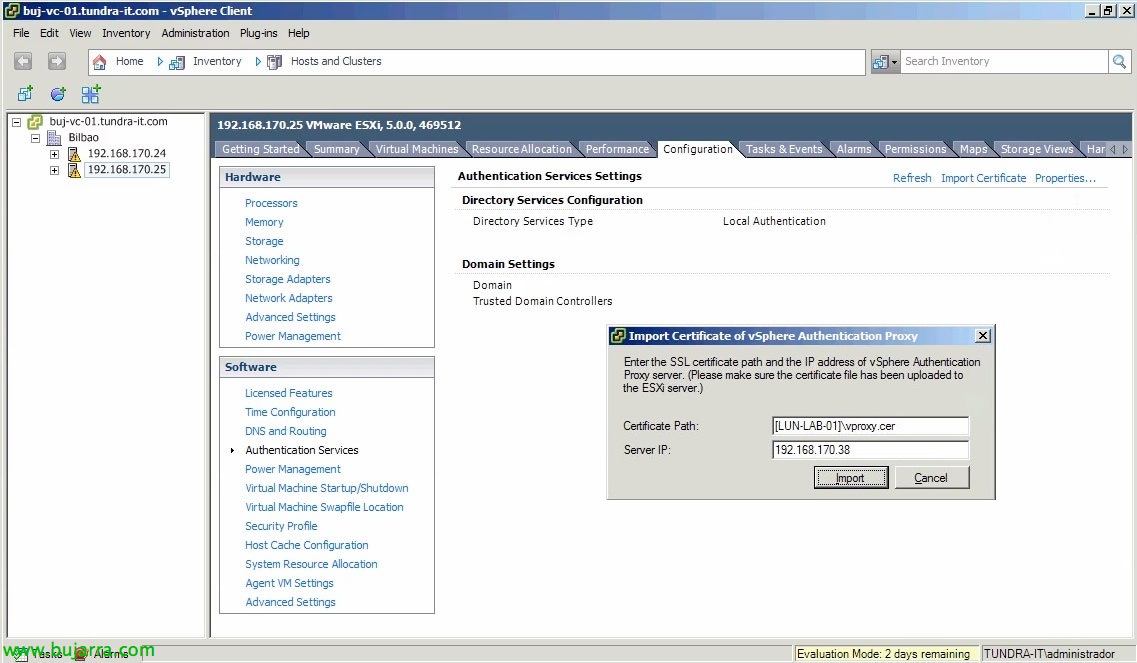
Appliance de stockage vSphere – VSA
vSphère 5 Appliance de stockage vSphere (VSA), une solution conçue pour les petites entreprises qui n’ont pas le budget nécessaire pour acheter une baie de stockage et qui souhaitent disposer d’une haute disponibilité en termes de stockage ou de fonctionnalités telles que HA ou VMotion, DRS… Grâce à cette petite appliance qui s’exécute sur chaque hôte et via le VSA Manager, nous aurons les banques de données locales répliquées entre les hôtes ESXi.