
Enabling deduplication in Windows 2012 R2

One of the great novelties brought by Windows Server 2012 is the ability to deduplicate the contents of a volume, This very important disk saving technology was given to us until now by medium/high-end storage arrays, from now on we can also optimize disk space from the OS itself!

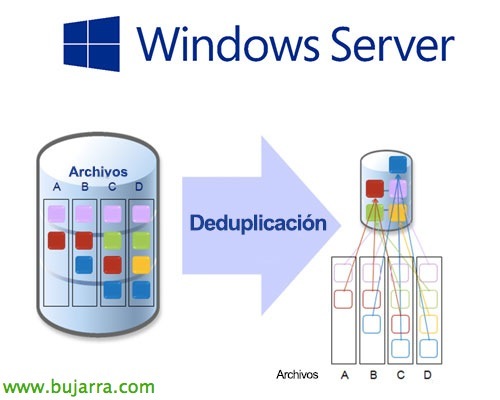
Deduplication basically consists of separating the data on the hard drive into small blocks, Analyze repeating blocks, and create pointers by removing all repeated blocks, With this we can have a very significant saving when it comes to storing information, will depend on the stored content, But the more similar blocks the more we will 😉 save
We won't be able to enable deduplication on system volumes, Not even from the start, or formatted with ReFS, or CSV volumes (Cluster Shared Volumes). They should be partitioned as MBR or GUID and in NTFS, they can be local volumes or from a storage network such as iSCSI, FC… We have the tool 'DDPEval.exe’ in %WinDir%System32″ Once we have installed the role on the server so that we do not have to force a deduplication and this tool tells us how much we would free up! It is not recommended to deduplicate volumes with SQL Server or Exchange Server databases as they can become corrupted, in this case we may exclude your directories. In environments with Hyper-V, it is recommended to use it when we have a volume with VHDs of similar virtual desktops, not on the entire platform as such with different servers… however, you should always configure the deduplication task schedule when it does not match workloads or backups.

GOOD, To enable deduplication, we will add the role of 'Data Deduplication'’ within the 'File and Storage Services' role.

Subsequently, in the “Server Administrator”, in “File and storage services” > “Volumes”, we can on each volume with right click enter “Configure Data Deduplication…”. If we look at, in this example I will do it on volume F: and that only has 5Gb free.

We will be able to select the type of deduplication to be carried out, whether on a volume that stores files or one that stores virtual machines (typically VDI desktops). We will indicate the files to be deduplicated, those who are more than X days old or we may exclude certain extensions from being excluded, as well as select folders to exclude or specific files. Select “Set deduplication schedule…”,

And we set up one or two schedules to analyze the files on the volume and perform their deduplication!

GOOD, we will be able to see the status of the deduplication from PowerShell with 'get-DedupStatus', and if we want to immediately start the deduplication work that we have just programmed it will be enough to execute 'start-DedupJob DISK: -type optimization'.

We can check the status of the job with 'get-DedupJob’ where we can see the % advanced, to see the deduplication status on the volume again we will do it with 'get-DedupStatus', We will verify how much we are optimizing!!

Or we can visually, back to “Server Administrator” and update volumes, in this particular one we had 5Gb free before and now 146Gb! If we wanted to go back to the source for some reason and de-deduplicate the newly optimized content we'll run 'start-DedupJob DISK: -type Unoptimization'.










