur de Avertissement.
- ARG4 sera la valeur de Critical.
Cliquez sur “Décrire les arguments” donc je n’ai pas besoin de mémoriser et de le savoir.

Nous associons donc de manière simple ce qu’est chaque argument, que plus tard lorsque nous créons les services, Nous l’apprécierons. “Sauvegarder”.
Création des services,
Ici, nous pouvons enfin créer les services de ce que nous voulons surveiller, être CPU, BÉLIER, Cartes réseau perdues, État de la banque de données… pour cela, Nous nous soutiendrons les uns les autres comme nous l’avons dit dans le commandement que nous venons de créer! Regardez comme c’est facile:

Dans “Configuration” > “Services” > “Ajouter”, Nous allons créer notre premier service! Nous remplirons au moins les informations suivantes:
- Description: Nom du service, dans mon cas CPU, BÉLIER, Échanger la mémoire…
- Lié aux hôtes: Ici, nous allons ajouter l’hôte que nous avons créé auparavant, notre serveur ESXi.
- Modèle: Sélectionnez 'generic-active-service'.
- Vérifier la commande: Nous choisissons également la commande que nous avons créée précédemment, que dans mon cas, je l’appelle le script 'check_vmware_api.pl’
- Arguments: Nous devons remplir tous les arguments que le commandement nous demande de.
- Utilisation du processeur: CPU / usage / 80 / 90
- BÉLIER: Mem / usage / 80 / 90
- Échanger la mémoire: Mem / échanger / 1 / 10
- Mémoire de ballon: Mem / Memctl / 1/ 10
- État de la carte réseau: Filet / Nic / 1 / 2
- …
Nous enregistrons avec “Sauvegarder”,
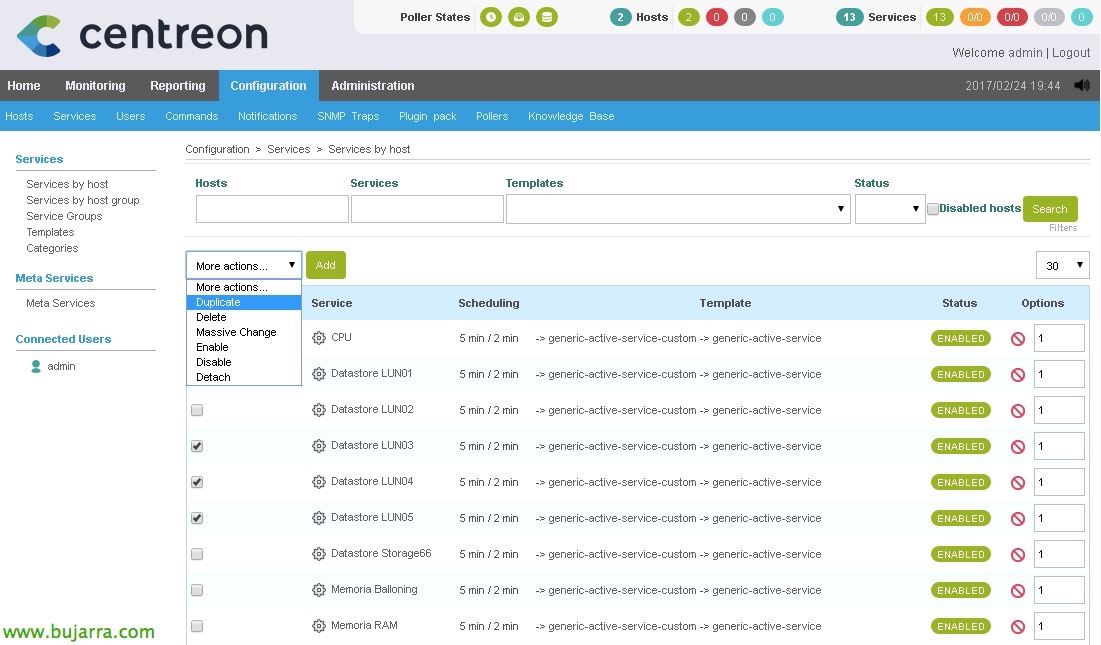
Pour créer le reste des services, au lieu de tous les créer à partir de zéro, Le plus confortable sera de les dupliquer, De cette façon, nous n’aurons qu’à modifier les arguments et il sera beaucoup plus facile de créer les services.
