
Supervision du SLA des hôtes dans Centreon

Nous utiliserons ce document pour en savoir plus sur le % disponibilité des machines surveillées chez Centreon. Si nous avons un SLA (Accord de niveau de service) Ce qu’il faut respecter, nous pourrons le mesurer depuis Centreon et nous alerter. Oh, et si vous utilisez Grafana, nous le verrons aussi à partir de là!
Ce que j’ai dit, à la fin de cet article, vous saurez comment mesurer le SLA offert par chaque machine que vous avez surveillée, nous associerons un Service à chaque Hôte Centreon afin de connaître la disponibilité offerte par ladite machine. De cette façon, vous aurez également leur historique et si vous êtes intéressé, vous pourriez recevoir des alertes lorsque le % est inférieure à la valeur qui vous intéresse. Et à la fin, cela, si vous utilisez Grafana pour visualiser votre monitoring Centreon, Je vais vous dire comment je visualise ces données, au cas où cela vous apporterait quelque chose 🙂
D’ailleurs, Vous êtes toujours intéressé, dans Cet article Nous avons vu quelque chose de similaire, nous avons vu comment obtenir le SLA de Centreon Services. Aujourd’hui, les hôtes jouent.
Afin de mesurer le SLA, nous devrons consulter la base de données de Centreon, qui est basé sur MariaDB (ou MySQL), Donc, si vous ne l’avez pas, Avant d’avoir besoin Revoir cet article pour pouvoir interroger n’importe quelle base de données MySQL.
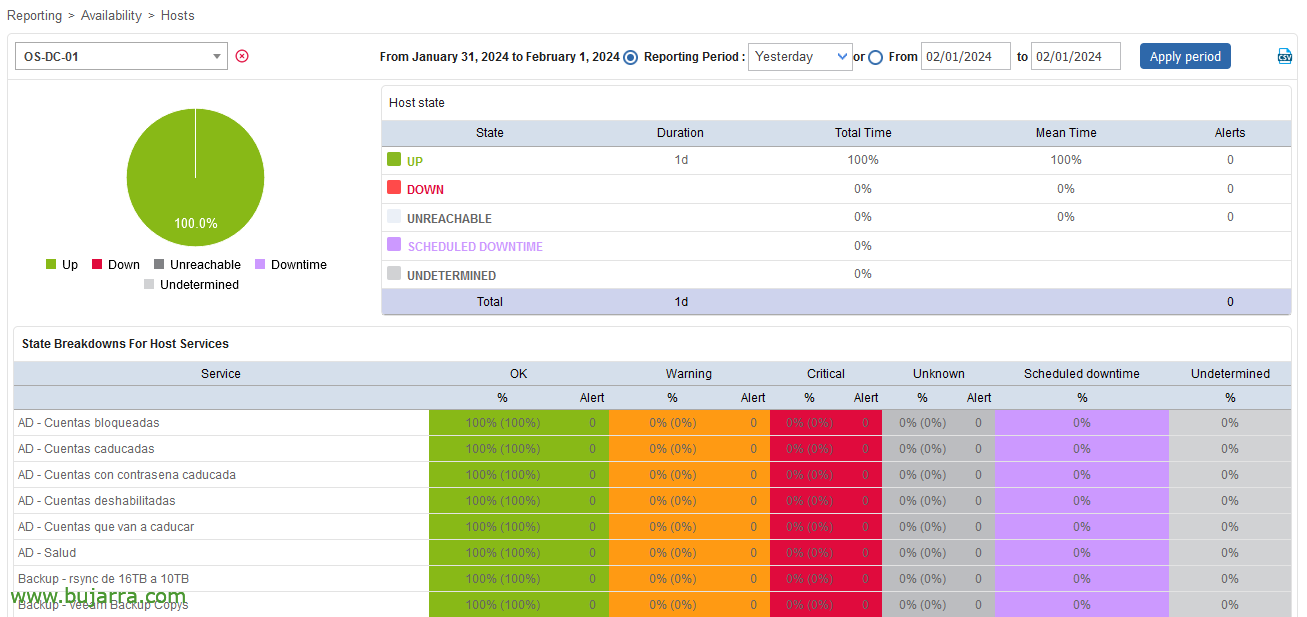
De toute façon, n’oubliez pas que dans Centreon, le SLA peut être visualisé par l’interface graphique à partir de “Rapports” > “Disponibilité” > “Hôtes”. Nous obtiendrons ces mêmes valeurs, Mais nous les surveillerons, C’est ce qui est important!

