
Aktivieren der Deduplizierung in Windows 2012 Nr. R2

Eine der großen Neuerungen, die Windows Server mitbrachte, 2012 ist die Möglichkeit, den Inhalt eines Volumes zu deduplizieren, Diese sehr wichtige Technologie zur Einsparung von Speicherplatz wurde uns bisher nur von mittel- bis hochklassigen Speichersystemen geboten, Ab jetzt können wir die Festplattenkapazität auch direkt über das Betriebssystem optimieren!

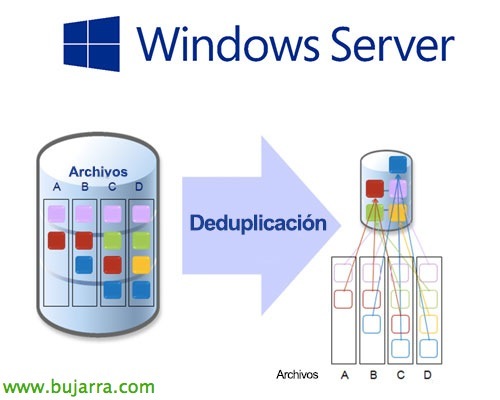
Deduplizierung besteht im Wesentlichen darin, die Daten auf der Festplatte in kleine Blöcke zu unterteilen, die Blöcke zu analysieren, die sich wiederholen, und Zeiger zu erstellen, indem alle wiederholten Blöcke entfernt werden, Damit können wir beim Speichern von Informationen erhebliche Einsparungen erzielen, Es hängt vom gespeicherten Inhalt ab, aber je mehr ähnliche Blöcke es gibt, desto mehr sparen wir 😉
No podremos habilitar la deduplicación en volúmenes de sistema, ni de arranque, ni formateados con ReFS, ni volúmenes CSV (Cluster Shared Volumes). Deberían estar particionados como MBR o GUID y en NTFS, podrán ser volumenes locales o de una red de almacenamiento como iSCSI, FC… Disponemos de la herramienta 'DDPEval.exe’ en %WinDir%System32″ una vez hayamos instalado el rol en el servidor para no tener que forzar una deduplicación y esta herramienta nos indique cuánto liberaríamos! No se recomienda deduplicar volúmenes con BD tipo SQL Server o Exchange Server ya que se pueden corromper, en tal caso podríamos excluir sus directorios. En entornos con Hyper-V se recomienda usarlo cuando dispongamos un volumen con VHD de escritorios virtuales similares, no en toda la plataforma como tal con distintos servidores… aún así siempre se debería configurar la programación de la tarea de deduplicación cuando no coincida con cargas de trabajo o backups.

Nicht schlecht, para habilitar la deduplicación, agregaremos el rol de 'Desduplicación de datos’ dentro del rol de 'Servicios de archivos y almacenamiento'.

Später, im “Server-Administrator”, in “Servicios de archivos y de almacenamiento” > “Volumenes”, podremos sobre cada volumen con botón derecho entrar en “Configurar desduplicación de datos…”. Si nos fijamos, en este ejemplo lo realizaré sobre el volumen F: de 300Gb y que tan sólo tiene 5Gb libres.

Podremos seleccionar el tipo de deduplicación a realizar, si sobre un volumen que almacena ficheros o uno que almacena máquinas virtuales (normalmente escritorios de VDI). Indicaremos los ficheros a deduplicar, los que tengan más de X días o podremos excluir ciertas extensiones para que sean excluidos, así como seleccionar carpetas a excluir o archivos en concreto. Auswählen “Establecer programación de desduplicación…”,

Y configuramos una o dos programaciones para que analice los ficheros del volumen y realice su deduplicación!

Nicht schlecht, podremos ver el estado de la deduplicación desde PowerShell con 'get-DedupStatus', y si queremos iniciar inmediatamente el trabajo que acabamos de programar de deduplicación bastará con ejecutar 'start-DedupJob DISCO: -type optimization'.

Podremos ir verificando el estado del trabajo con 'get-DedupJob’ donde podremos ver el % avanzado, Um den Status der Deduplizierung im Volume erneut zu sehen, verwenden wir ‚get-DedupStatus‘, wir werden überprüfen, wie viel wir optimieren!!

Oder wir können visuell, zurückkehren zu “Server-Administrator” und die Volumes aktualisieren, bei diesem konkreten hatten wir vorher 5 GB frei und jetzt 146 GB! Wenn wir aus irgendeinem Grund zum Ursprung zurückkehren und den kürzlich optimierten Inhalt deduplizierungsfrei machen wollten, führen wir ‚start-DedupJob DISK: -type Unoptimization‘ aus.