Une fois que nous avons créé tous les services associés à un hôte ESXi, si nous voulons maintenant dupliquer le travail effectué pour surveiller un autre hôte ESXi que nous avons, Ou autant que nous en avons, depuis “Configuration” > “Hôtes”, nous allons sélectionner l’ESXi que nous avons et le dupliquer, Avec cela, nous générons un nouvel hôte, auquel nous devrons changer le nom, Alias et adresse IP et nous aurons un autre hébergeur prêt avec les mêmes services!
Et rien, L’habituel, Une fois les travaux terminés, Nous enregistrons les modifications, Cenreon générera les fichiers nagios nécessaires, “Configuration” > “Sondages” > “Exporter la configuration”,

Nous sélectionnons notre sondeur, Nous marquons les coches et redémarrons & “Exportation”,
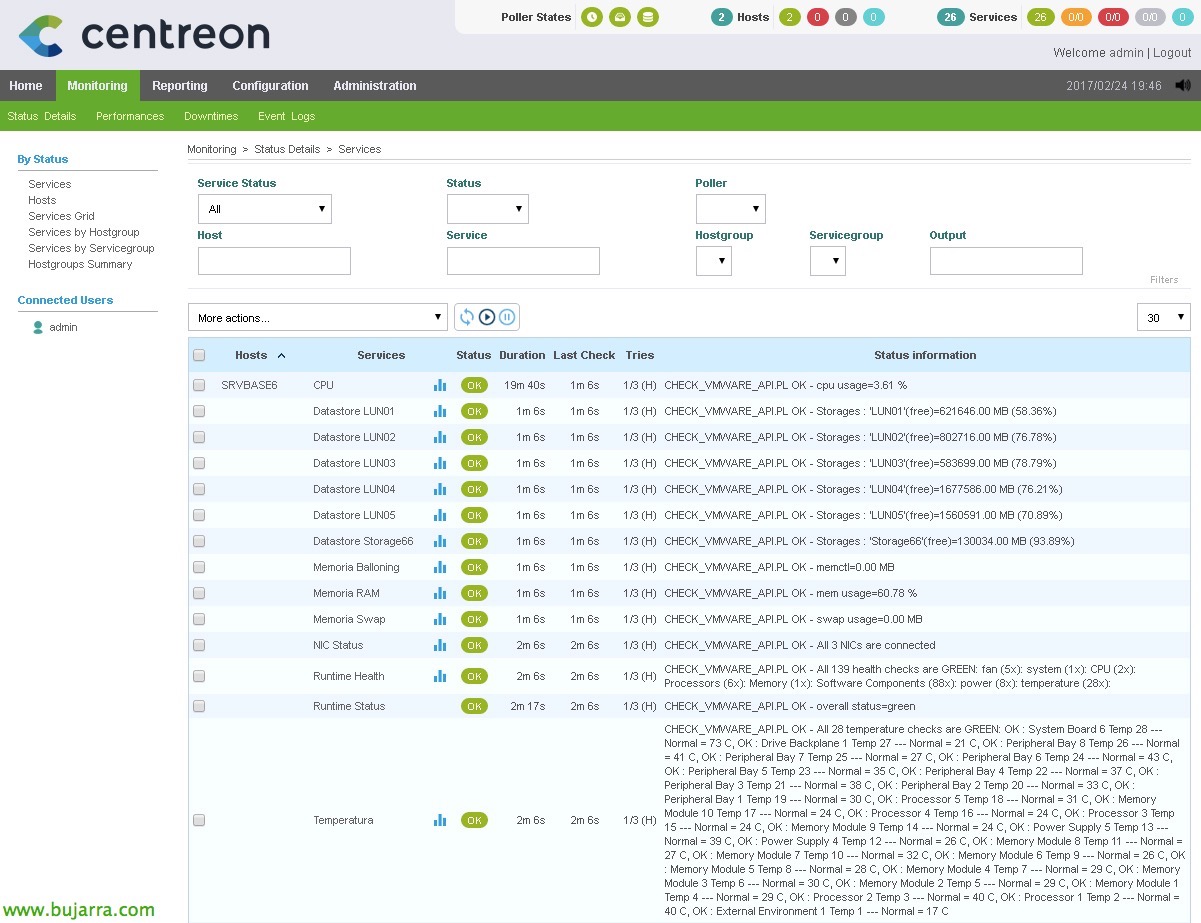
Une fois que tout est généré, Nous pouvons maintenant passer à la partie surveillance et vérifier que tout ce que nous avons fait fonctionne! Veremos todos los nuevos servicios que hemos creado que monitorizan distintas cosas. Si nous voulons forcer la vérification, Nous le savons déjà, seleccionamos los servicios que nos interesen y en el combo seleccionamos 'Services – Planifier une vérification immédiate (Forcé)’.
Y aquí os dejo todas las posibilidades del comando:
[Code source]Usage: check_vmware_api.pl -D <data_center> | -H <host_name> [ -C <cluster_name> ] [ -N <vm_name> ]
-ou <utilisateur> -p <Passer> | -f <fichier d’authentification>
-l <commander> [ -s <sous-commande> ] [ -T <décalage temporel> ] [ -Je <intervalle> ]
[ -x <black_list> ] [ -ou <additional_options> ]
[ -t <Timeout> ] [ -w <warn_range> ] [ -c <crit_range> ]
[ -V ] [ -h ]
-?, –usage
Imprimer les informations d’utilisation
-h, –Aide
