Collecte des Synology LOG dans Elasticsearch et visualisation dans Grafana

Puits, Un autre article concerne la collecte de journaux et leur visualisation pour comprendre ce qui se passe dans notre infrastructure, aujourd’hui, nous avons un document où nous allons voir comment envoyer les Logs d’un Synology à notre Logstash, puis les stocker dans Elasticsearch et enfin les visualiser avec Grafana.
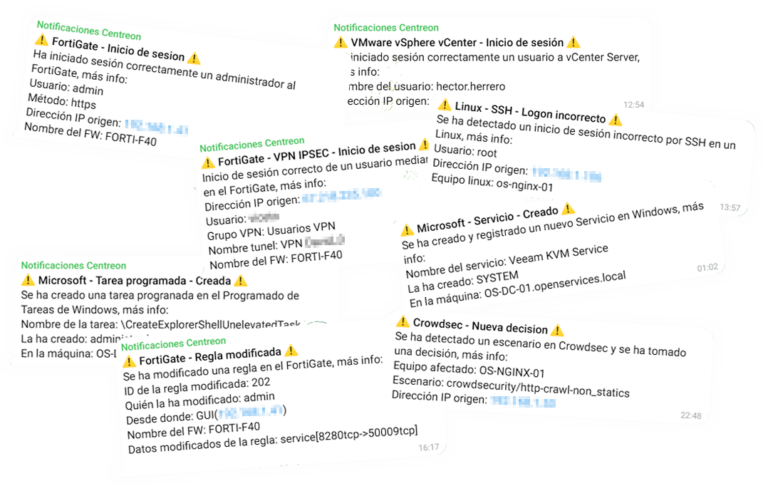
Ainsi, Canne au singe qui est en caoutchouc! (Je suis si vieux, Yaourt…) va! Si nous avons un NAS du fabricant Synology et que nous voulons savoir ce qui s’y passe, Le mieux est de toujours se jeter dans les bûches, Mais c’est un peu ennuyeux de lire des lignes et des lignes de texte, qui ne vont pas toujours en temps réel, que nous trouvons difficile à comprendre… Eh bien, c’est ce que (et d’autres choses) nous avons la Suite Elastic, où Synology enverra les journaux à Logstash, Là, nous les recevrons et les traiterons, en séparant les informations qui nous intéressent en différents champs, puis en les stockant dans Elasticsearch. Pour visualiser les données, nous pouvons toujours utiliser Kibana, mais je suis plus fan de Grafana, Je suis désolé, Donc, quel que soit le choix dont il s’agit, Vous pourrez visualiser ces données collectées sous différents formats, dans les tableaux, Graphique, Fromages, Carte du monde… c’est ainsi que vous allez interpréter ce qui se passe dans Synology, qui y accède ou tente de le faire, et ce qu’il fait… Vous pourrez le voir comme d’habitude, en temps réel ou en mode historique pour effectuer des requêtes. Commencé!
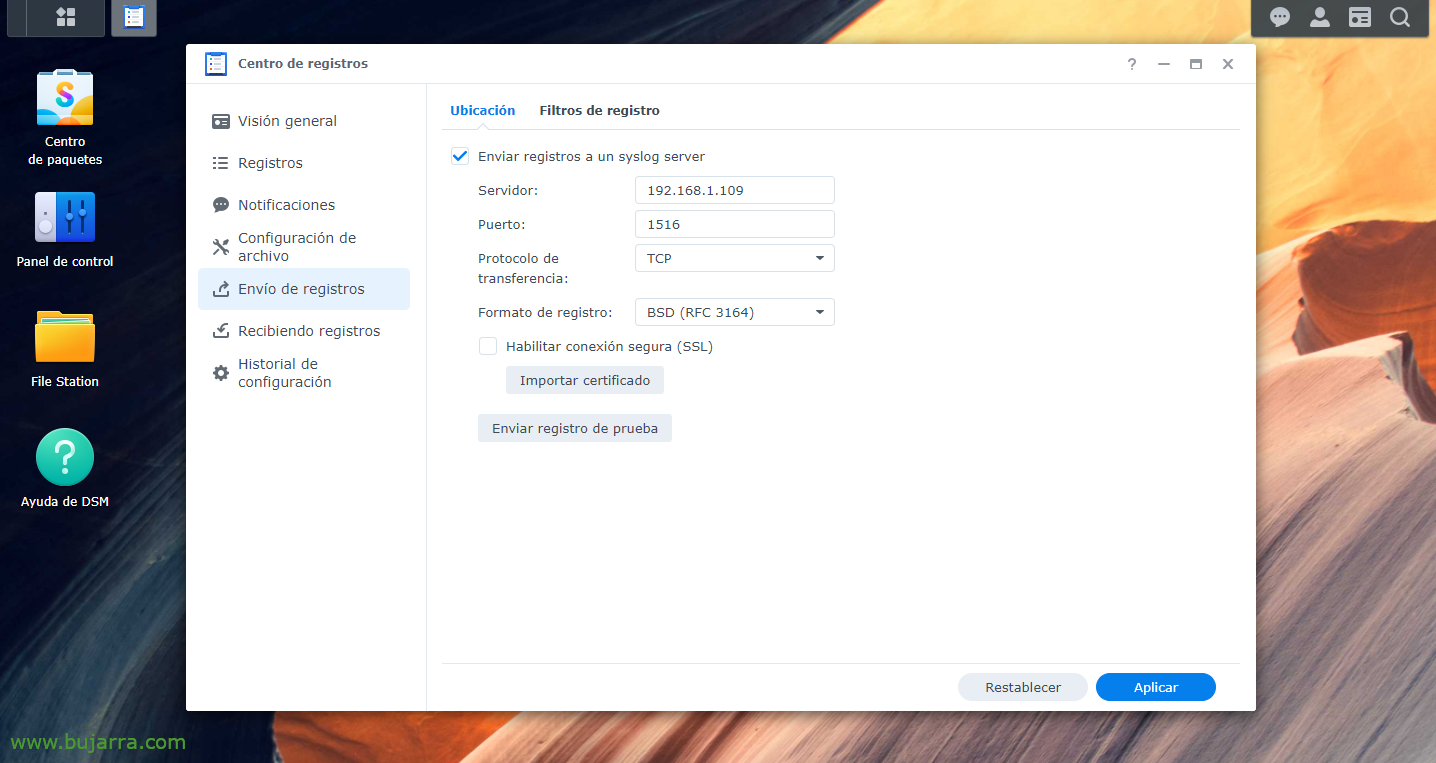
Tout d’abord, nous devons évidemment faire installer la partie Elastic Stack, Ce qui a étéLogstash, Recherche élastique etKibana; il s’agirait alors de demander à notre Synology d’envoyer les journaux à Logstash, vers le port de notre choix, Nous allons en inventer un, de la “Centre des enregistrements" > “Envoi de journaux” > Nous permettons “Envoi de journaux à un serveur syslog”, nous indiquons l’IP Logstash et le port et TCP ou UDP de votre choix. Et nous appliquons les modifications.
Entrée {
TCP {
type => "Synologie"
port => "1516"
Mots-clés => ["Synologie"]
}
}
filtre {
si [type] == "Synologie" {
Grok {
match => { "Message" => [
"^<%{POSINT:syslog_pri}>%{SYSLOGTIMESTAMP:syslog_timestamp} %{NOM D’HÔTE:host_title} Événement WinFileService: %{MOT:Action}, Chemin: %{GREEDYDATA:Chemin}, Fichier/Dossier: %{MOT:path_type}, Taille: %{BASE10NUM:file_size} %{MOT:file_size_unit}, Utilisateur: %{NOM D’UTILISATEUR:nom d’utilisateur}, IP: %{IP:src_ip}",
"^<%{POSINT:syslog_pri}>%{SYSLOGTIMESTAMP:syslog_timestamp} %{NOM D’HÔTE:host_title} Connexion: Utilisateur \[%{NOM D’UTILISATEUR:nom d’utilisateur}\] De \[%{NOM D’HÔTE:Équipe}\(%{IP:src_ip}\)\] Via \[%{DATE:Protocole}\] %{GREEDYDATA:Message} \[%{DATE:shared_folder}\]",
"^<%{POSINT:syslog_pri}>%{SYSLOGTIMESTAMP:syslog_timestamp} %{NOM D’HÔTE:host_title} Connexion: Utilisateur \[(%{NOM D’UTILISATEUR:nom d’utilisateur})?\] De \[%{IP:src_ip}\] %{GREEDYDATA:Message}",
"^<%{POSINT:syslog_pri}>%{SYSLOGTIMESTAMP:syslog_timestamp} %{NOM D’HÔTE:host_title} Connexion[%{INT:Id_proc}\]: SYSTÈME: %{GREEDYDATA:Message}",
"^<%{POSINT:syslog_pri}>%{SYSLOGTIMESTAMP:syslog_timestamp} %{NOM D’HÔTE:host_title} Système %{NOM D’UTILISATEUR:nom d’utilisateur}: %{GREEDYDATA:Message}"
]
}
}
}
}
sortie {
si ([type]=="Synologie"){
Recherche élastique {
indice => "Synologie-%{+AAAA. MM.jj}"
hôtes=> "DIRECCION_IP_ELASTICSEARCH:9200"
}
}
}
Maintenant, nous allons à notre Logstash, Et là, nous pouvons créer des filtres pour séparer les différents champs des différents journaux que nous recevons. Comme toujours améliorable, mais ces groks seront bons pour nous au moins pour un Synology DSM avec une version 7.0. Nous avons donc créé un fichier de configuration, Par exemple '/etc/logstash/conf.d/synology.conf’ Et avec ce contenu, nous ferons quelque chose.