Commencé! Comme toujours, nous commencerons par le Commandement, une fois que nous définissons cette première commande, Nous pouvons l’utiliser autant de fois que nous le souhaitons. Plus précisément, cette commande nous donnera la commande % qu’une machine a été à l’état OK, le % de temps qui a été bon. Comme arguments qu’il porte (Je) les jours où vous souhaitez revenir pour calculer le SLA, 1 jour, 7 Jours, 30 Jours, 365 Jours… (Ii) Le nom de la machine, que j’aurais vraiment pu le prendre avec une variable Centreon et ne pas demander, (Iii) la valeur souhaitée de Warning, et (Iv) celui de Critical, Pour que je vous alerte, Une valeur inférieure à ces valeurs sera considérée comme une alerte. Je vous laisse le Commandement:
$CENTREONPLUGINS$/Nagios-Plugins/check_mysql_query.pl -q "SÉLECTIONNER ROND((SOMME(UPTimeProgrammé)/($ARG1$ * 86400))*100,2) en pourcentage DES hôtes, log_archive_host OÙ log_archive_host.host_id = hosts.host_id ET hosts.name = '$ARG 2$' ET from_unixtime(date_end) > date_sub(Maintenant(), INTERVALLE $ARG 1$ jour) commande PAR date_end DESC" -H DIRECCION_IP_CENTREON_CENTRAL -d centreon_storage -u 'USUARIO_MYSQL' -p 'CONTRASEÑA_MYSQL' -t 60 --no-querytime -g -l 'SLA' -U % -w $ARG 3$: -c $ARG 4 $: -m 'El SLA es del' -n
Si au lieu de % Vous voulez voir depuis combien de temps il est en place, Nous pouvons changer la requête en quelque chose comme ceci:
$CENTREONPLUGINS$/Nagios-Plugins/check_mysql_query.pl -q "SÉLECTIONNER CONCAT(SOL(HEURE(sec_to_time(SOMME(UPTimeProgrammé))) / 24), 'd_', MOD(HEURE(sec_to_time(SOMME(UPTimeProgrammé))), 24), 'h_', MINUTE(sec_to_time(SOMME(UPTimeProgrammé))), 'm') AS Tiempo FROM hôtes, log_archive_host OÙ log_archive_host.host_id = hosts.host_id ET hosts.name = '$ARG 2$' ET from_unixtime(date_end) > date_sub(Maintenant(), INTERVALLE $ARG 1$ jour) commande PAR date_end DESC" -H DIRECCION_IP_CENTREON_CENTRAL -d centreon_storage -u 'USUARIO_MYSQL' -p 'CONTRASEÑA_MYSQL' -t 60 --no-querytime -T -g -l 'SLA'
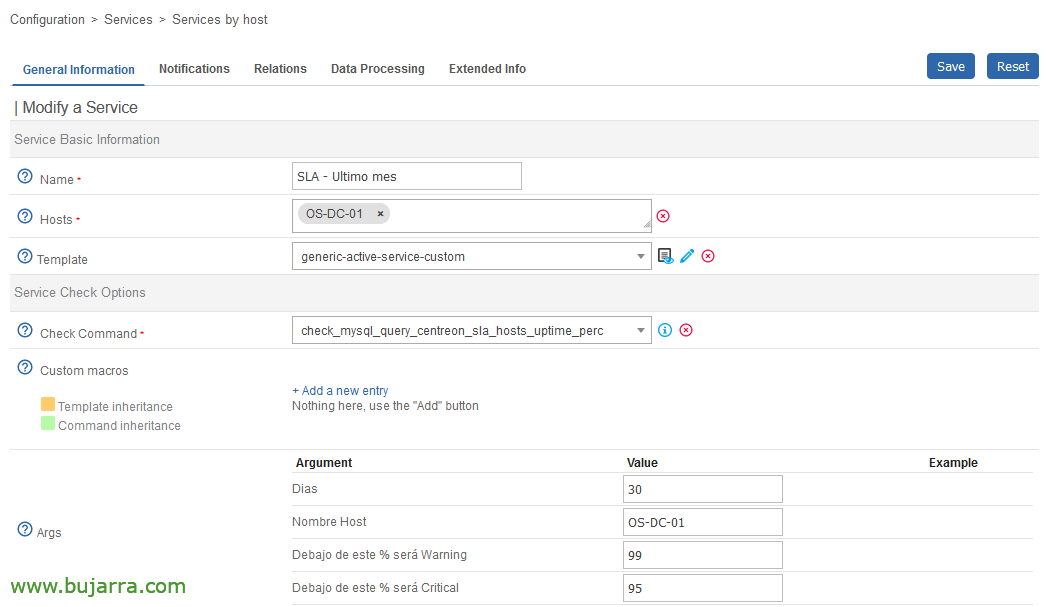
Une fois la commande créée, nous avons déjà pu créer autant de Services que nous en avons besoin et les associer à nos Hôtes, cet exemple nous montrera le SLA du dernier mois de cette machine, nous avertira lorsque le SLA est inférieur à 99% et enverra un message critique lorsqu’il est inférieur à 95%.