Imprimer l’écran d’aide détaillé
-V, –Version
Imprimer les informations sur la version
–extra-opts=[section][@file]
Lire les options d’un fichier ini.
pour l’utilisation et les exemples.
-H, –hôte=<nom d’hôte>
Nom d’hôte ESX ou ESXi.
-C, –grappe=<nomducluster>
Nom du cluster ESX ou ESXi.
-D, –centre de données=<DCnom>
Nom d’hôte du centre de données.
-N, –nom=<vmname>
Nom de la machine virtuelle.
-ou, –nom d’utilisateur=<nom d’utilisateur>
Nom d’utilisateur avec lequel se connecter.
-p, –mot de passe=<mot de passe>
Mot de passe à utiliser avec le nom d’utilisateur.
-f, –fichierd’auth=<Chemin>
Fichier d’authentification avec login et mot de passe. Syntaxe du fichier :
nom d’utilisateur=<connectez-vous>
mot de passe=<mot de passe>
-w, –warning=SEUIL
Seuil d’avertissement. Voir
pour le format de seuil. Par défaut, aucun seuil n’est fixé.
-c, –critique=SEUIL
Seuil critique. Voir
pour le format de seuil. Par défaut, aucun seuil n’est fixé.
-l, –command=COMMANDE
Spécifier le type de commande (CPU, MEM, FILET, IO, VMFS, DUREE, …)
-s, –subcommand=SOUS-commande
Spécifier la sous-commande
-S, –sessionfile=FICHIER DE SESSION
Spécifiez un nom de fichier pour stocker les sessions afin d’accélérer l’authentification
-x, –exclude=<black_list>
Spécifier la liste noire
-ou, –options=<additional_options>
Spécifier des options de commande supplémentaires (Statistiques rapides, …)
-T, –horodatage=<décalage temporel>
Timeshift in seconds that could fix issues with "Unknown error". Utilisez des valeurs telles que 5, 10, 20, etc
-Je, –intervalle=<Période d’échantillonnage>
Période d’échantillonnage en secondes. Intervalles historiques de base: 300, 1800, 7200 ou 86400. Voir la configuration pour toute modification.