Une fois le fichier de configuration créé, n’oubliez pas de redémarrer le service Logstash pour recharger. Après comme toujours, nous irons sur Kibana et une fois que les données arriveront, nous pourrons aller dans « Gestion » > « Gestion de la pile » > « Kibana » > « Modèles d’indice » > « Create index pattern » pour créer le modèle d’index, Comme je l’ai dit, comme d'habitude (dans ce cas et sans les guillemets) 'synology-*' et nous aurons les données déjà stockées correctement dans Elasticsearch. Maintenant, nous pouvions nous connecter à partir de “Analytique” > « Découvrez » notre index Synology et visualisez qu’il collecte des données.

Et puis, après la création de l’index dans Kibana, maintenant, dans notre Grafana, nous devons créer une « Source de données » qui pointe contre notre Elasticsearch et l’index Synology. Ensuite, il s’agit de laisser libre cours à votre imagination, créer un tableau de bord avec différents tableaux de bord, avec différentes données à visualiser, Une question de style Sankey pour afficher les adresses IP d’origine/de destination et le trafic envoyé, au format colonne, danspat pour afficher des données spécifiques, par exemple les identifiants corrects, Incorrect, Les connexions, Les fichiers créés, Modifier, Éliminer, les utilisateurs qui effectuent l’action...