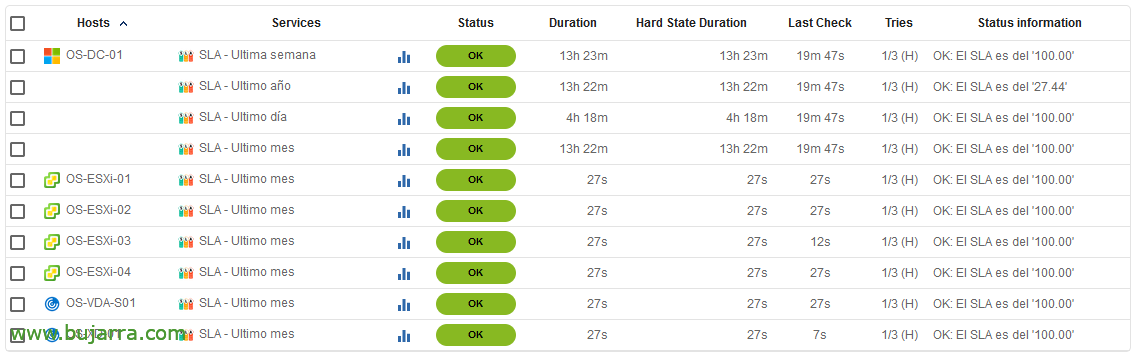
Après l’enregistrement et l’exportation de vos paramètres Centreon, Nous pourrons voir les résultats. En un instant, nous pouvons contrôler le SLA de chaque appareil, Mesurez-la et améliorez-la, ou utilisez-le sur demande. Gardez à l’esprit que ce script ne doit pas être exécuté avant 6 heures du matin car Centreon en interne dans la base de données n’a pas généré les données de ce jour-là et peut nous donner des informations quelque peu falsifiées, La meilleure chose à faire est donc d’y mettre un programme particulier.