Prend en charge les valeurs littérales pour négocier automatiquement la valeur d’intervalle: r – intervalle en temps réel, h<nombre> – intervalle historique spécifié par la position.
La valeur par défaut est 20 (Temps réel). Étant donné que le cluster n’a pas d’intervalle de statistiques en temps réel autre que 20(Par défaut en temps réel) est obligatoire.
-M, –maxsamples=<Nombre maximal d’échantillons>
Nombre maximum d’échantillons à récupérer. Le nombre maximal d’échantillons est ignoré pour les intervalles historiques.
La valeur par défaut est 1 (Dernier échantillon disponible).
–trace=<niveau>
Définir le niveau de détail de la trace de demande/réponse de l’API vSphere
–generate_test=<lime>
Générez un script de cas de test à partir de la commande/sous-commande exécutée et écrivez-le dans <lime>. Si <lime> is "stdout", Le script de cas de test est écrit sur stdout à la place.
-t, –timeout=ENTIER
Quelques secondes avant l’expiration du plug-in (faire défaut: 30)
-v, –verbeux
Afficher les détails du débogage de ligne de commande (peut répéter jusqu’à 3 fois)
Commandes prises en charge(^ – Paramètre vide ou non spécifié, ou – Options, T – Valeur de décalage temporel, b – Liste noire) :
Spécifique à la machine virtuelle :
* CPU – Affiche les informations sur le processeur
+ usage – Utilisation du processeur en pourcentage
+ utilisationmhz – Utilisation du processeur en MHz
+ attendre – Temps d’attente du processeur en ms
+ prêt – Temps de disponibilité du processeur en ms
^ Toutes les informations sur le processeur(Aucun seuil)
* Mem – Affiche les infos sur le MEM
+ usage – Utilisation de MEM en pourcentage
+ UsageMB – Utilisation de mem en Mo
+ échanger – swap utilisation mem en Mo
+ swapin – swapin utilisation mem en Mo
+ Remplacement – swapout utilisation mem en Mo
+ frais généraux – mémoire supplémentaire utilisé par le serveur VM en Mo
+ total – mémoire globale utilisée par VM Server en Mo
+ actif – utilisation active de mem en Mo
+ Memctl – mem utilisé par le pilote de contrôle de la mémoire VM(vmmemctl) qui contrôle le ballonnement
^ Toutes les infos sur le mem(sauf dans l’ensemble et sans seuils)
* Filet – affiche les infos sur le net
+ usage – Utilisation globale du réseau en Ko/s(Kilo-octets par seconde)
+ recevoir – réception en Ko(Kilo-octets par seconde)
+ Envoyer – envoi en Ko(Kilo-octets par seconde)
^ Toutes les infos sur le Net(sauf utilisation et aucun seuil)
* Io – affiche les informations d’E/S du disque
+ usage – utilisation globale du disque en Mo/s
+ lire – utilisation du disque de lecture en Mo/s
+ écrire – utilisation du disque d’écriture en Mo/s
^ Toutes les informations sur les E/S du disque(Aucun seuil)
* Duree – Affiche les informations d’exécution
+ avec – État de la connexion
+ CPU – CPU allouée en MHz
+ Mem – mem alloué en MB
+ état – État de la machine virtuelle (ASI, En bas, SUSPENDU)
+ statut – État général de l’objet (gris/vert/rouge/jaune)
+ consoleconnexions – connexions de console à la machine virtuelle
+ Invités – état du système d’exploitation invité, a besoin d’outils VMware
+ outils – État des outils VMware
+ Questions – Tous les problèmes pour l’hôte
^ Toutes les informations d’exécution(sauf contre et aucun seuil)
Spécifique à l’hôte :
* CPU – Affiche les informations sur le processeur
+ usage – Utilisation du processeur en pourcentage
o Statistiques rapides – switch pour la requête soit les valeurs PerfCounter, soit les informations d’exécution
+ utilisationmhz – Utilisation du processeur en MHz
o Statistiques rapides – switch pour la requête soit les valeurs PerfCounter, soit les informations d’exécution
^ Toutes les informations sur le processeur
o Statistiques rapides – switch pour la requête soit les valeurs PerfCounter, soit les informations d’exécution
* Mem – Affiche les infos sur le MEM
+ usage – Utilisation de MEM en pourcentage
o Statistiques rapides – switch pour la requête soit les valeurs PerfCounter, soit les informations d’exécution
+ UsageMB – Utilisation de mem en Mo
o Statistiques rapides – switch pour la requête soit les valeurs PerfCounter, soit les informations d’exécution
+ échanger – swap utilisation mem en Mo
o listvm – activer/désactiver la liste de sortie des machines virtuelles d’échange
+ frais généraux – mémoire supplémentaire utilisé par le serveur VM en Mo
+ total – mémoire globale utilisée par VM Server en Mo
+ Memctl – mem utilisé par le pilote de contrôle de la mémoire VM(vmmemctl) qui contrôle le ballonnement
o listvm – activer/désactiver la liste de sortie des VM en monte
^ Toutes les infos sur le mem(sauf dans l’ensemble et sans seuils)
* Filet – affiche les infos sur le net
+ usage – Utilisation globale du réseau en Ko/s(Kilo-octets par seconde)
+ recevoir – réception en Ko(Kilo-octets par seconde)
+ Envoyer – envoi en Ko(Kilo-octets par seconde)
+ Nic – s’assure que toutes les cartes réseau actives sont branchées
^ Toutes les infos sur le Net(sauf utilisation et aucun seuil)
* Io – Affiche les informations d’E/S du disque
+ avorté – Nombre de commandes abandonnées
+ Réinitialise – Nombre de réinitialisations de bus
+ lire – Latence de lecture en ms (totalReadLatency.average)
+ écrire – Latence d’écriture en ms (totalWriteLatency.average)
+ noyau – Latence du noyau en ms
+ appareil – Latence de l’appareil en ms
+ queue – Latence de la file d’attente en ms
^ Toutes les informations sur les E/S du disque
* VMFS – affiche les informations sur la banque de données
+ (Nom) – Informations sur l’espace libre pour la banque de données avec nom (Nom)
o utilisé – sortie espace utilisé au lieu de libre
o bref – Répertorier uniquement les volumes d’alerte
o expression rationnelle – S’il faut traiter le nom comme une expression rationnelle
o liste noireregexp – S’il faut traiter la liste noire comme une expression régulière
b – liste noire des VMFS
T (valeur) – timeshift pour déterminer si nous avons besoin de rafraîchir
^ Toutes les informations sur la banque de données
o utilisé – sortie espace utilisé au lieu de libre
o bref – Répertorier uniquement les volumes d’alerte
o liste noireregexp – S’il faut traiter la liste noire comme une expression régulière
b – liste noire des VMFS
T (valeur) – timeshift pour déterminer si nous avons besoin de rafraîchir
* Duree – Affiche les informations d’exécution
+ avec – État de la connexion
+ Santé – Vérifie l’état du processeur/du stockage/de la mémoire/du capteur et propage l’état le plus défavorable
o listitems – Énumérer tous les capteurs disponibles(à utiliser uniquement à des fins de mise en vente)
o blackregexpflag – S’il faut traiter la liste noire comme une expression régulière
b – Liste noire des objets d’état
+ stockagesanté – Vérification de l’état du stockage
o blackregexpflag – S’il faut traiter la liste noire comme une expression régulière
b – Liste noire des objets d’état
+ température – Capteurs de température
o blackregexpflag – S’il faut traiter la liste noire comme une expression régulière
b – Liste noire des objets d’état
+ capteur – capteur de seuil spécifié
+ entretien – Indique si l’hôte est en mode maintenance
o maintwarn – Définit l’état d’avertissement lorsque l’hôte est en mode de maintenance
o maintcrit – Définit l’état critique lorsque l’hôte est en mode de maintenance