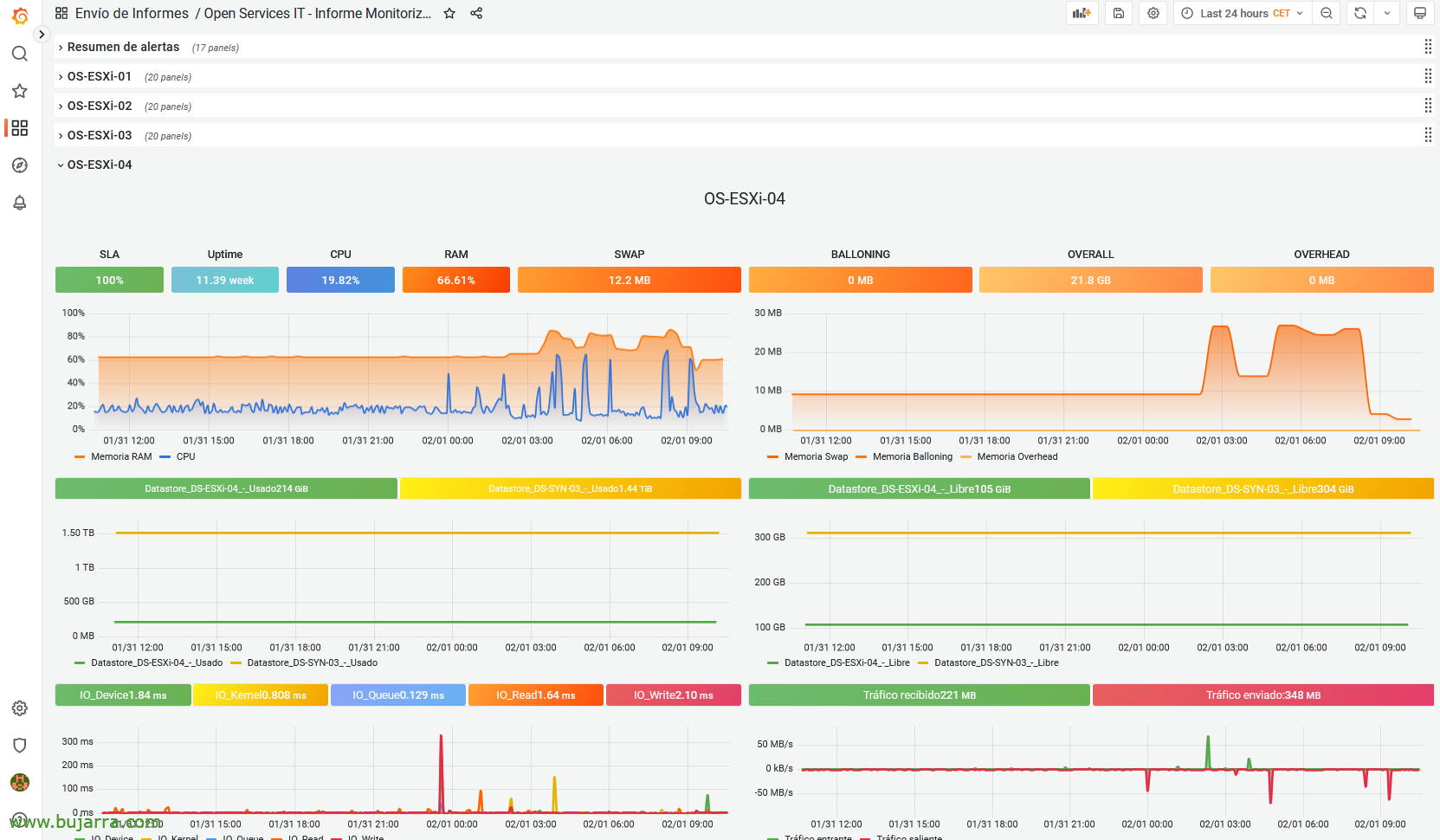
Et si vous avez Grafana et que vous voyez des données de surveillance, nous pouvons calculer le SLA en fonction de la période de temps du graphique, pour cela, Si vous regardez, il y a un panneau où vous voyez le SLA.