+ liste(Vm) – liste des machines VMware et leurs états
+ statut – État général de l’objet (gris/vert/rouge/jaune)
+ Questions – Tous les problèmes pour l’hôte
b – Problèmes de liste noire
^ Toutes les informations d’exécution(Santé, stockagesanté, La température et le capteur sont représentés par une seule valeur et aucun seuil)
* service – affiche les informations sur le service hôte
+ (prénoms) – vérifier l’état d’un ou plusieurs services spécifiés par (prénoms), syntaxe pour (prénoms):<Service après-vente1>,<service2>,…,<serviceN>
^ Voir tous les services
* stockage – affiche les informations de stockage de l’hôte
+ adaptateur – Adaptateurs de bus de liste
b – Adaptateurs de liste noire
+ LUN – liste des unités logiques SCSI
b – liste noire des LUN
+ Chemin – Liste des chemins d’accès aux unités logiques
b – mettre en liste noire les chemins d’accès
^ Afficher toutes les informations de stockage
* Disponibilité – affiche la disponibilité de l’hôte
o Statistiques rapides – switch pour la requête soit les valeurs PerfCounter, soit les informations d’exécution
* appareil – affiche des informations spécifiques à l’appareil de l’hôte
+ CD/DVD – Répertorier les machines virtuelles avec lecteurs de CD/DVD connectés
o listall – Répertorier tous les appareils disponibles(à utiliser uniquement à des fins de mise en vente)
Spécifique à DC :
* CPU – Affiche les informations sur le processeur
+ usage – Utilisation du processeur en pourcentage
o Statistiques rapides – switch pour la requête soit les valeurs PerfCounter, soit les informations d’exécution
+ utilisationmhz – Utilisation du processeur en MHz
o Statistiques rapides – switch pour la requête soit les valeurs PerfCounter, soit les informations d’exécution
^ Toutes les informations sur le processeur
o Statistiques rapides – switch pour la requête soit les valeurs PerfCounter, soit les informations d’exécution
* Mem – Affiche les infos sur le MEM
+ usage – Utilisation de MEM en pourcentage
o Statistiques rapides – switch pour la requête soit les valeurs PerfCounter, soit les informations d’exécution
+ UsageMB – Utilisation de mem en Mo
o Statistiques rapides – switch pour la requête soit les valeurs PerfCounter, soit les informations d’exécution
+ échanger – swap utilisation mem en Mo
+ frais généraux – mémoire supplémentaire utilisé par le serveur VM en Mo
+ total – mémoire globale utilisée par VM Server en Mo
+ Memctl – mem utilisé par le pilote de contrôle de la mémoire VM(vmmemctl) qui contrôle le ballonnement
^ Toutes les infos sur le mem(sauf dans l’ensemble et sans seuils)
* Filet – affiche les infos sur le net
+ usage – Utilisation globale du réseau en Ko/s(Kilo-octets par seconde)
+ recevoir – réception en Ko(Kilo-octets par seconde)
+ Envoyer – envoi en Ko(Kilo-octets par seconde)
^ Toutes les infos sur le Net(sauf utilisation et aucun seuil)
* Io – Affiche les informations d’E/S du disque
+ avorté – Nombre de commandes abandonnées
+ Réinitialise – Nombre de réinitialisations de bus
+ lire – Latence de lecture en ms (totalReadLatency.average)
+ écrire – Latence d’écriture en ms (totalWriteLatency.average)
+ noyau – Latence du noyau en ms
+ appareil – Latence de l’appareil en ms
+ queue – Latence de la file d’attente en ms
^ Toutes les informations sur les E/S du disque
* VMFS – affiche les informations sur la banque de données
+ (Nom) – Informations sur l’espace libre pour la banque de données avec nom (Nom)
o utilisé – sortie espace utilisé au lieu de libre
o bref – Répertorier uniquement les volumes d’alerte
o expression rationnelle – S’il faut traiter le nom comme une expression rationnelle
o liste noireregexp – S’il faut traiter la liste noire comme une expression régulière
b – liste noire des VMFS
T (valeur) – timeshift pour déterminer si nous avons besoin de rafraîchir
^ Toutes les informations sur la banque de données
o utilisé – sortie espace utilisé au lieu de libre
o bref – Répertorier uniquement les volumes d’alerte
o liste noireregexp – S’il faut traiter la liste noire comme une expression régulière
b – liste noire des VMFS
T (valeur) – timeshift pour déterminer si nous avons besoin de rafraîchir
* Duree – Affiche les informations d’exécution
+ liste(Vm) – liste des machines VMware et leurs états
+ listhost – liste des serveurs hôtes VMware esx et leurs états
+ listcluster – liste des clusters VMware et leurs états
+ outils – État des outils VMware
b – mettre sur liste noire les VM
+ statut – État général de l’objet (gris/vert/rouge/jaune)
+ Questions – Tous les problèmes pour l’hôte
b – Problèmes de liste noire
^ Toutes les informations d’exécution(à l’exception du cluster et des outils et pas de seuils)
* Recommandations – Affiche des recommandations pour le cluster
+ (Nom) – Recommandations pour le cluster avec nom (Nom)
^ Toutes les recommandations de clusters
Spécifique au cluster :
* CPU – Affiche les informations sur le processeur
+ usage – Utilisation du processeur en pourcentage
+ utilisationmhz – Utilisation du processeur en MHz
^ Toutes les informations sur le processeur
* Mem – Affiche les infos sur le MEM
+ usage – Utilisation de MEM en pourcentage
+ UsageMB – Utilisation de mem en Mo
+ échanger – swap utilisation mem en Mo
o listvm – activer/désactiver la liste de sortie des machines virtuelles d’échange
+ Memctl – mem utilisé par le pilote de contrôle de la mémoire VM(vmmemctl) qui contrôle le ballonnement
o listvm – activer/désactiver la liste de sortie des VM en monte
^ Toutes les infos sur le mem(plus frais généraux et aucun seuil)
* Grappe – Affiche les informations sur les services de cluster
+ EfficaceCPU – Ressources CPU totales disponibles de tous les hôtes du cluster
+ effectmem – Quantité totale de mémoire machine de tous les hôtes du cluster
+ basculement – Nombre de défaillances de VMware HA tolérées
+ cpufairness – Équité de l’allocation des ressources CPU distribuées
+ memfairness – Équité de l’allocation des ressources MEM distribuées
^ Seules les valeurs EffectiveCPU et EffectiveMem pour les services de cluster
* Duree – Affiche les informations d’exécution
+ liste(Vm) – liste des machines VMware dans le cluster et leurs états
+ listhost – liste des serveurs hôtes VMware esx dans le cluster et leurs statuts
+ statut – État général du cluster (gris/vert/rouge/jaune)
+ Questions – Tous les enjeux du cluster
b – Problèmes de liste noire
^ Toutes les informations d’exécution du cluster
* VMFS – affiche les informations sur la banque de données
+ (Nom) – Informations sur l’espace libre pour la banque de données avec nom (Nom)
o utilisé – sortie espace utilisé au lieu de libre
o bref – Répertorier uniquement les volumes d’alerte
o expression rationnelle – S’il faut traiter le nom comme une expression rationnelle
o liste noireregexp – S’il faut traiter la liste noire comme une expression régulière
b – liste noire des VMFS
T (valeur) – timeshift pour déterminer si nous avons besoin de rafraîchir
^ Toutes les informations sur la banque de données
o utilisé – sortie espace utilisé au lieu de libre
o bref – Répertorier uniquement les volumes d’alerte
o liste noireregexp – S’il faut traiter la liste noire comme une expression régulière
b – liste noire des VMFS
T (valeur) – timeshift pour déterminer si nous avons besoin de rafraîchir[/Code source]