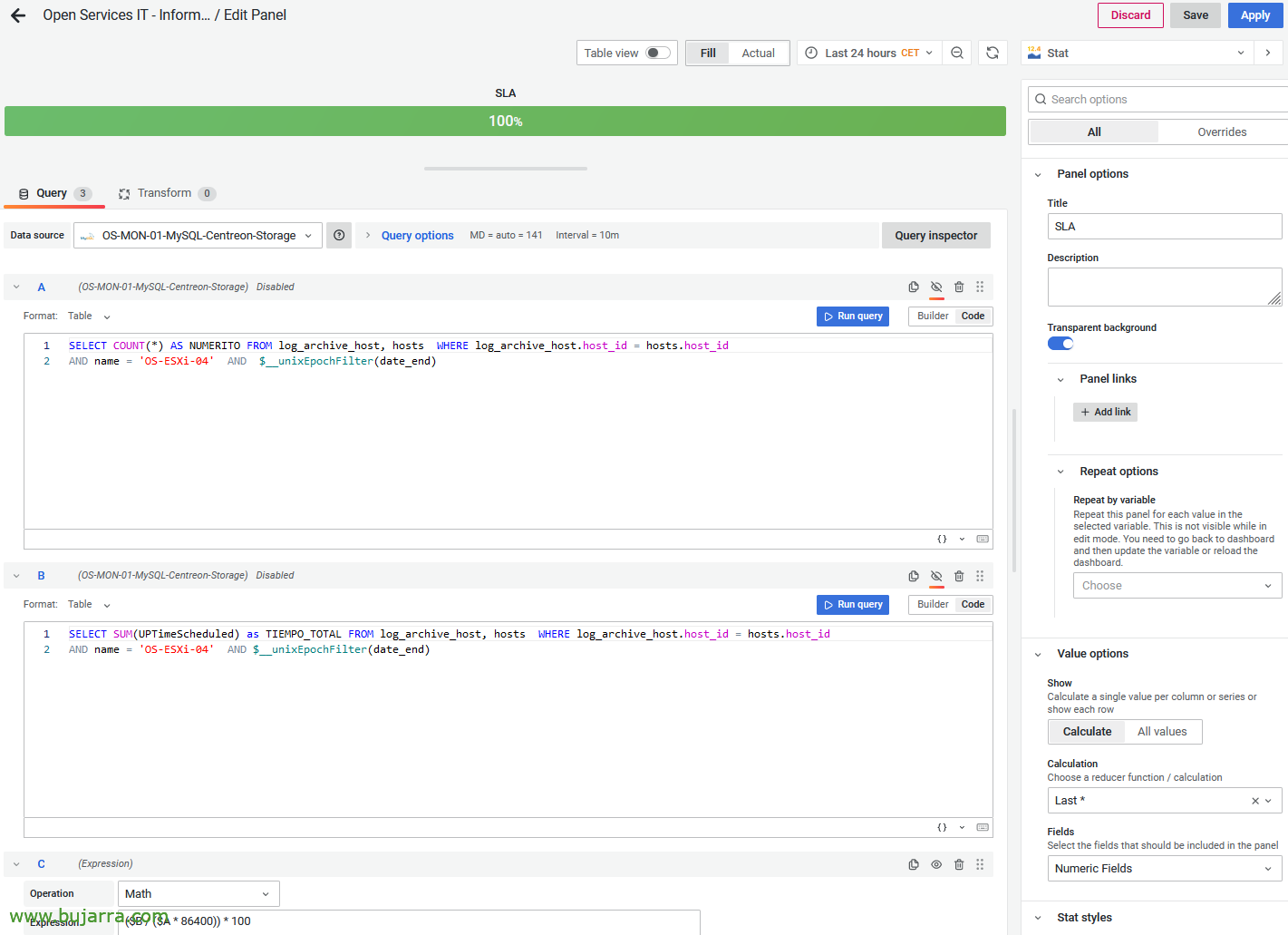
Si nous modifions le panneau 'statistiques', Je calcule le SLA en l’obtenant auprès de 2 Consultations, Le premier obtiendra les jours de la requête (basé sur ce qui est sélectionné dans Grafana, 24h, 1 mois…); et le second obtient en quelques secondes combien de temps l’ordinateur est en état OK. Si vous regardez les deux requêtes, elles sont cachées, et il y a une troisième requête qui est de type mathématique et qui obtient le % Sur la base de ces deux valeurs. Je vous laisse le 2 Requêtes utilisées:
SÉLECTIONNEZ COMPTER(*) COMME NUMERITO DE log_archive_host, hosts WHERE log_archive_host.host_id = hosts.host_id AND name = 'NOMBRE_DE_HOST' ET $__unixEpochFilter(date_end)
SÉLECTIONNEZ SOMME(UPTimeProgrammé) COMME TIEMPO_TOTAL DE log_archive_host, hosts WHERE log_archive_host.host_id = hosts.host_id AND name = 'NOMBRE_DE_HOST' ET $__unixEpochFilter(date_end)
($B / ($À * 86400)) * 100
De cette façon, nous serons en mesure de voir et de démontrer le SLA que nous respectons pour chaque machine qui offre des services dans notre organisation, Je vous rappelle qu’avant de mettre un lien pour mesurer le SLA des services, qui, en fonction de ce dont nous avons besoin, serait l’autre option.
J’espère comme toujours que ça se passe très bien, pour prendre soin de vous et je vous envoie un câlin!










